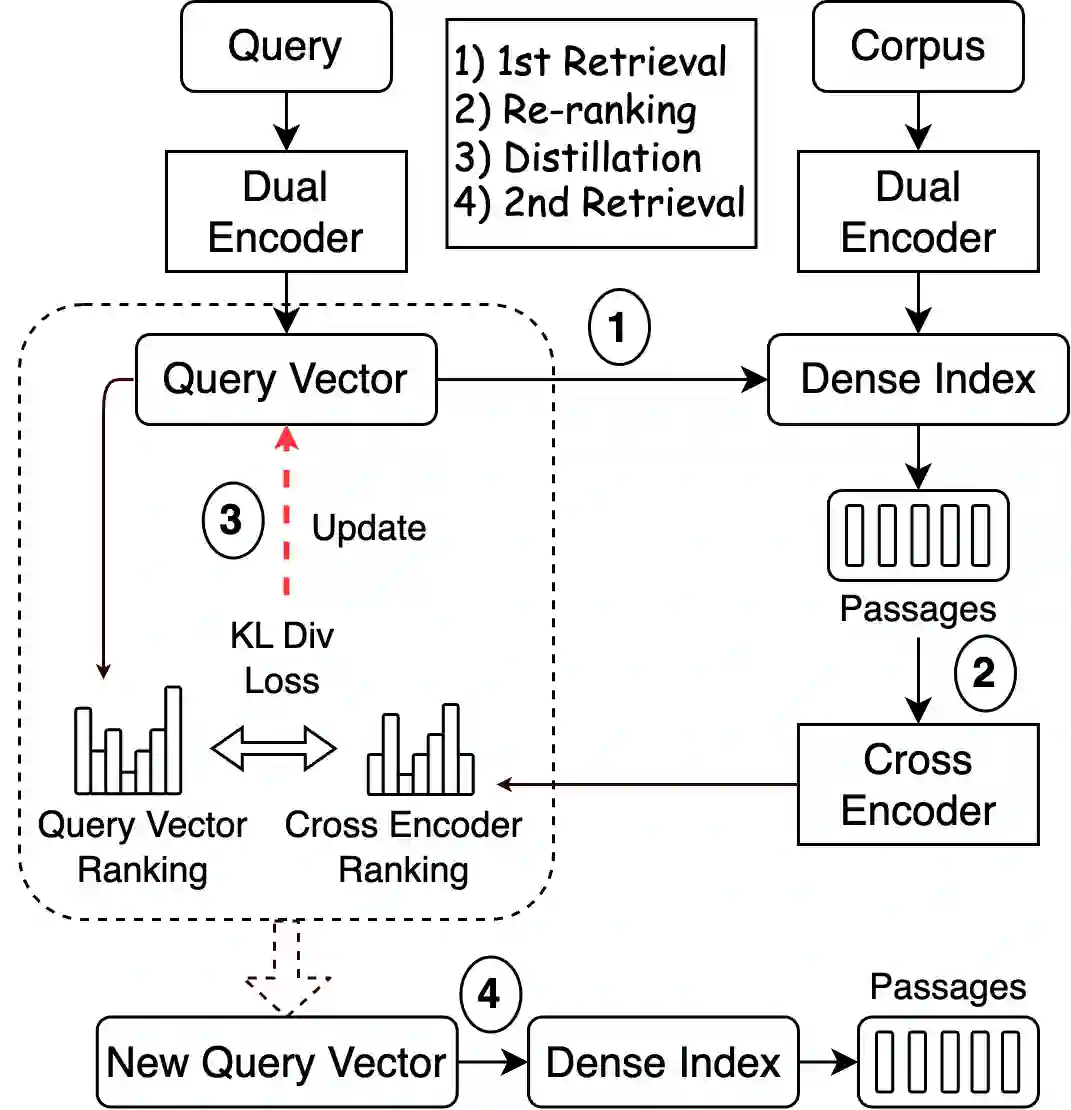
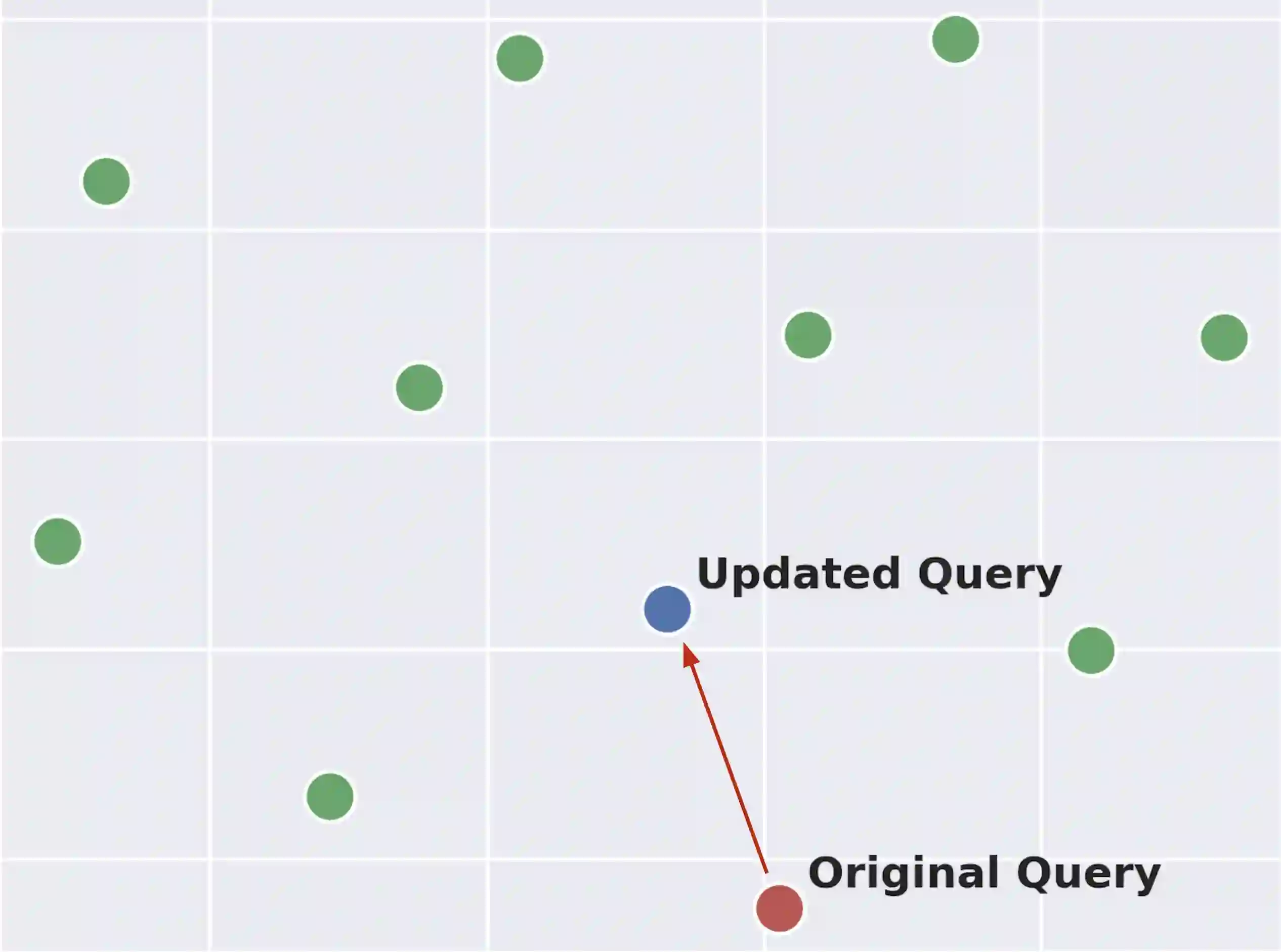
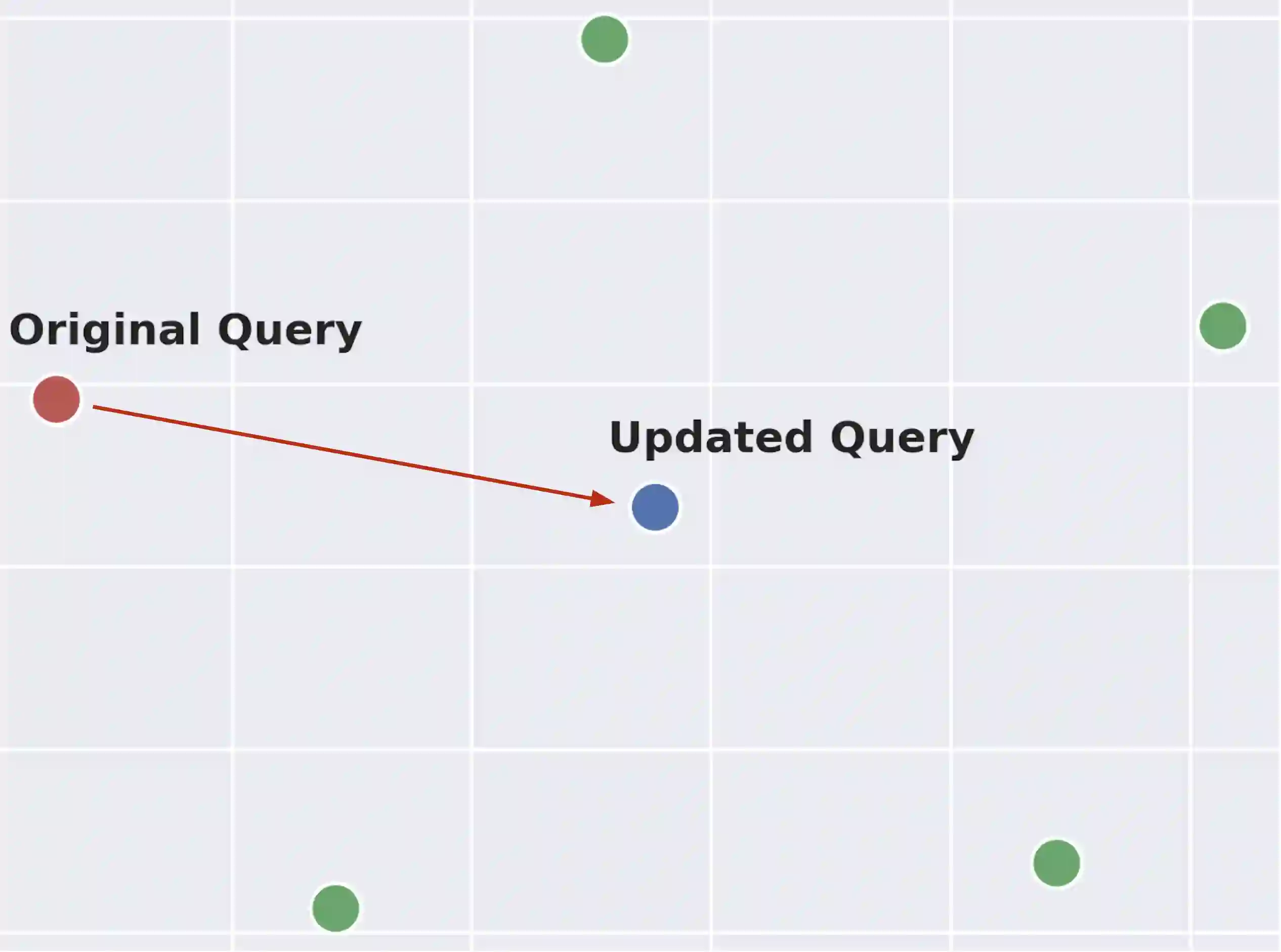
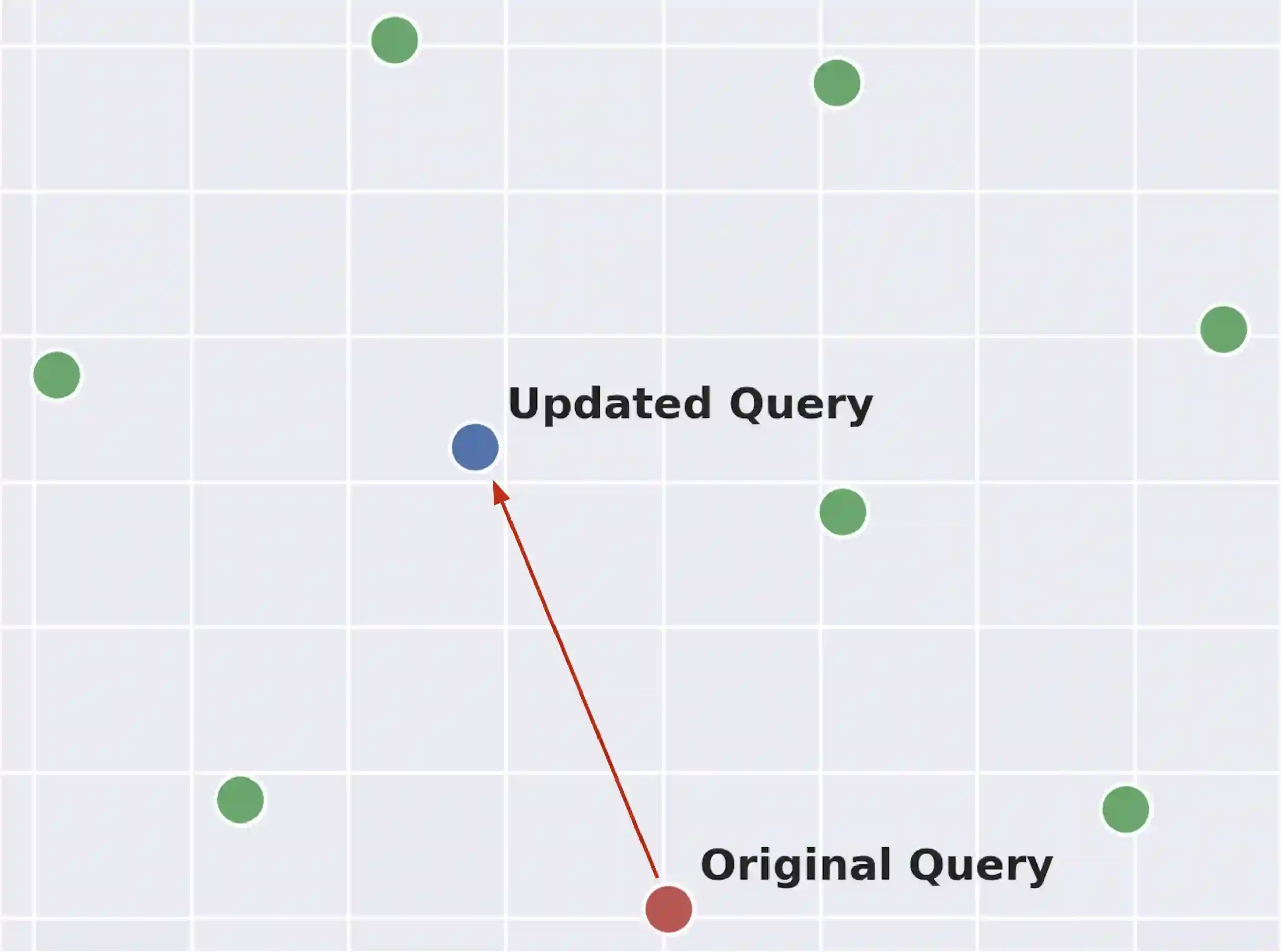
Retrieve-and-rerank is a prevalent framework in neural information retrieval, wherein a bi-encoder network initially retrieves a pre-defined number of candidates (e.g., K=100), which are then reranked by a more powerful cross-encoder model. While the reranker often yields improved candidate scores compared to the retriever, its scope is confined to only the top K retrieved candidates. As a result, the reranker cannot improve retrieval performance in terms of Recall@K. In this work, we propose to leverage the reranker to improve recall by making it provide relevance feedback to the retriever at inference time. Specifically, given a test instance during inference, we distill the reranker's predictions for that instance into the retriever's query representation using a lightweight update mechanism. The aim of the distillation loss is to align the retriever's candidate scores more closely with those produced by the reranker. The algorithm then proceeds by executing a second retrieval step using the updated query vector. We empirically demonstrate that this method, applicable to various retrieve-and-rerank frameworks, substantially enhances retrieval recall across multiple domains, languages, and modalities.
翻译:检索-重排序是神经信息检索中的一种主流框架,其中双编码器网络首先检索出预定数量的候选结果(例如K=100),随后由更强大的交叉编码器模型进行重排序。尽管重排序器相比检索器通常能获得更优的候选结果评分,但其作用范围仅限于前K个检索结果。因此,重排序器无法在Recall@K指标上提升检索性能。本研究提出一种在推理阶段利用重排序器向检索器提供相关性反馈以提升召回率的方法。具体而言,在推理过程中给定测试实例时,我们通过轻量级更新机制将重排序器对该实例的预测结果蒸馏到检索器的查询表示中。蒸馏损失的目标是使检索器的候选评分与重排序器生成的评分更趋一致。算法随后使用更新后的查询向量执行第二次检索步骤。我们通过实证研究表明,这种适用于多种检索-重排序框架的方法,能够在跨领域、跨语言和跨模态场景中显著提升检索召回率。