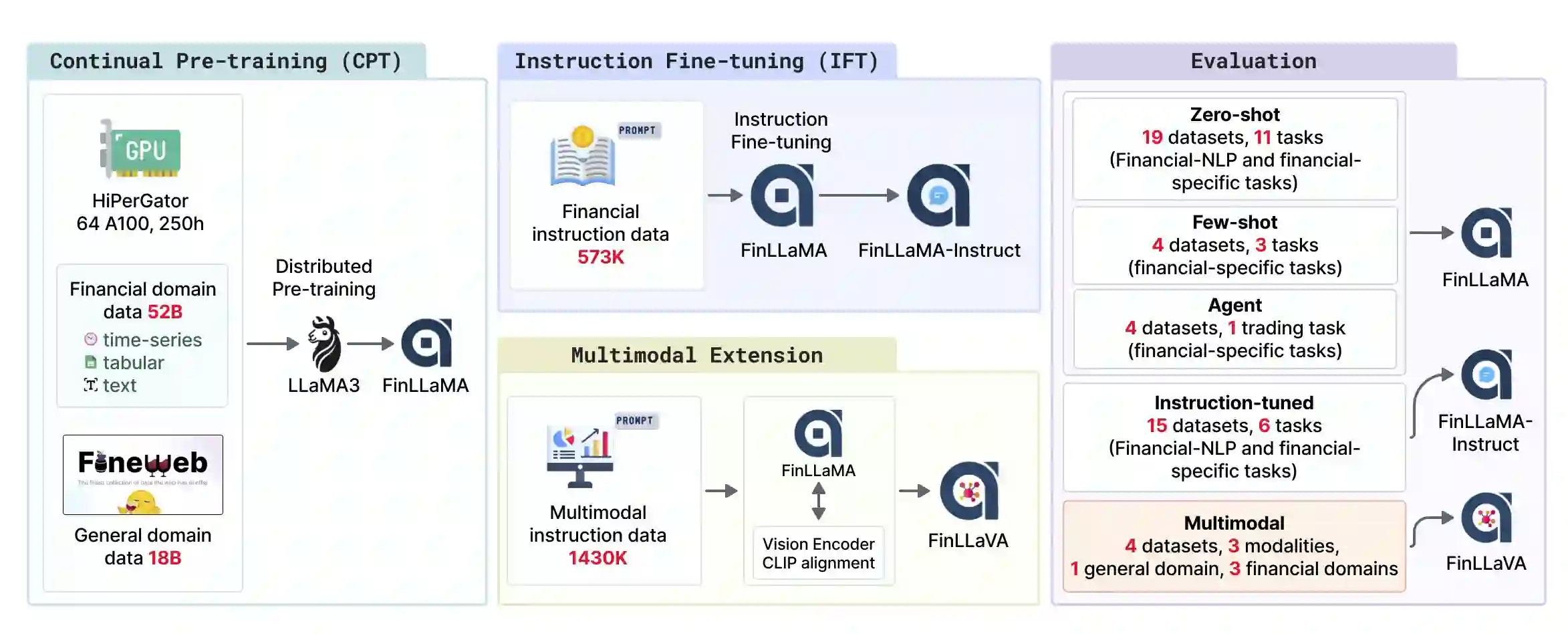
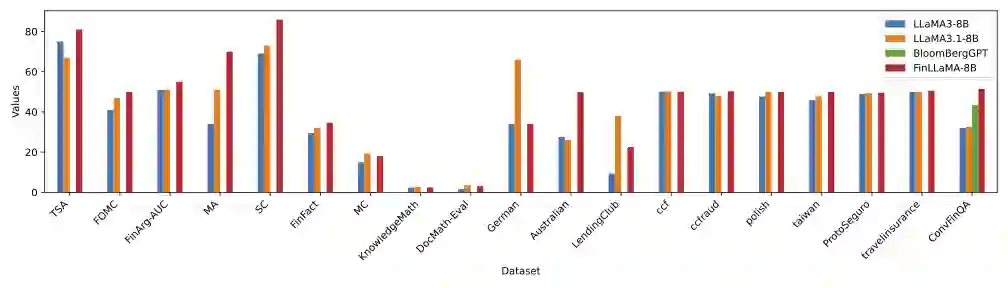
Financial LLMs hold promise for advancing financial tasks and domain-specific applications. However, they are limited by scarce corpora, weak multimodal capabilities, and narrow evaluations, making them less suited for real-world application. To address this, we introduce \textit{Open-FinLLMs}, the first open-source multimodal financial LLMs designed to handle diverse tasks across text, tabular, time-series, and chart data, excelling in zero-shot, few-shot, and fine-tuning settings. The suite includes FinLLaMA, pre-trained on a comprehensive 52-billion-token corpus; FinLLaMA-Instruct, fine-tuned with 573K financial instructions; and FinLLaVA, enhanced with 1.43M multimodal tuning pairs for strong cross-modal reasoning. We comprehensively evaluate Open-FinLLMs across 14 financial tasks, 30 datasets, and 4 multimodal tasks in zero-shot, few-shot, and supervised fine-tuning settings, introducing two new multimodal evaluation datasets. Our results show that Open-FinLLMs outperforms afvanced financial and general LLMs such as GPT-4, across financial NLP, decision-making, and multi-modal tasks, highlighting their potential to tackle real-world challenges. To foster innovation and collaboration across academia and industry, we release all codes (https://anonymous.4open.science/r/PIXIU2-0D70/B1D7/LICENSE) and models under OSI-approved licenses.
翻译:金融大语言模型在推进金融任务和领域特定应用方面前景广阔。然而,它们受限于稀缺的语料库、薄弱的多模态能力以及狭窄的评估范围,使其不太适合实际应用。为解决这些问题,我们推出了 \textit{Open-FinLLMs},这是首个开源的多模态金融大语言模型,旨在处理文本、表格、时间序列和图表数据等多种任务,并在零样本、少样本和微调设置下表现优异。该套件包括:基于全面 520 亿词元语料库预训练的 FinLLaMA;通过 573K 条金融指令微调的 FinLLaMA-Instruct;以及通过 143 万对多模态调优数据增强、具备强大跨模态推理能力的 FinLLaVA。我们在零样本、少样本和有监督微调设置下,对 Open-FinLLMs 在 14 项金融任务、30 个数据集和 4 项多模态任务上进行了全面评估,并引入了两个新的多模态评估数据集。我们的结果表明,Open-FinLLMs 在金融自然语言处理、决策制定和多模态任务上均优于 GPT-4 等先进的金融及通用大语言模型,凸显了其应对现实世界挑战的潜力。为促进学术界和工业界的创新与合作,我们依据 OSI 批准的许可证发布了所有代码(https://anonymous.4open.science/r/PIXIU2-0D70/B1D7/LICENSE)和模型。