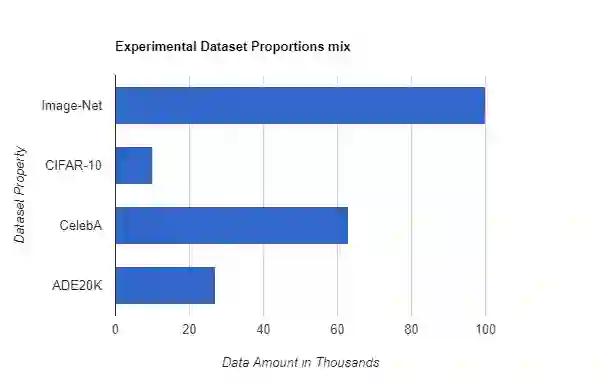
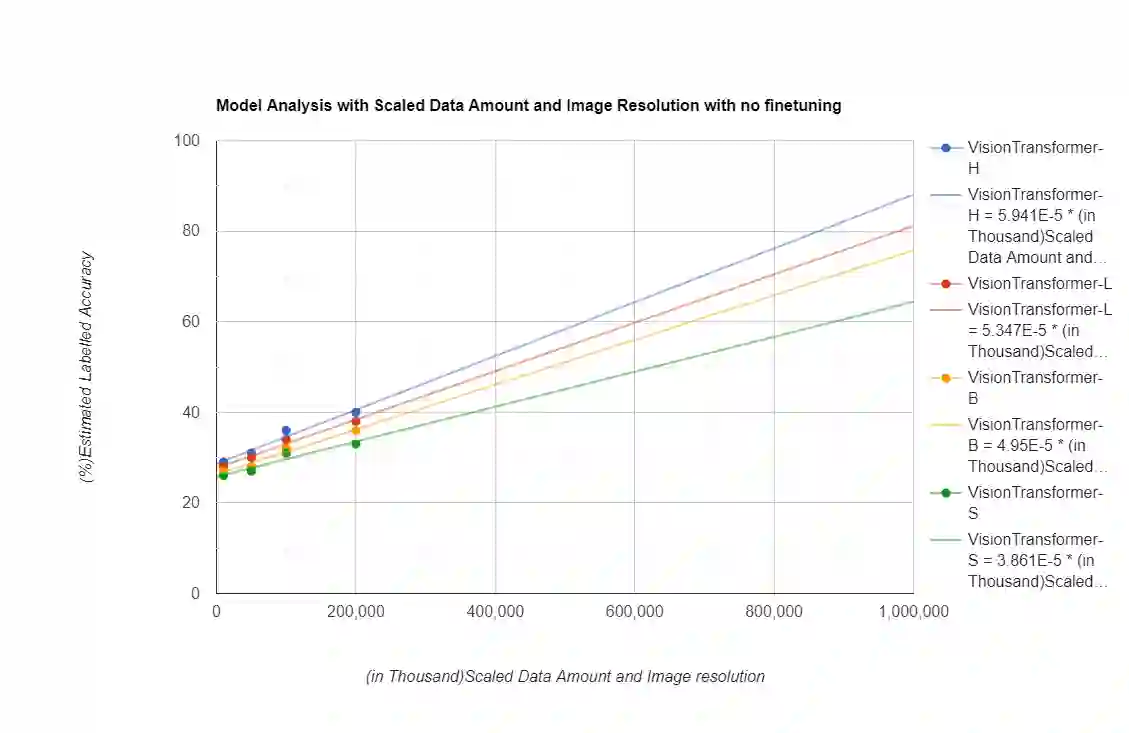
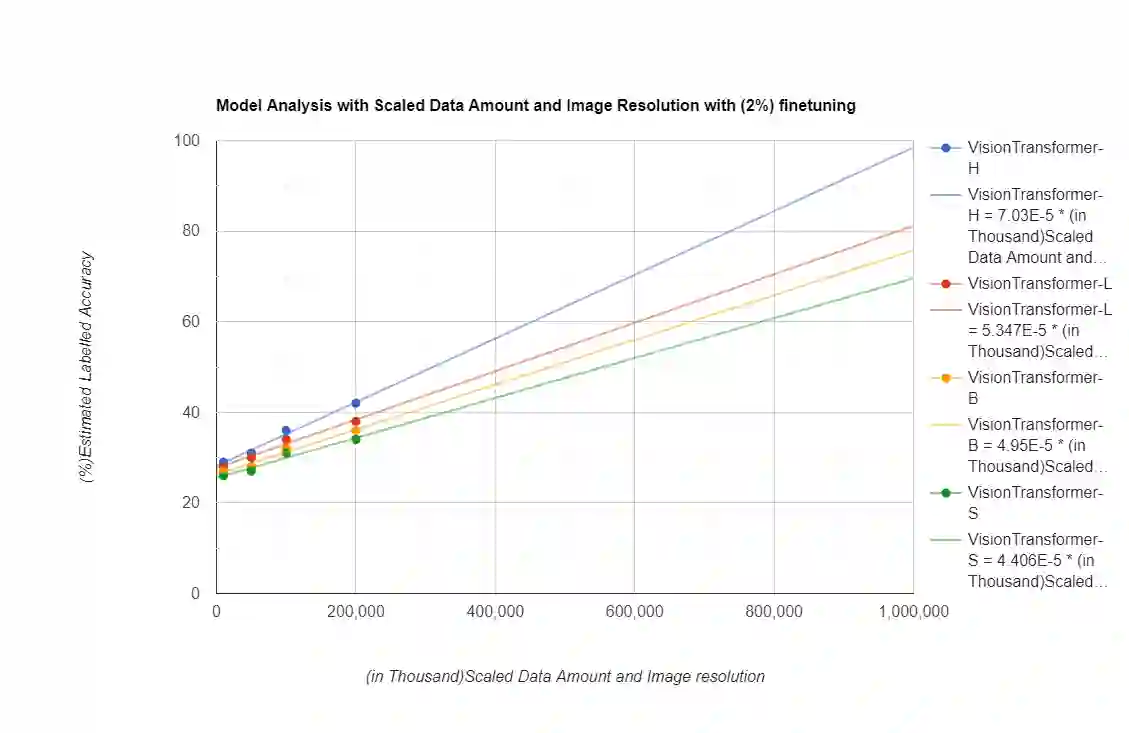
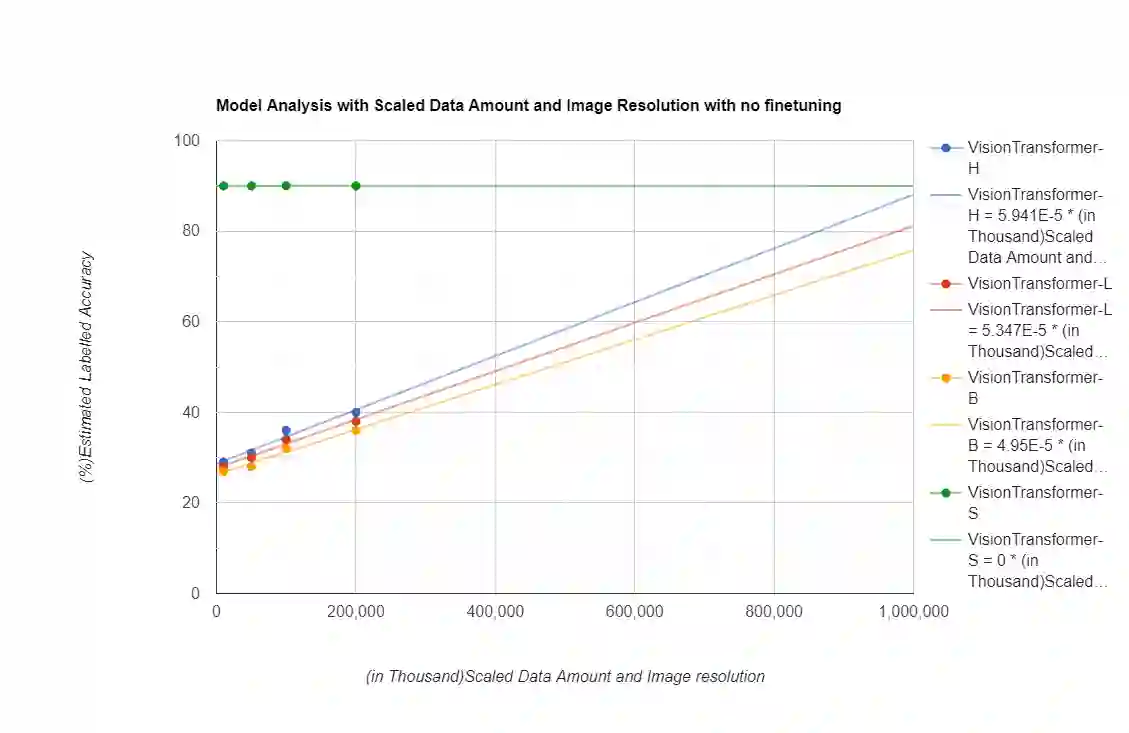
The purpose of the research is to determine if currently available self-supervised learning techniques can accomplish human level comprehension of visual images using the same degree and amount of sensory input that people acquire from. Initial research on this topic solely considered data volume scaling. Here, we scale both the volume of data and the quality of the image. This scaling experiment is a self-supervised learning method that may be done without any outside financing. We find that scaling up data volume and picture resolution at the same time enables human-level item detection performance at sub-human sizes.We run a scaling experiment with vision transformers trained on up to 200000 images up to 256 ppi.
翻译:本研究的目的是确定当前可用的自监督学习技术是否能够利用与人类相同程度和数量的感官输入,达到人类水平的视觉图像理解能力。关于该主题的初步研究仅考虑了数据量的缩放。在此,我们同时缩放数据量和图像质量。该缩放实验采用自监督学习方法,可在无需任何外部资助的情况下进行。我们发现,同时提升数据量和图像分辨率,能够在亚人类尺寸上实现人类水平的物体检测性能。我们使用基于视觉变换器(Vision Transformer)的模型进行了缩放实验,训练数据规模达20万张图像,分辨率最高为256 ppi。