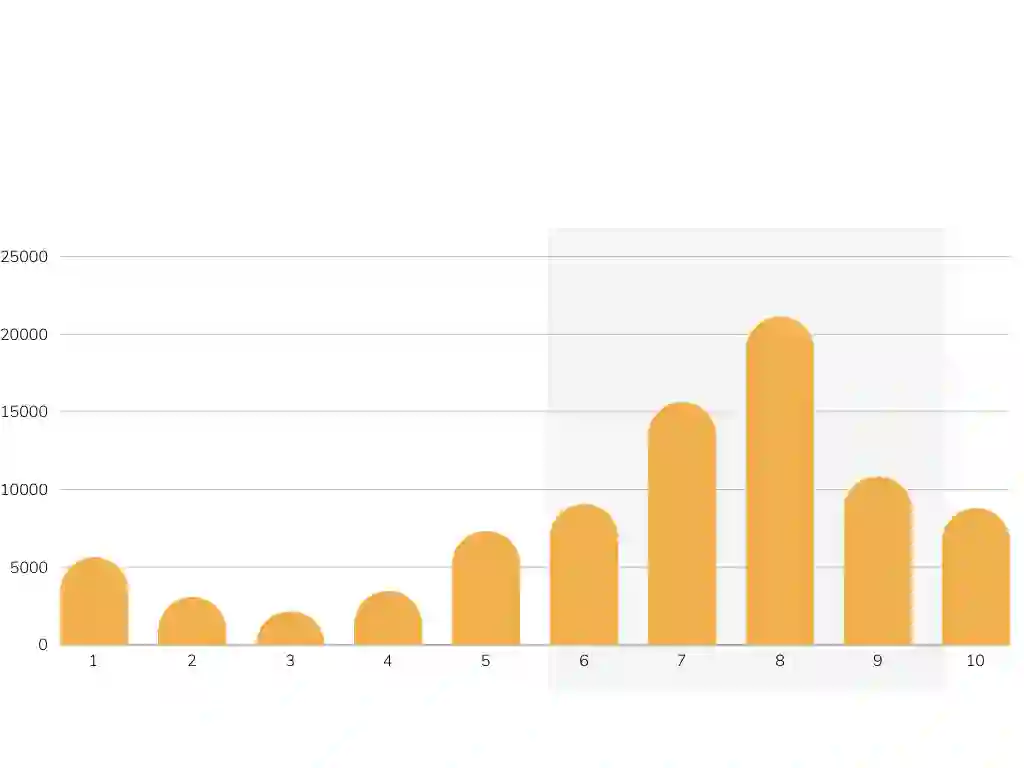
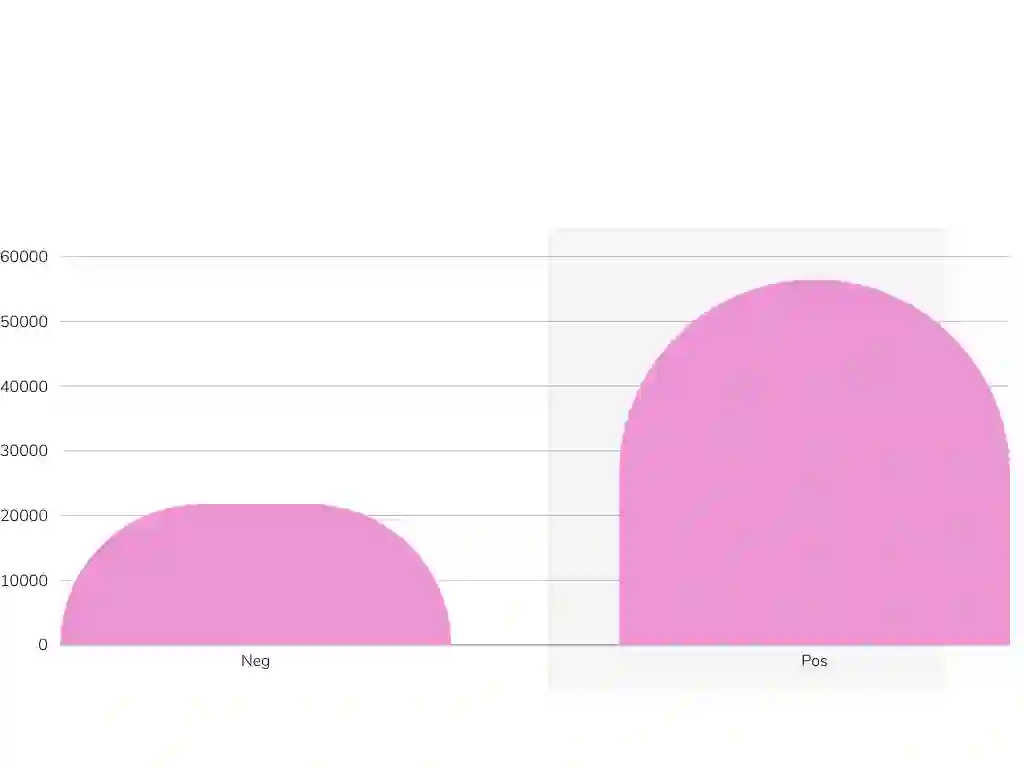
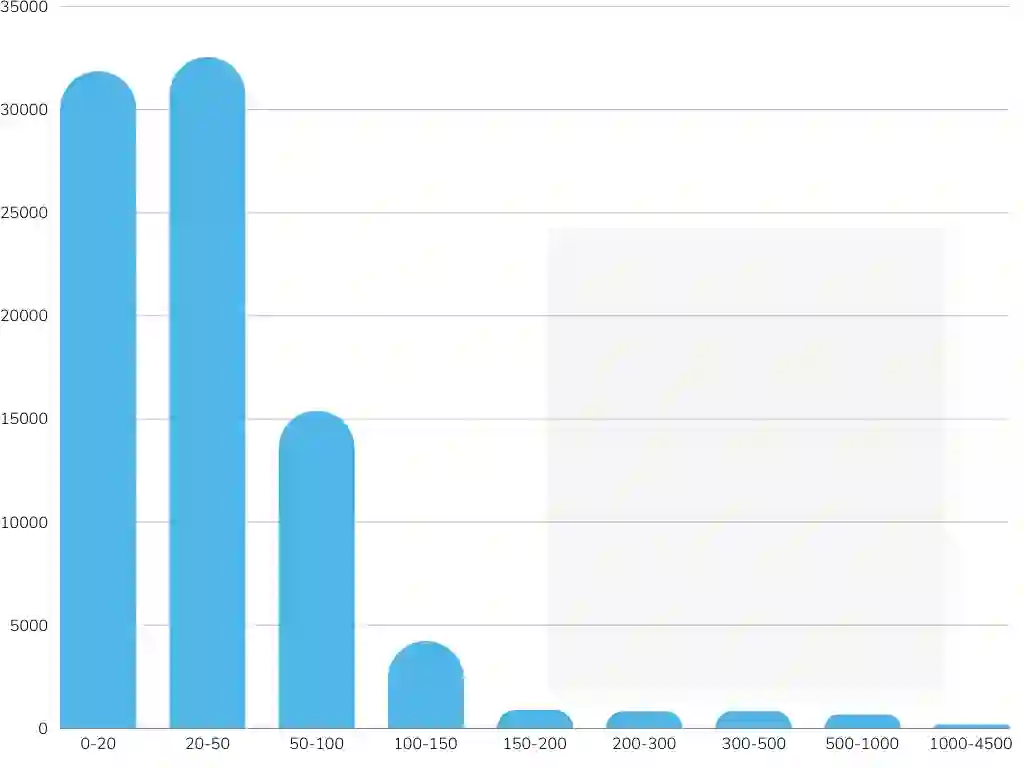
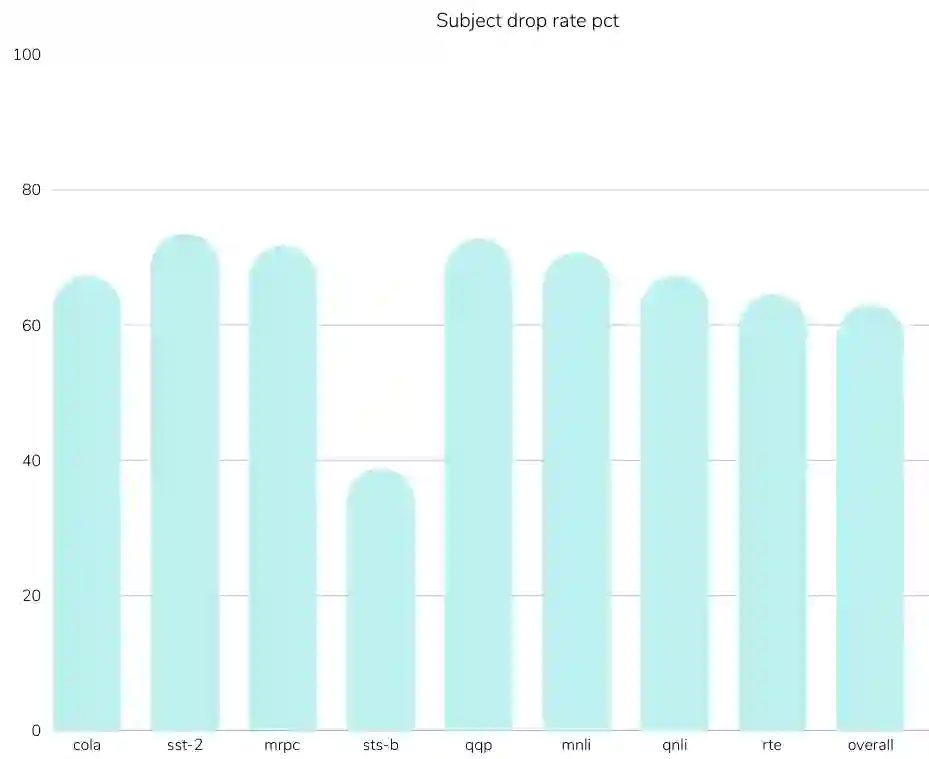
Evaluating the performance of various model architectures, such as transformers, large language models (LLMs), and other NLP systems, requires comprehensive benchmarks that measure performance across multiple dimensions. Among these, the evaluation of natural language understanding (NLU) is particularly critical as it serves as a fundamental criterion for assessing model capabilities. Thus, it is essential to establish benchmarks that enable thorough evaluation and analysis of NLU abilities from diverse perspectives. While the GLUE benchmark has set a standard for evaluating English NLU, similar benchmarks have been developed for other languages, such as CLUE for Chinese, FLUE for French, and JGLUE for Japanese. However, no comparable benchmark currently exists for the Turkish language. To address this gap, we introduce TrGLUE, a comprehensive benchmark encompassing a variety of NLU tasks for Turkish. In addition, we present SentiTurca, a specialized benchmark for sentiment analysis. To support researchers, we also provide fine-tuning and evaluation code for transformer-based models, facilitating the effective use of these benchmarks. TrGLUE comprises Turkish-native corpora curated to mirror the domains and task formulations of GLUE-style evaluations, with labels obtained through a semi-automated pipeline that combines strong LLM-based annotation, cross-model agreement checks, and subsequent human validation. This design prioritizes linguistic naturalness, minimizes direct translation artifacts, and yields a scalable, reproducible workflow. With TrGLUE, our goal is to establish a robust evaluation framework for Turkish NLU, empower researchers with valuable resources, and provide insights into generating high-quality semi-automated datasets.
翻译:评估Transformer、大语言模型(LLM)及其他自然语言处理系统的性能,需要能够从多维度衡量模型表现的综合基准。其中,自然语言理解能力的评估尤为关键,因其是衡量模型能力的根本标准。因此,建立能够从多角度深入评估和分析NLU能力的基准至关重要。尽管GLUE基准已为英语NLU评估树立了标准,其他语言也相继开发了类似基准,如中文的CLUE、法语的FLUE和日语的JGLUE。然而,目前土耳其语尚缺乏可比的基准体系。为填补这一空白,本文提出TrGLUE——一个涵盖多种土耳其语NLU任务的综合基准。此外,我们还推出了专门用于情感分析任务的基准SentiTurca。为支持研究者,我们同步提供了基于Transformer模型的微调与评估代码,以促进这些基准的有效使用。TrGLUE包含精心构建的土耳其语原生语料库,其设计遵循GLUE式评估的领域划分与任务框架,标签通过半自动化流程获取:该流程融合了基于强LLM的自动标注、跨模型一致性校验及后续人工验证。这一设计优先保证语言自然度,最大限度减少直接翻译带来的伪影,并形成了可扩展、可复现的工作流程。通过TrGLUE,我们旨在为土耳其语NLU建立坚实的评估框架,为研究者提供宝贵资源,并为生成高质量半自动化数据集的方法提供实践洞见。