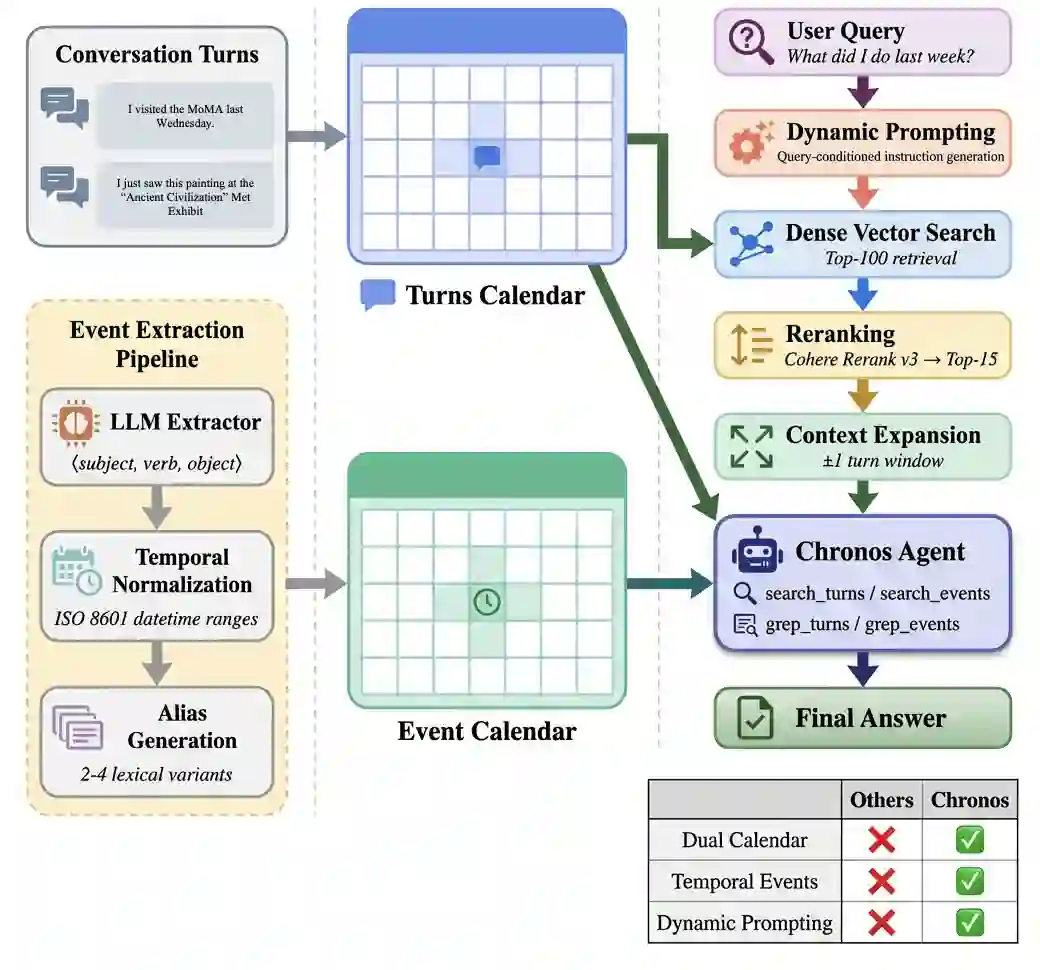
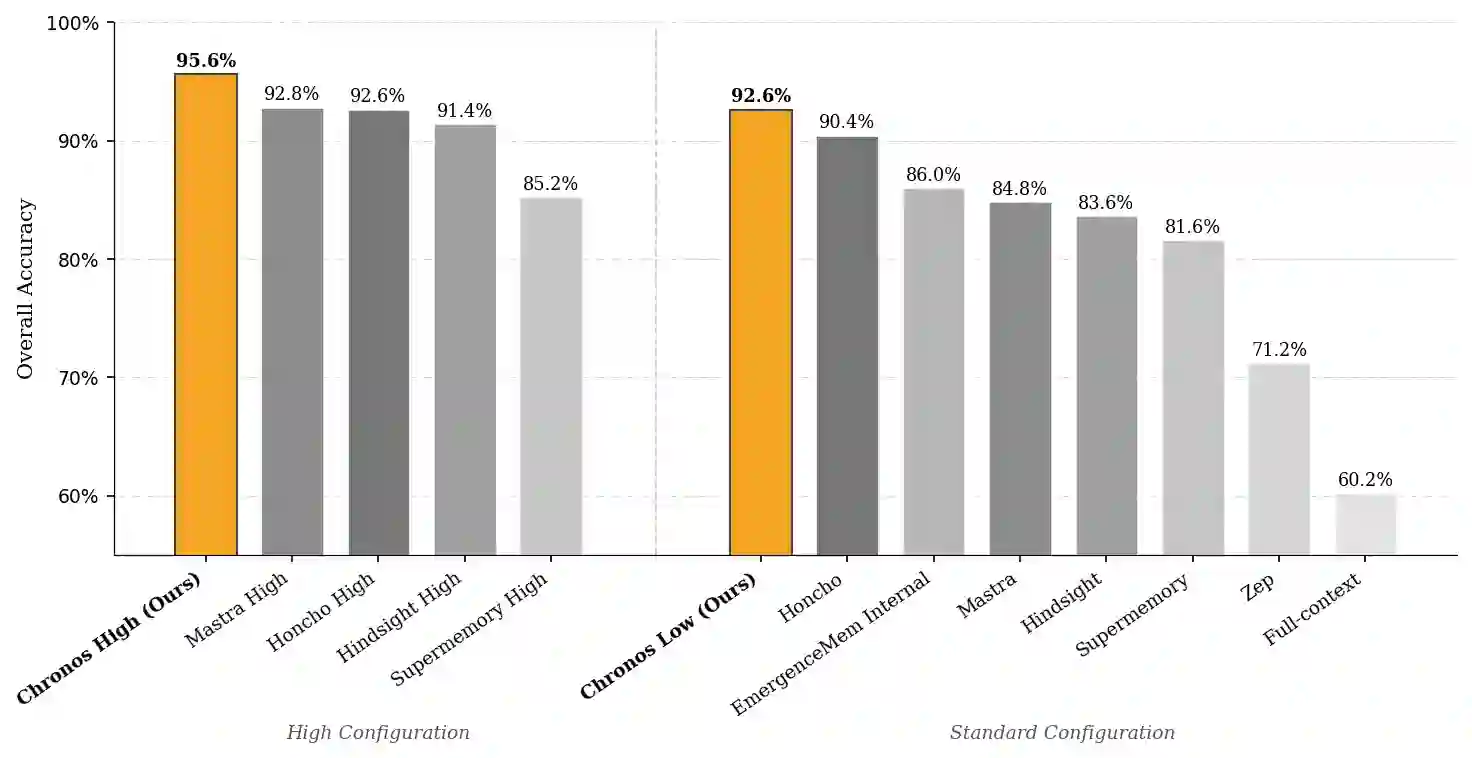
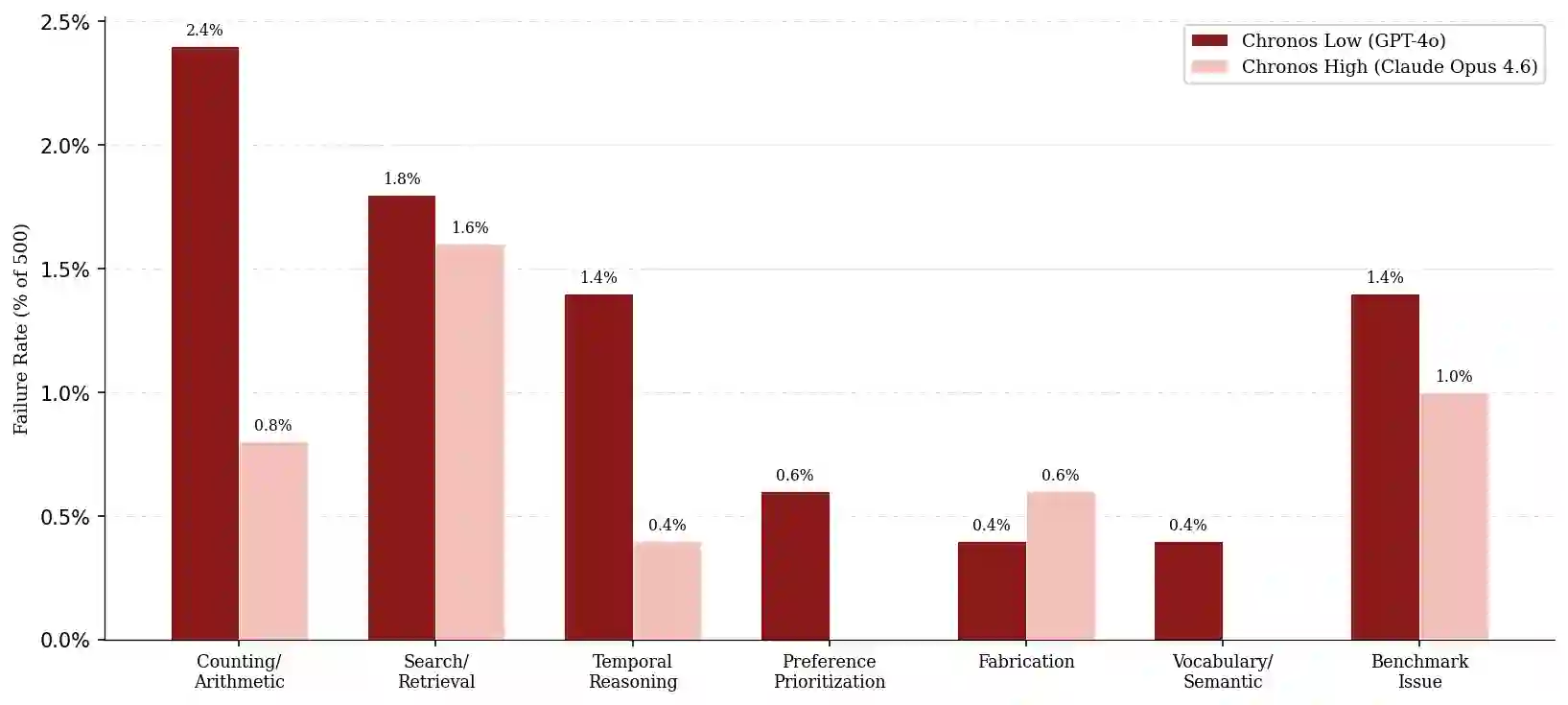
Recent advances in Large Language Models (LLMs) have enabled conversational AI agents to engage in extended multi-turn interactions spanning weeks or months. However, existing memory systems struggle to reason over temporally grounded facts and preferences that evolve across months of interaction and lack effective retrieval strategies for multi-hop, time-sensitive queries over long dialogue histories. We introduce Chronos, a novel temporal-aware memory framework that decomposes raw dialogue into subject-verb-object event tuples with resolved datetime ranges and entity aliases, indexing them in a structured event calendar alongside a turn calendar that preserves full conversational context. At query time, Chronos applies dynamic prompting to generate tailored retrieval guidance for each question, directing the agent on what to retrieve, how to filter across time ranges, and how to approach multi-hop reasoning through an iterative tool-calling loop over both calendars. We evaluate Chronos with 8 LLMs, both open-source and closed-source, on the LongMemEvalS benchmark comprising 500 questions spanning six categories of dialogue history tasks. Chronos Low achieves 92.60% and Chronos High scores 95.60% accuracy, setting a new state of the art with an improvement of 7.67% over the best prior system. Ablation results reveal the events calendar accounts for a 58.9% gain on the baseline while all other components yield improvements between 15.5% and 22.3%. Notably, Chronos Low alone surpasses prior approaches evaluated under their strongest model configurations.
翻译:近年来,大型语言模型(LLMs)的进展使得对话式AI智能体能够进行持续数周或数月的多轮交互。然而,现有的记忆系统难以对跨越数月交互过程中、基于时间的事实和不断演变的偏好进行推理,并且缺乏针对长对话历史中多跳、时间敏感查询的有效检索策略。本文提出Chronos,一种新颖的时间感知记忆框架,它将原始对话分解为主语-动词-宾语事件元组,并解析出日期时间范围和实体别名,将这些信息与一个保留完整对话上下文的话轮日历一起,索引到一个结构化的事件日历中。在查询时,Chronos应用动态提示技术为每个问题生成定制的检索指导,指示智能体检索什么、如何跨时间范围进行过滤,以及如何通过对两个日历的迭代工具调用循环来处理多跳推理。我们在包含六类对话历史任务、共计500个问题的LongMemEvalS基准测试上,使用8个开源和闭源的LLM对Chronos进行了评估。Chronos Low实现了92.60%的准确率,Chronos High达到了95.60%的准确率,创造了新的最高水平,比之前的最佳系统提高了7.67%。消融实验结果表明,事件日历相对于基线带来了58.9%的性能提升,而所有其他组件则贡献了15.5%到22.3%不等的改进。值得注意的是,仅Chronos Low的性能就超过了先前方法在其最强模型配置下的评估结果。