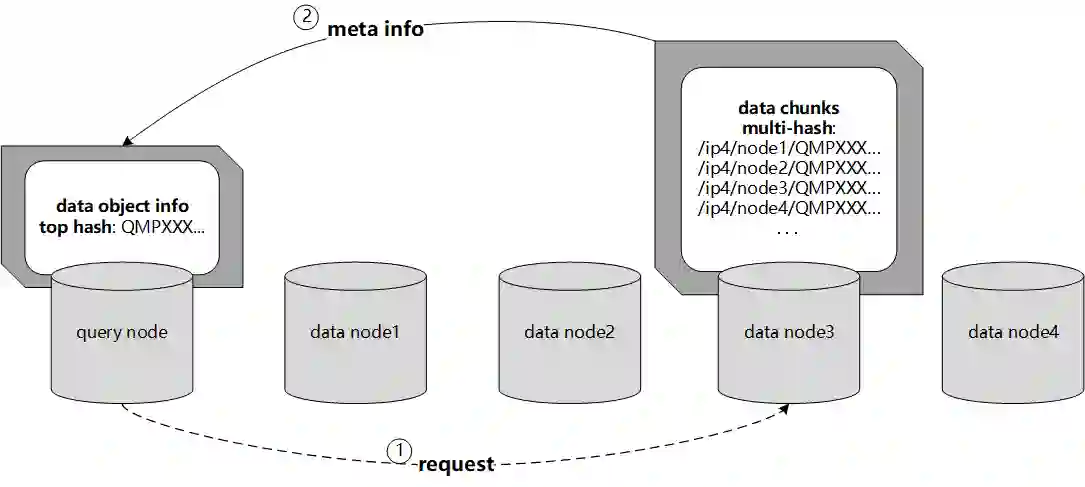
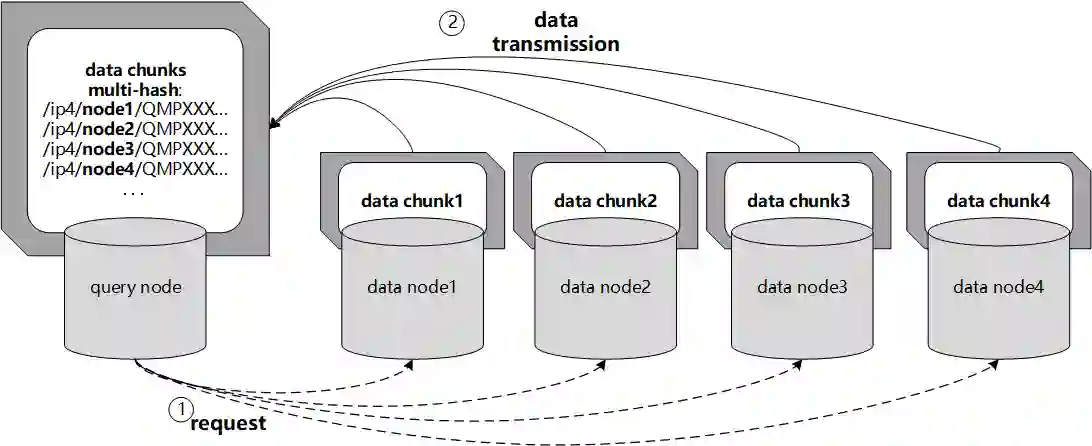
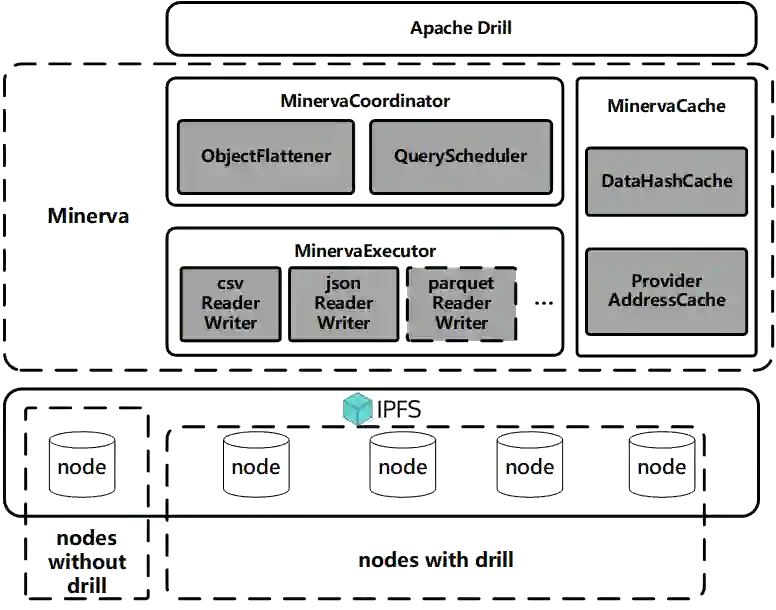
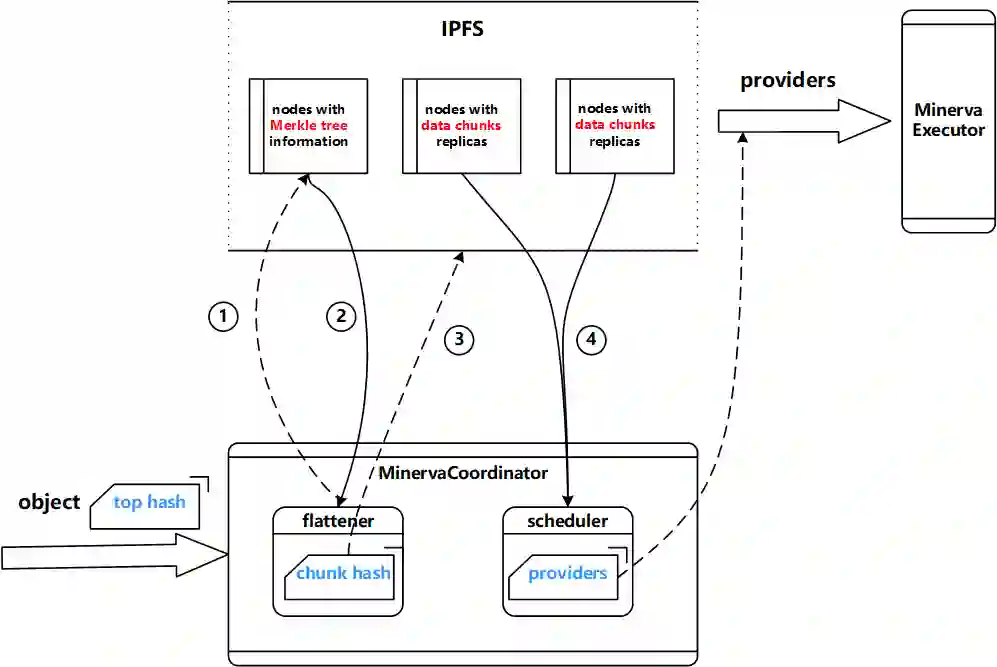
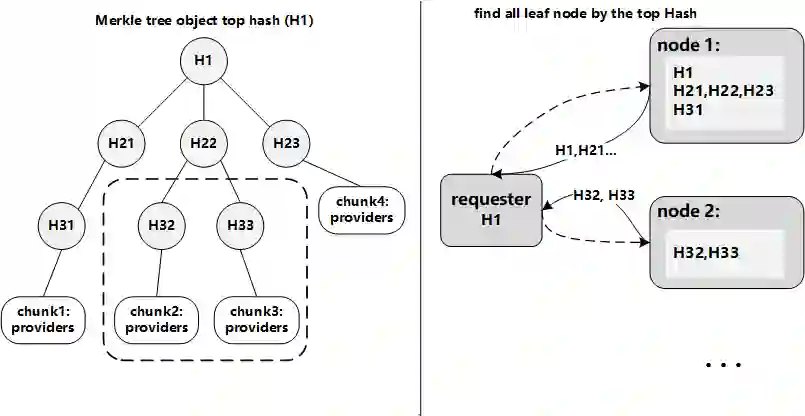
Data silos create barriers in accessing and utilizing data dispersed over networks. Directly sharing data easily suffers from the long downloading time, the single point failure and the untraceable data usage. In this paper, we present Minerva, a peer-to-peer cross-cluster data query system based on InterPlanetary File System (IPFS). Minerva makes use of the distributed Hash table (DHT) lookup to pinpoint the locations that store content chunks. We theoretically model the DHT query delay and introduce the fat Merkle tree structure as well as the DHT caching to reduce it. We design the query plan for read and write operations on top of Apache Drill that enables the collaborative query with decentralized workers. We conduct comprehensive experiments on Minerva, and the results show that Minerva achieves up to $2.08 \times$ query performance acceleration compared to the original IPFS data query, and could complete data analysis queries on the Internet-like environments within an average latency of $0.615$ second. With collaborative query, Minerva could perform up to $1.39 \times$ performance acceleration than centralized query with raw data shipment.
翻译:数据孤岛为访问和利用分散在网络中的数据造成了障碍。直接共享数据容易面临下载时间长、单点故障以及数据使用不可追溯等问题。本文提出 Minerva,一个基于星际文件系统(IPFS)的点对点跨集群数据查询系统。Minerva 利用分布式哈希表(DHT)查找来定位存储内容分块的节点。我们从理论上对 DHT 查询延迟进行建模,并引入胖梅克尔树结构以及 DHT 缓存来降低延迟。我们在 Apache Drill 之上设计了读写操作的查询计划,使去中心化的工作节点能够协同查询。我们对 Minerva 进行了全面实验,结果表明,与原始 IPFS 数据查询相比,Minerva 的查询性能加速最高达 $2.08 \times$,并且能在类似互联网的环境中完成数据分析查询,平均延迟为 $0.615$ 秒。通过协同查询,Minerva 的性能加速比使用原始数据传输的集中式查询最高可达 $1.39 \times$。