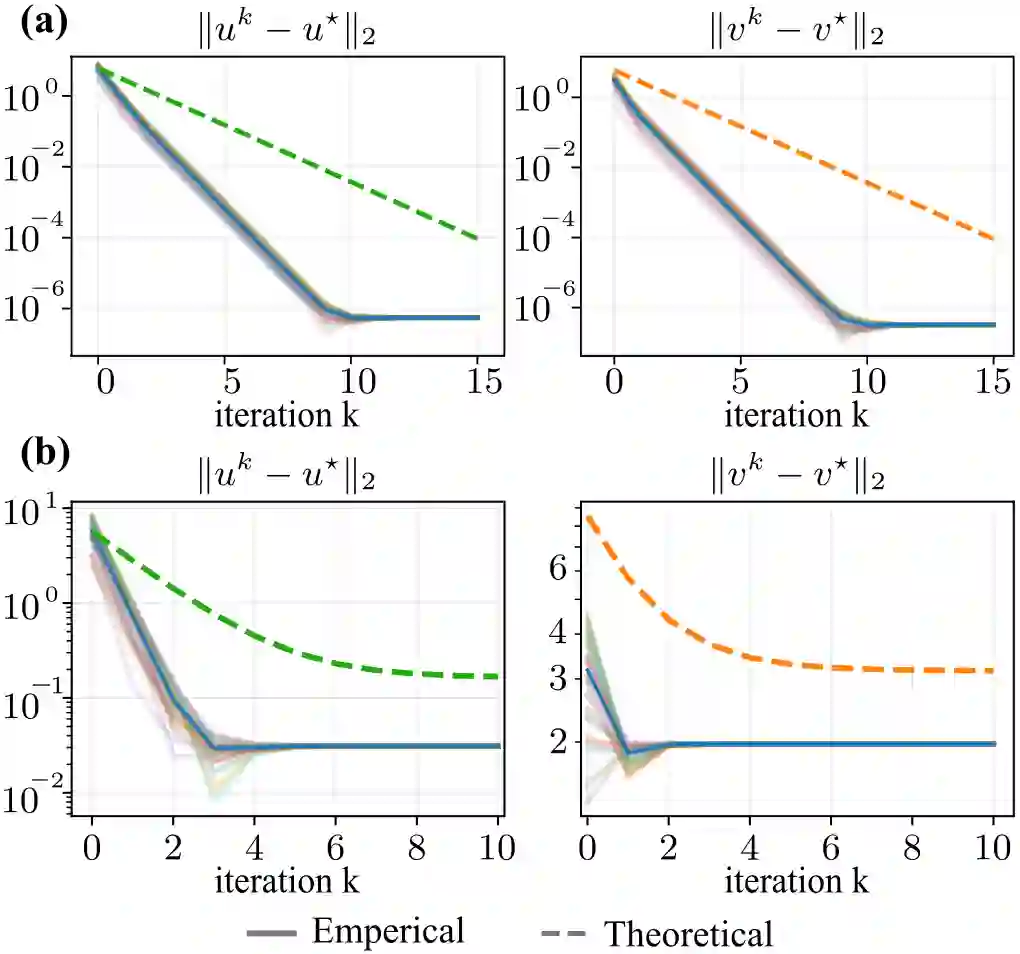
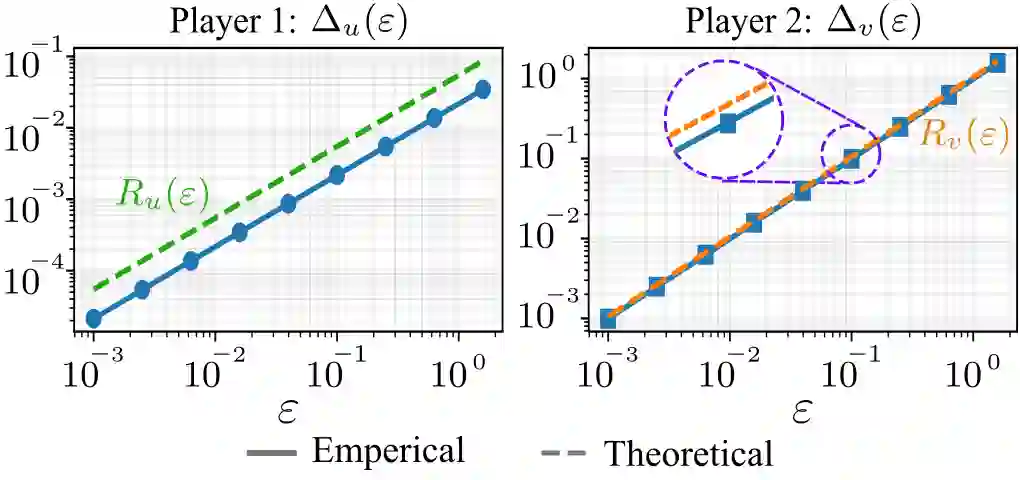
Nash equilibria provide a principled framework for modeling interactions in multi-agent decision-making and control. However, many equilibrium-seeking methods implicitly assume that each agent has access to the other agents' objectives and constraints, an assumption that is often unrealistic in practice. This letter studies a class of asymmetric-information two-player constrained games with decoupled feasible sets, in which Player 1 knows its own objective and constraints while Player 2 is available only through a best-response map. For this class of games, we propose an asymmetric projected gradient descent-best response iteration that does not require full mutual knowledge of both players' optimization problems. Under suitable regularity conditions, we establish the existence and uniqueness of the Nash equilibrium and prove global linear convergence of the proposed iteration when the best-response map is exact. Recognizing that best-response maps are often learned or estimated, we further analyze the inexact case and show that, when the approximation error is uniformly bounded by $\varepsilon$, the iterates enter an explicit $O(\varepsilon)$ neighborhood of the true Nash equilibrium. Numerical results on a benchmark game corroborate the predicted convergence behavior and error scaling.
翻译:纳什均衡为多智能体决策与控制中的交互建模提供了原则性框架。然而,许多均衡求解方法隐含假设每个智能体都能获知其他智能体的目标函数与约束条件,这一假设在实际中往往难以成立。本文研究一类具有解耦可行集的非对称信息双玩家约束博弈,其中玩家1知晓自身目标与约束,而玩家2仅通过最优响应映射被感知。针对此类博弈,我们提出一种非对称投影梯度下降-最优响应迭代算法,该算法无需完全掌握双方优化问题的完整信息。在适当的正则性条件下,我们证明了纳什均衡的存在唯一性,并当最优响应映射精确时,证明了所提迭代算法的全局线性收敛性。考虑到最优响应映射常通过学习或估计获得,我们进一步分析非精确情形,证明当近似误差被$\varepsilon$一致界定时,迭代序列将进入真实纳什均衡的显式$O(\varepsilon)$邻域。基准博弈的数值结果验证了理论预测的收敛行为与误差缩放特性。