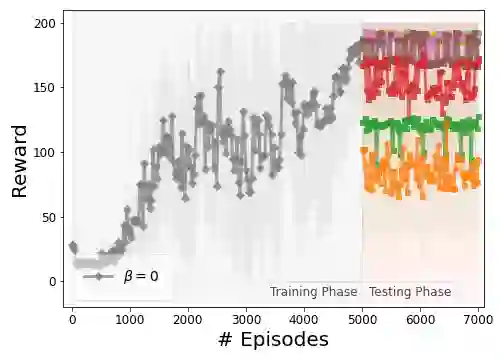
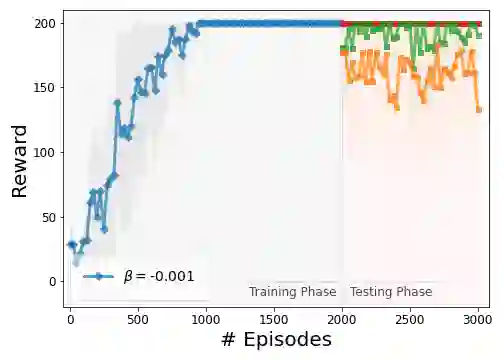
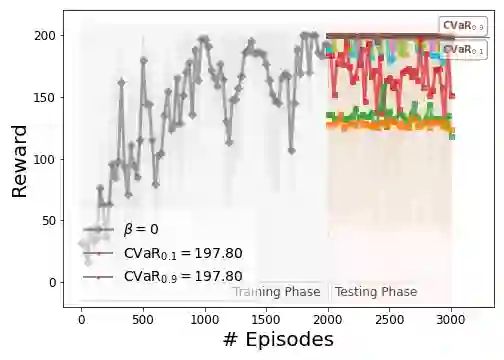
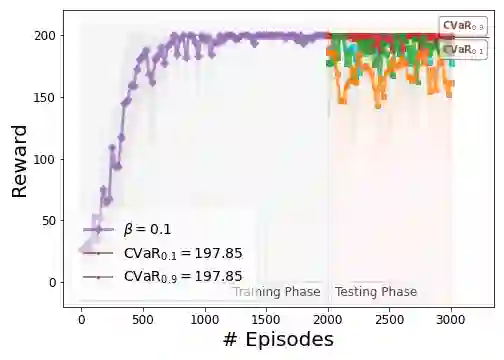
While reinforcement learning has shown experimental success in a number of applications, it is known to be sensitive to noise and perturbations in the parameters of the system, leading to high variance in the total reward amongst different episodes on slightly different environments. To introduce robustness, as well as sample efficiency, risk-sensitive reinforcement learning methods are being thoroughly studied. In this work, we provide a definition of robust reinforcement learning policies and formulate a risk-sensitive reinforcement learning problem to approximate them, by solving an optimization problem with respect to a modified objective based on exponential criteria. In particular, we study a model-free risk-sensitive variation of the widely-used Monte Carlo Policy Gradient algorithm, and introduce a novel risk-sensitive online Actor-Critic algorithm based on solving a multiplicative Bellman equation using stochastic approximation updates. Analytical results suggest that the use of exponential criteria generalizes commonly used ad-hoc regularization approaches, improves sample efficiency, and introduces robustness with respect to perturbations in the model parameters and the environment. The implementation, performance, and robustness properties of the proposed methods are evaluated in simulated experiments.
翻译:尽管强化学习在诸多应用中展现出实验成功,但其对系统参数中的噪声与扰动较为敏感,这导致在略有差异的环境下不同回合的总奖励存在高方差。为引入鲁棒性并提升样本效率,风险敏感强化学习方法正被深入研究。本文定义了鲁棒强化学习策略,并通过求解基于指数准则修正目标的优化问题,构建相应的风险敏感强化学习问题以近似这些策略。具体而言,我们研究了广泛使用的蒙特卡洛策略梯度算法的一种无模型风险敏感变体,并基于随机逼近更新求解乘法贝尔曼方程,提出了一种新型风险敏感在线执行者-评论家算法。分析结果表明,采用指数准则可泛化常用的启发式正则化方法,提升样本效率,并增强对模型参数与环境扰动的鲁棒性。通过仿真实验对所提方法的实现效果、性能及鲁棒性特性进行了评估。