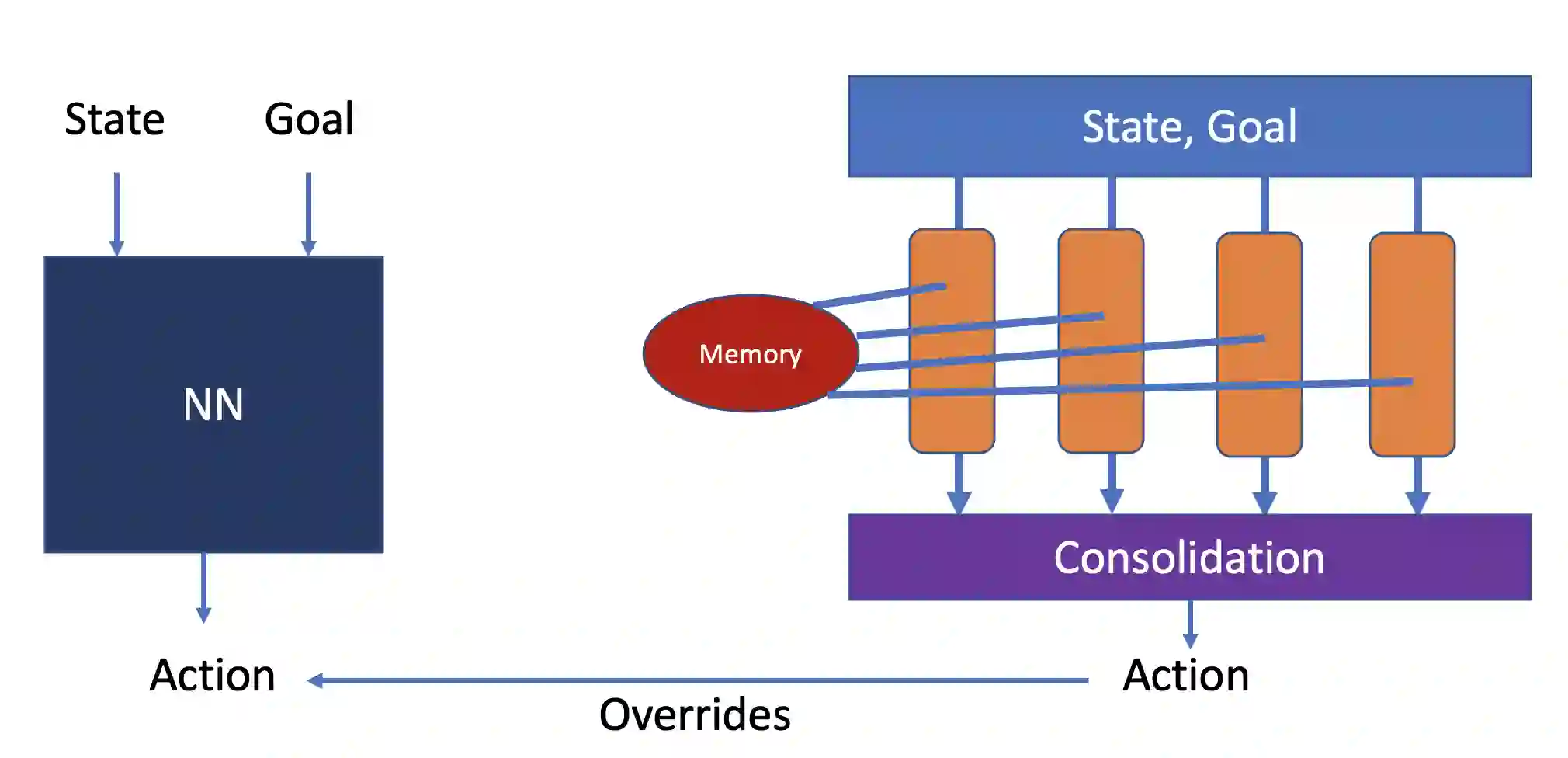
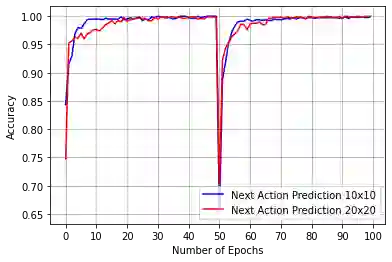
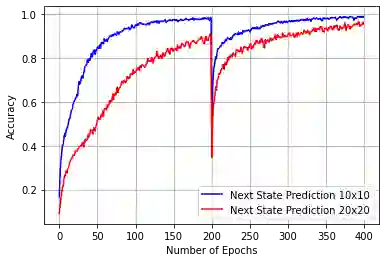
Model-based next state prediction and state value prediction are slow to converge. To address these challenges, we do the following: i) Instead of a neural network, we do model-based planning using a parallel memory retrieval system (which we term the slow mechanism); ii) Instead of learning state values, we guide the agent's actions using goal-directed exploration, by using a neural network to choose the next action given the current state and the goal state (which we term the fast mechanism). The goal-directed exploration is trained online using hippocampal replay of visited states and future imagined states every single time step, leading to fast and efficient training. Empirical studies show that our proposed method has a 92% solve rate across 100 episodes in a dynamically changing grid world, significantly outperforming state-of-the-art actor critic mechanisms such as PPO (54%), TRPO (50%) and A2C (24%). Ablation studies demonstrate that both mechanisms are crucial. We posit that the future of Reinforcement Learning (RL) will be to model goals and sub-goals for various tasks, and plan it out in a goal-directed memory-based approach.
翻译:基于模型的下一状态预测和状态价值预测收敛速度较慢。为解决这些问题,我们采取以下措施:i)使用并行记忆检索系统(我们称之为慢速机制)替代神经网络,进行基于模型的规划;ii)不学习状态价值,而是通过目标导向探索引导智能体的动作,即利用神经网络根据当前状态和目标状态选择下一个动作(我们称之为快速机制)。该目标导向探索通过海马体对已访问状态和未来想象状态的每个时间步在线回放进行训练,从而实现快速高效的训练。实证研究表明,在动态变化的网格世界中,我们的方法在100个回合中达到92%的求解率,显著优于最先进的演员-评论家机制,如PPO(54%)、TRPO(50%)和A2C(24%)。消融实验证明两种机制均至关重要。我们认为,强化学习的未来是为各种任务建模目标和子目标,并以基于目标导向记忆的方式规划执行。