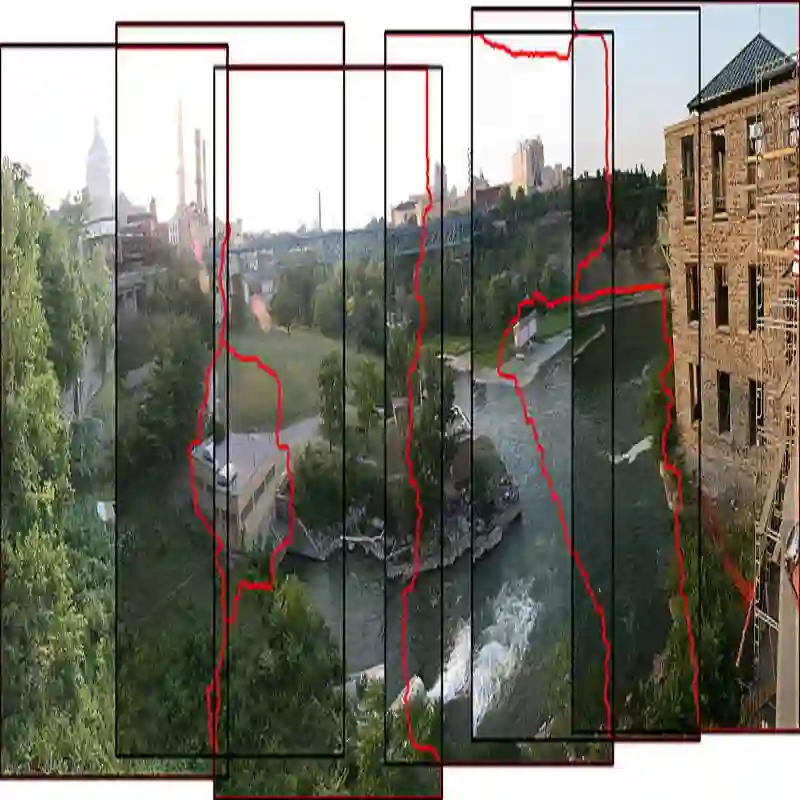
Current image stitching methods often produce noticeable seams in challenging scenarios such as uneven hue and large parallax. To tackle this problem, we propose the Reference-Driven Inpainting Stitcher (RDIStitcher), which reformulates the image fusion and rectangling as a reference-based inpainting model, incorporating a larger modification fusion area and stronger modification intensity than previous methods. Furthermore, we introduce a self-supervised model training method, which enables the implementation of RDIStitcher without requiring labeled data by fine-tuning a Text-to-Image (T2I) diffusion model. Recognizing difficulties in assessing the quality of stitched images, we present the Multimodal Large Language Models (MLLMs)-based metrics, offering a new perspective on evaluating stitched image quality. Compared to the state-of-the-art (SOTA) method, extensive experiments demonstrate that our method significantly enhances content coherence and seamless transitions in the stitched images. Especially in the zero-shot experiments, our method exhibits strong generalization capabilities. Code: https://github.com/yayoyo66/RDIStitcher
翻译:当前图像拼接方法在色调不均和大视差等挑战性场景中常产生明显接缝。为解决此问题,我们提出参考驱动修复拼接器(RDIStitcher),将图像融合与矩形化重构为基于参考的修复模型,相比现有方法引入了更大的修改融合区域与更强的修改强度。此外,我们提出一种自监督模型训练方法,通过微调文本到图像(T2I)扩散模型,无需标注数据即可实现RDIStitcher。针对拼接图像质量评估的难点,我们提出基于多模态大语言模型(MLLMs)的评估指标,为拼接图像质量评估提供了新视角。与最先进(SOTA)方法相比,大量实验表明我们的方法显著提升了拼接图像的内容连贯性与过渡无缝性。特别是在零样本实验中,本方法展现出强大的泛化能力。代码:https://github.com/yayoyo66/RDIStitcher