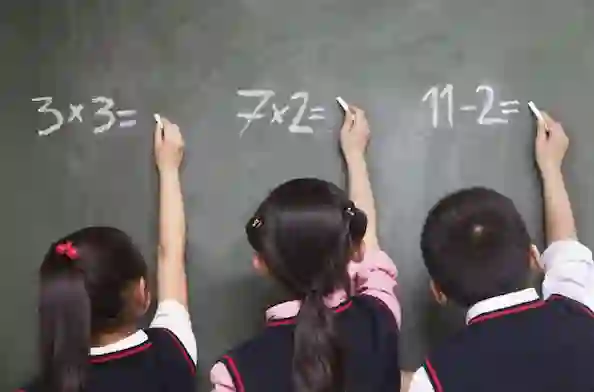We propose MM-Vet, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development. Problems include: (1) How to systematically structure and evaluate the complicated multimodal tasks; (2) How to design evaluation metrics that work well across question and answer types; and (3) How to give model insights beyond a simple performance ranking. To this end, we present MM-Vet, designed based on the insight that the intriguing ability to solve complicated tasks is often achieved by a generalist model being able to integrate different core vision-language (VL) capabilities. MM-Vet defines 6 core VL capabilities and examines the 16 integrations of interest derived from the capability combination. For evaluation metrics, we propose an LLM-based evaluator for open-ended outputs. The evaluator enables the evaluation across different question types and answer styles, resulting in a unified scoring metric. We evaluate representative LMMs on MM-Vet, providing insights into the capabilities of different LMM system paradigms and models. Code and data are available at https://github.com/yuweihao/MM-Vet.
翻译:我们提出MM-Vet,一个用于在复杂多模态任务中检验大型多模态模型(LMMs)的评估基准。近期LMMs展现出多种引人注目的能力,例如解答黑板上书写的数学问题、推理新闻图像中的事件和名人、以及解读视觉笑话。模型的快速进步给评估基准的开发带来了挑战,具体包括:(1) 如何系统性地构建和评估复杂多模态任务;(2) 如何设计能跨问答类型有效工作的评估指标;(3) 如何提供超越简单性能排名的模型洞察。为此,我们提出MM-Vet,其设计基于以下洞察:解决复杂任务的引人注目能力常源于通用模型能整合不同核心视觉-语言(VL)能力。MM-Vet定义了6种核心VL能力,并检验了由能力组合导出的16种感兴趣的整合方式。在评估指标方面,我们提出一个基于LLM的评估器来处理开放式输出,该评估器支持跨不同问题类型和答案风格的评估,从而实现统一的评分指标。我们在MM-Vet上评估了代表性LMMs,为不同LMM系统范式及模型的能力提供了洞察。代码与数据可通过https://github.com/yuweihao/MM-Vet获取。