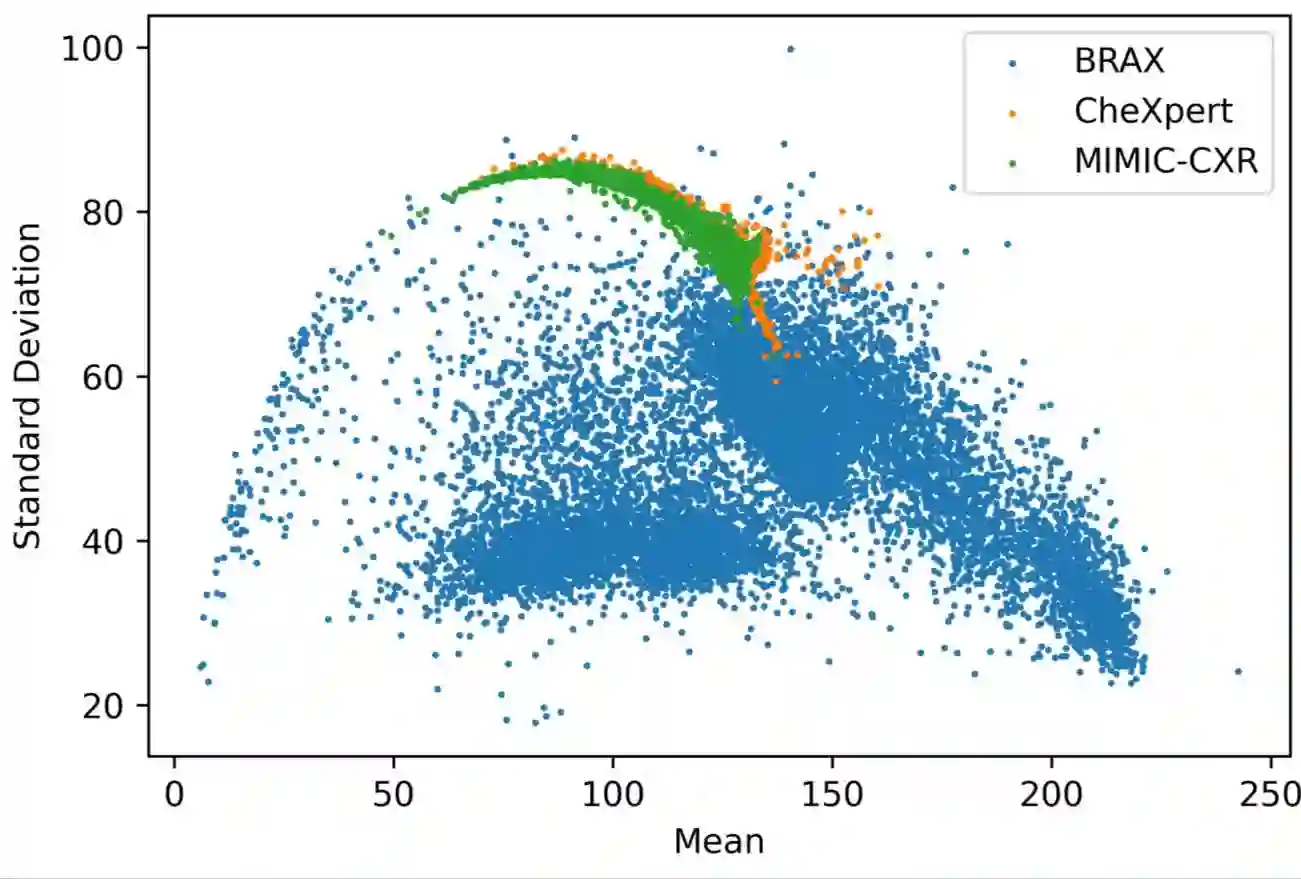
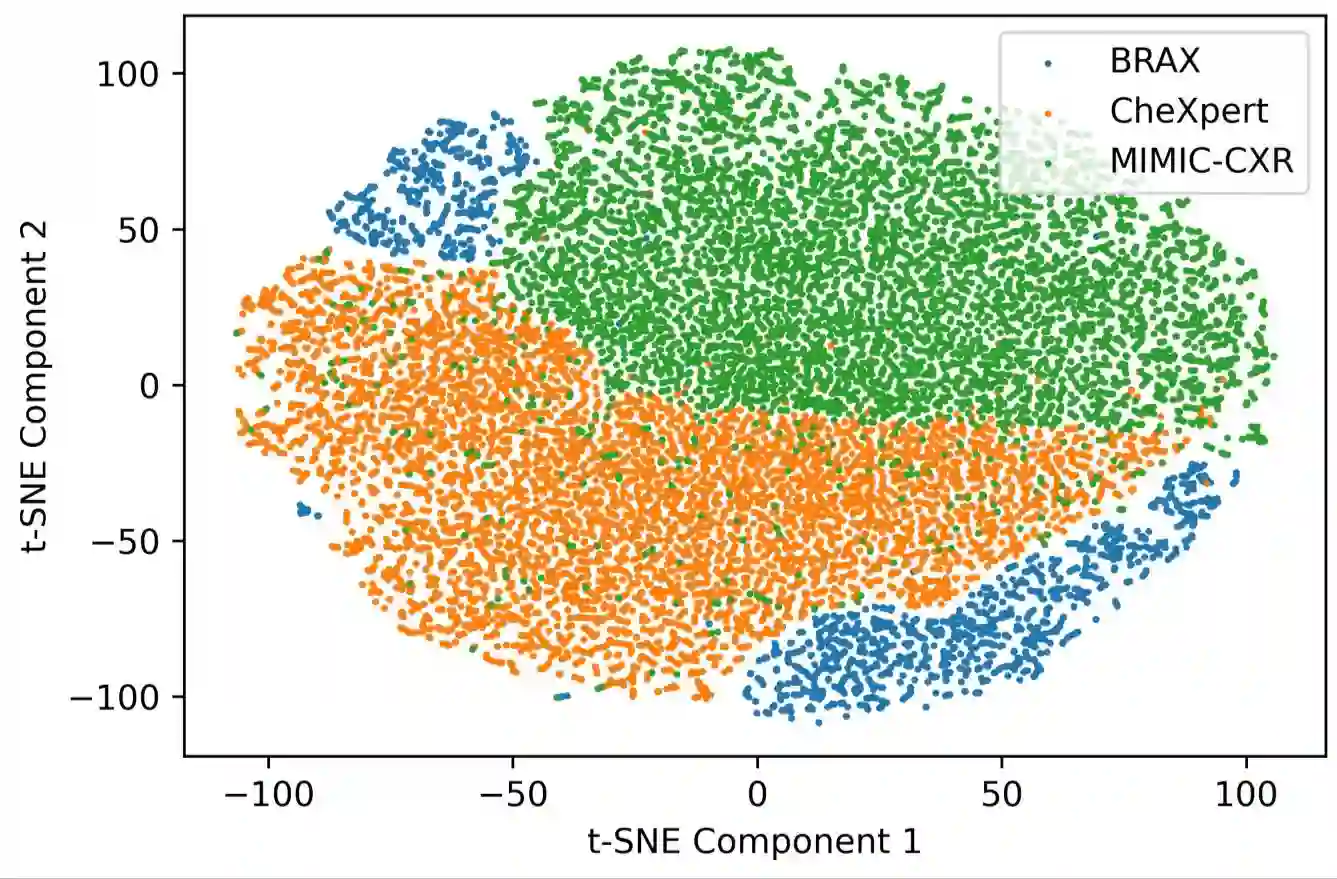
Performance degradation due to distribution discrepancy is a longstanding challenge in intelligent imaging, particularly for chest X-rays (CXRs). Recent studies have demonstrated that CNNs are biased toward styles (e.g., uninformative textures) rather than content (e.g., shape), in stark contrast to the human vision system. Radiologists tend to learn visual cues from CXRs and thus perform well across multiple domains. Motivated by this, we employ the novel on-the-fly style randomization modules at both image (SRM-IL) and feature (SRM-FL) levels to create rich style perturbed features while keeping the content intact for robust cross-domain performance. Previous methods simulate unseen domains by constructing new styles via interpolation or swapping styles from existing data, limiting them to available source domains during training. However, SRM-IL samples the style statistics from the possible value range of a CXR image instead of the training data to achieve more diversified augmentations. Moreover, we utilize pixel-wise learnable parameters in the SRM-FL compared to pre-defined channel-wise mean and standard deviations as style embeddings for capturing more representative style features. Additionally, we leverage consistency regularizations on global semantic features and predictive distributions from with and without style-perturbed versions of the same CXR to tweak the model's sensitivity toward content markers for accurate predictions. Our proposed method, trained on CheXpert and MIMIC-CXR datasets, achieves 77.32$\pm$0.35, 88.38$\pm$0.19, 82.63$\pm$0.13 AUCs(%) on the unseen domain test datasets, i.e., BRAX, VinDr-CXR, and NIH chest X-ray14, respectively, compared to 75.56$\pm$0.80, 87.57$\pm$0.46, 82.07$\pm$0.19 from state-of-the-art models on five-fold cross-validation with statistically significant results in thoracic disease classification.
翻译:分布差异导致的性能退化是智能成像领域的长期挑战,尤其在胸部X光片(CXR)中尤为突出。近年研究表明,卷积神经网络(CNN)倾向于关注风格特征(如无信息纹理)而非内容特征(如形状),这与人类视觉系统存在显著差异。放射科医生通常通过学习CXR的视觉线索,从而在多个域中保持优异表现。受此启发,我们分别在图像级(SRM-IL)和特征级(SRM-FL)引入新颖的即时风格随机化模块,在保持内容完整的同时生成丰富的风格扰动特征,以实现稳健的跨域性能。现有方法通过插值或交换现有数据风格来模拟未知域,但受限于训练过程中可用的源域。而SRM-IL从CXR图像的可能值范围中采样风格统计量,而非训练数据,从而实现更多样化的数据增强。此外,我们利用SRM-FL中像素级可学习参数,替代传统的预定义通道级均值和标准差作为风格嵌入,以捕获更具代表性的风格特征。同时,我们对同一CXR图像在有无风格扰动版本下的全局语义特征和预测分布施加一致性正则化,以调整模型对内容标记的敏感度,实现精准预测。所提方法在CheXpert和MIMIC-CXR数据集上训练后,在未知域测试集(BRAX、VinDr-CXR和NIH Chest X-ray14)上分别达到77.32±0.35、88.38±0.19和82.63±0.13的AUC(%),而基于五折交叉验证的胸科疾病分类任务中,现有最优模型对应结果为75.56±0.80、87.57±0.46和82.07±0.19,且具有统计显著性。