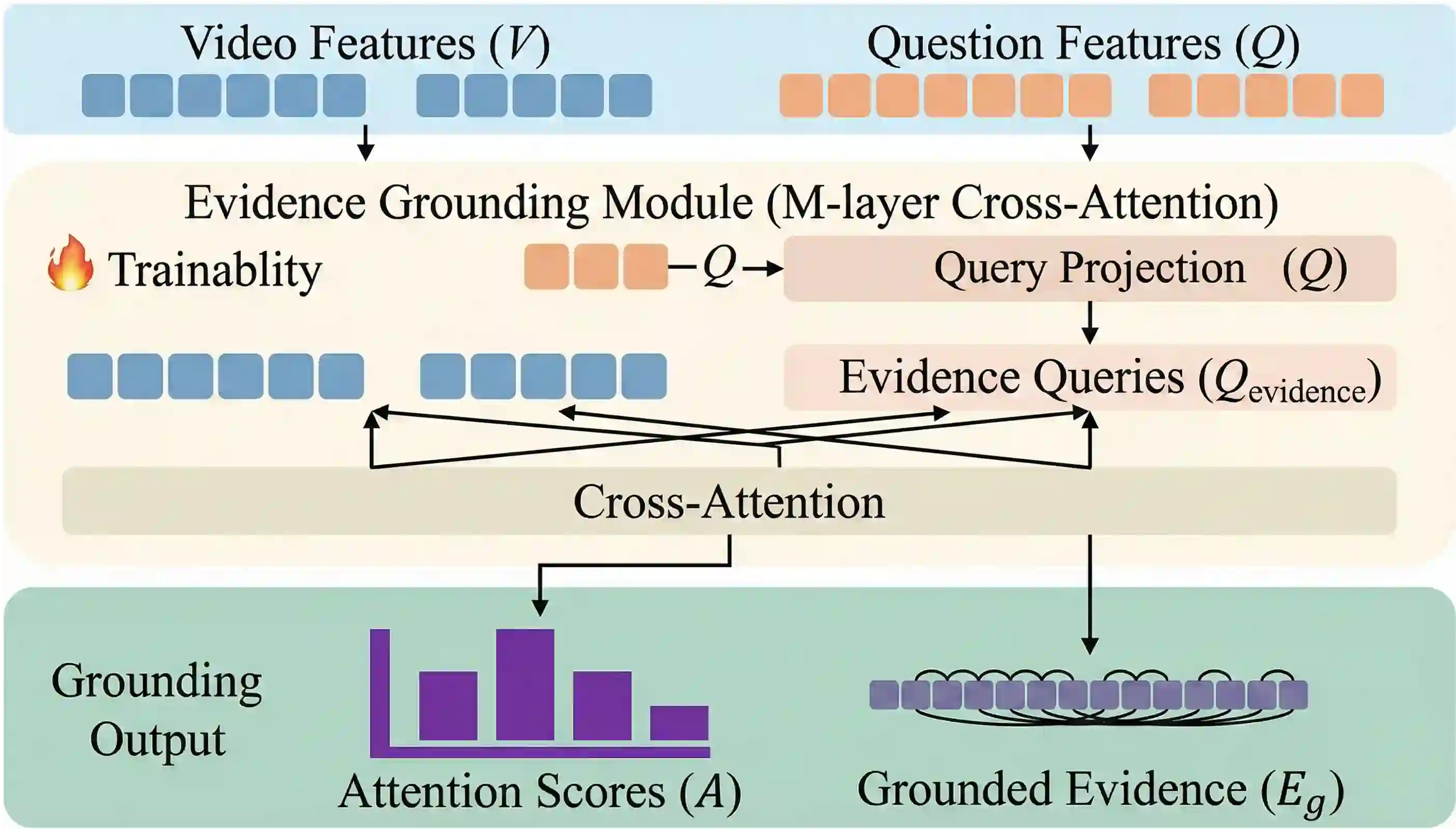
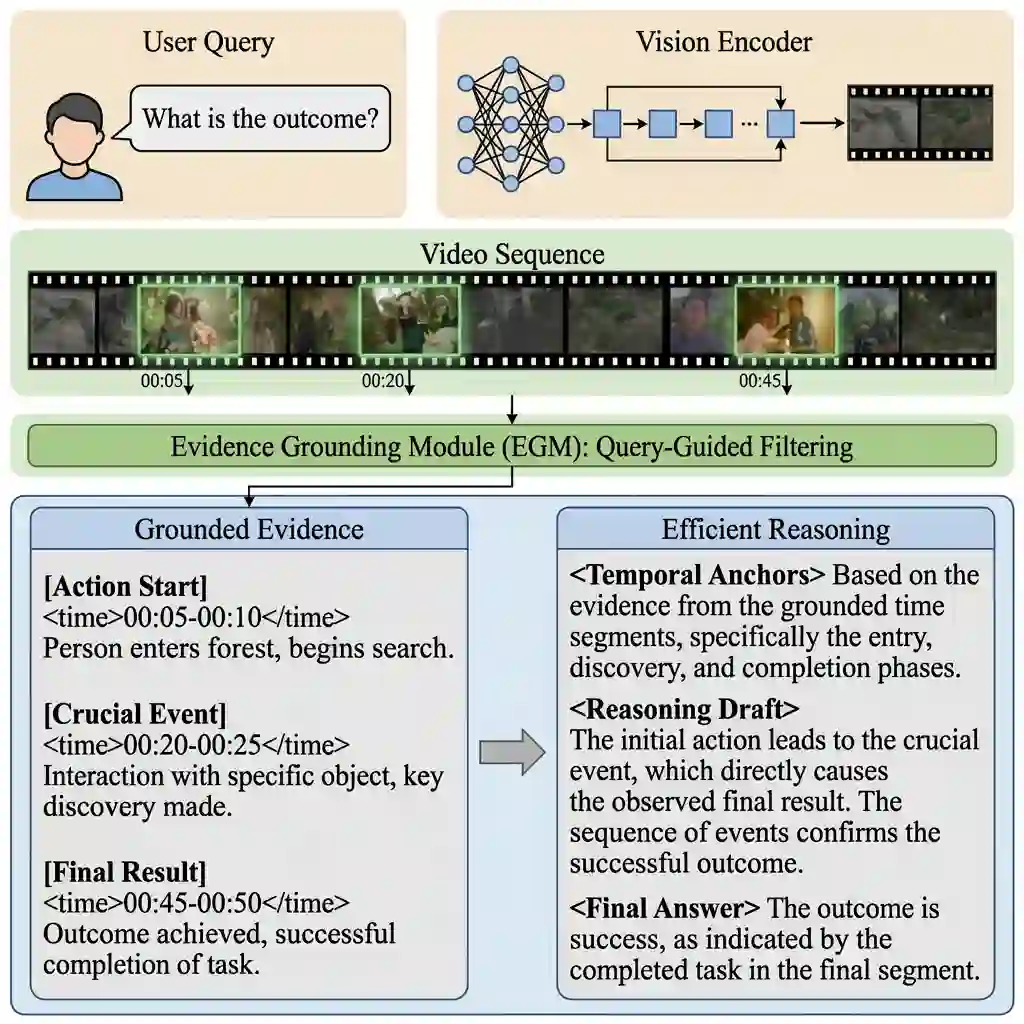
Large Vision-Language Models (LVLMs) face a fundamental dilemma in video reasoning: they are caught between the prohibitive computational costs of verbose reasoning and the hallucination risks of efficient, ungrounded approaches. To resolve this, we introduce the Chain of Evidence (CoE), a novel framework that architecturally decouples and co-optimizes perceptual grounding and reasoning efficiency. CoE incorporates two core innovations: (1) A lightweight Evidence Grounding Module (EGM) that acts as a query-guided filter, dynamically identifying and extracting a compact set of high-fidelity visual evidence; and (2) An Evidence-Anchoring Protocol optimized via Reinforcement Learning. Crucially, we design a composite reward mechanism that enforces process alignment, compelling the model to strictly reference identified temporal anchors during deduction, thereby mitigating hallucinations. To enable this, we construct CoE-Instruct, a large-scale dataset (164k samples) featuring a novel dual-annotation schema for separate perception and reasoning supervision. Extensive experiments on five benchmarks, including Video-MME, MVBench, and VSI-Bench, demonstrate that CoE-enhanced models establish a new state-of-the-art. They significantly outperform existing methods in accuracy, proving CoE to be a powerful and practical paradigm for reliable video understanding.
翻译:大型视觉语言模型(LVLMs)在视频推理中面临一个根本性困境:它们被困在冗长推理的过高计算成本与高效但无依据方法所带来的幻觉风险之间。为解决此问题,我们引入了证据链(CoE),这是一个新颖的框架,在架构上将感知定位与推理效率解耦并协同优化。CoE包含两项核心创新:(1)一个轻量级的证据定位模块(EGM),作为查询引导的过滤器,动态识别并提取一组紧凑的高保真视觉证据;(2)一个通过强化学习优化的证据锚定协议。关键的是,我们设计了一种复合奖励机制,强制实现过程对齐,迫使模型在演绎过程中严格引用已识别的时间锚点,从而减轻幻觉。为此,我们构建了CoE-Instruct,这是一个大规模数据集(164k样本),采用新颖的双重标注模式,用于独立的感知和推理监督。在包括Video-MME、MVBench和VSI-Bench在内的五个基准测试上的广泛实验表明,经CoE增强的模型确立了新的最先进水平。它们在准确性上显著优于现有方法,证明CoE是可靠视频理解的一个强大且实用的范式。