
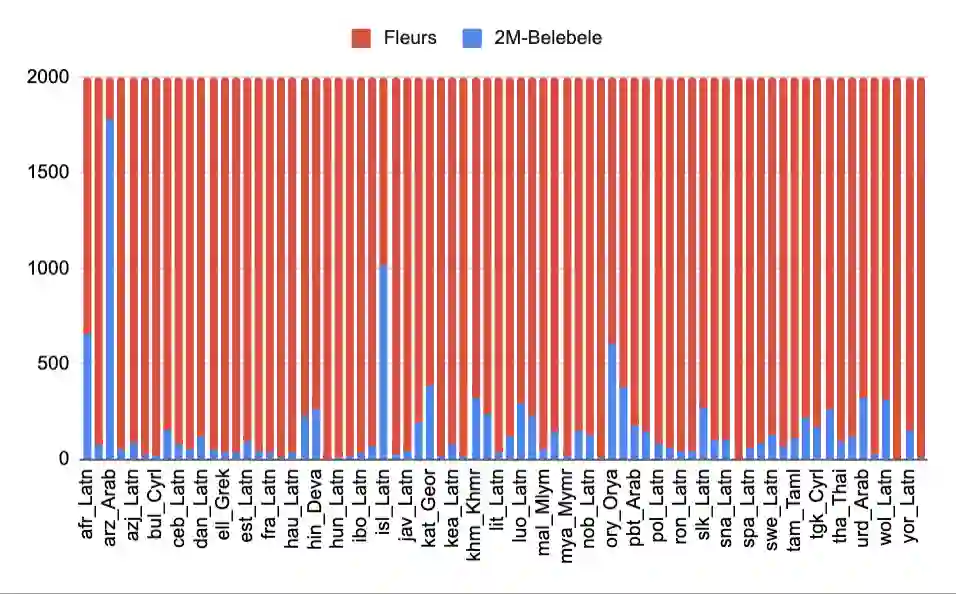
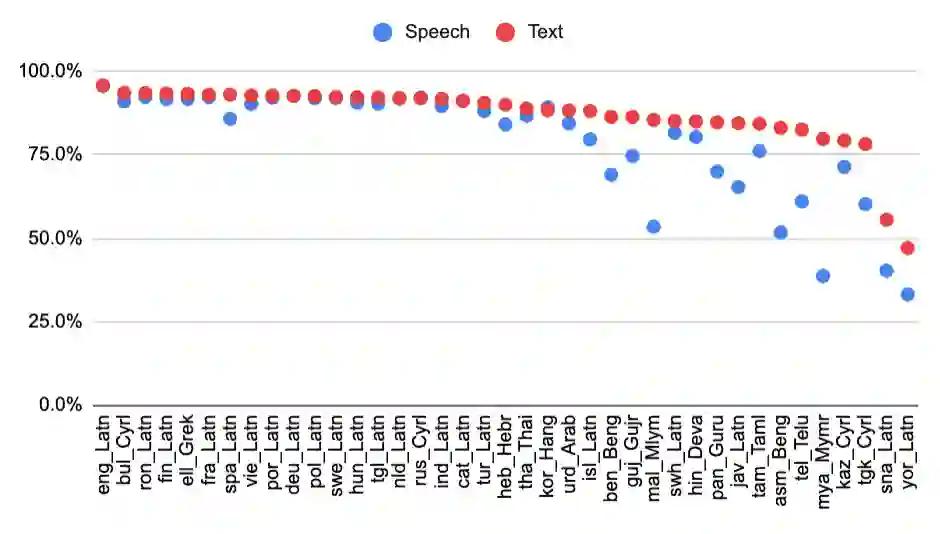
We introduce the first highly multilingual speech and American Sign Language (ASL) comprehension dataset by extending BELEBELE. Our dataset covers 74 spoken languages at the intersection of BELEBELE and FLEURS, and one sign language (ASL). We evaluate 2M-BELEBELE dataset for both 5-shot and zero-shot settings and across languages, the speech comprehension accuracy is ~ 2-3% average lower compared to reading comprehension.
翻译:我们通过扩展BELEBELE,引入了首个高度多语言的语音与美国手语理解数据集。我们的数据集涵盖了BELEBELE与FLEURS交集部分的74种口语,以及一种手语(美国手语)。我们在5样本和零样本设置下,并跨语言评估了2M-BELEBELE数据集,结果显示,语音理解准确率平均比阅读理解低约2-3%。
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
17+阅读 · 2021年6月18日
Arxiv
11+阅读 · 2020年7月31日
Arxiv
16+阅读 · 2019年4月3日




最新内容
相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯