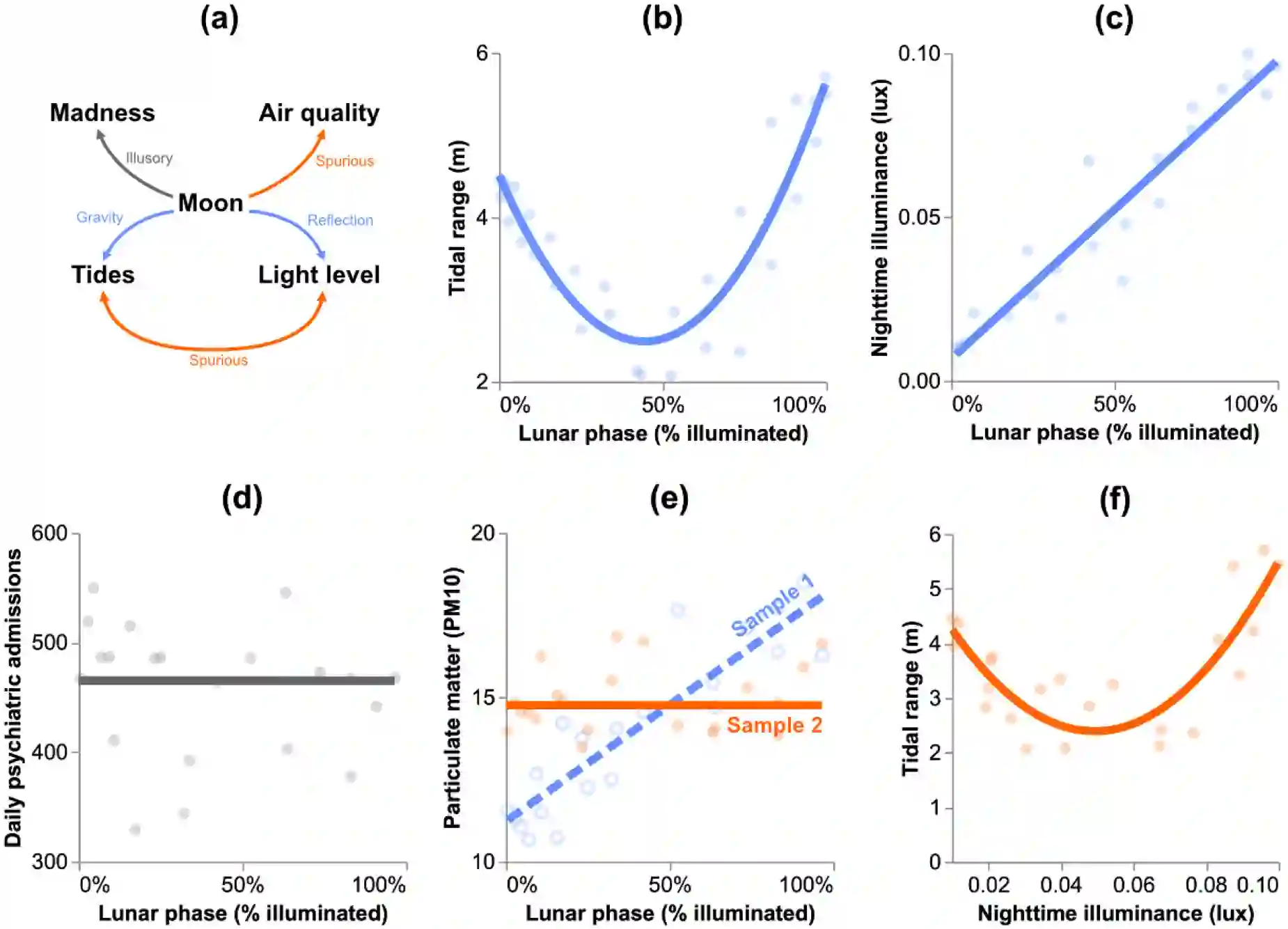
Learning correlations from data forms the foundation of today's machine learning (ML) and artificial intelligence research. While contemporary methods enable the automatic discovery of complex patterns, they are prone to failure when unintended correlations are captured. This vulnerability has spurred a growing interest in interrogating spuriousness, which is often seen as a threat to model performance, fairness, and robustness. In this article, we trace departures from the conventional statistical definition of spuriousness-which denotes a non-causal relationship arising from coincidence or confounding-to examine how its meaning is negotiated in ML research. Rather than relying solely on formal definitions, researchers assess spuriousness through what we call pragmatic frames: Judgments based on what a correlation does in practice-how it affects model behavior, supports or impedes task performance, or aligns with broader normative goals. Drawing on a broad survey of ML literature, we identify four such frames: Relevance (Models should use correlations that are relevant to the task), generalizability (Models should use correlations that generalize to unseen data), human-likeness (Models should use correlations that a human would use to perform the same task), and harmfulness (Models should use correlations that are not socially or ethically harmful). These representations reveal that correlation desirability is not a fixed statistical property but a situated judgment informed by technical, epistemic, and ethical considerations. By examining how a foundational ML conundrum is problematized in research literature, we contribute to broader conversations on the contingent practices through which technical concepts like spuriousness are defined and operationalized.
翻译:从数据中学习相关性构成了当今机器学习(ML)与人工智能研究的基础。尽管现代方法能够自动发现复杂模式,但当捕捉到非预期相关性时,这些方法容易失效。这一脆弱性激发了对虚假性(spuriousness)的日益关注,后者常被视为威胁模型性能、公平性和鲁棒性的因素。本文追溯了背离传统统计定义中虚假性(即由巧合或混杂产生的非因果关联)的研究路径,以探究其意义在机器学习研究中如何被重新界定。研究者并非仅依赖形式化定义,而是通过我们称之为“语用框架”的方式评估虚假性:即基于相关性在实践中产生的作用——它如何影响模型行为、支持或阻碍任务性能、或与更广泛的规范性目标保持一致——进行判断。通过对机器学习文献的广泛调研,我们识别出四种此类框架:相关性(模型应使用与任务相关的相关性)、泛化性(模型应使用可泛化至未见数据的相关性)、类人性(模型应使用人类在执行相同任务时会采用的相关性)、以及危害性(模型应使用不具有社会或伦理危害的相关性)。这些表征揭示,相关性的理想性并非固定的统计属性,而是由技术、认识论及伦理考量共同塑造的情境化判断。通过探究研究文献中如何将机器学习的基础难题问题化,我们为关于技术概念(如虚假性)如何被定义和实操化的偶然性实践的更广泛讨论做出贡献。