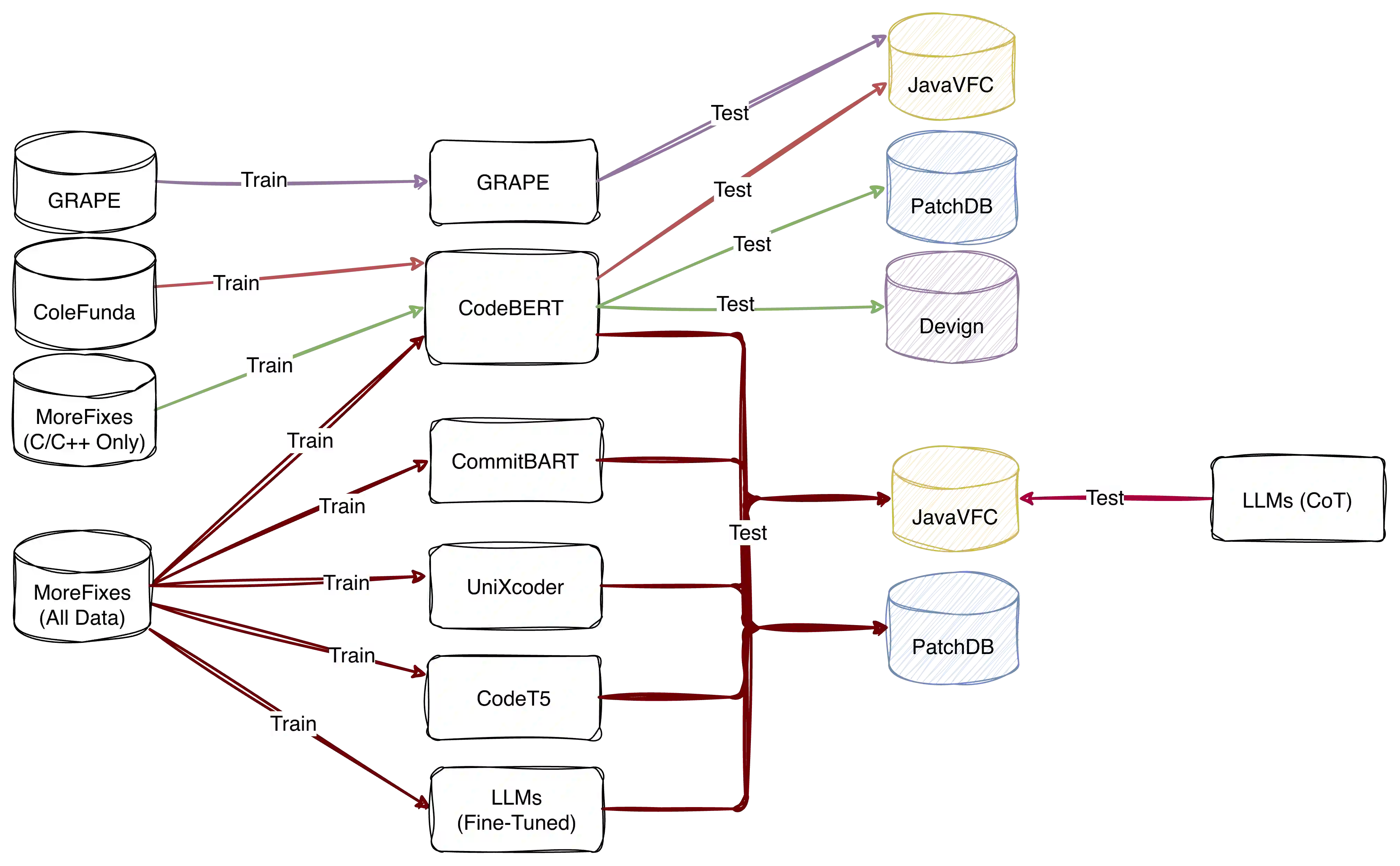
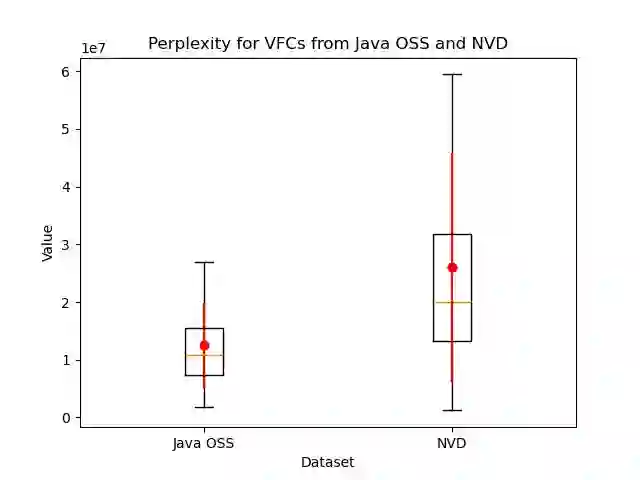
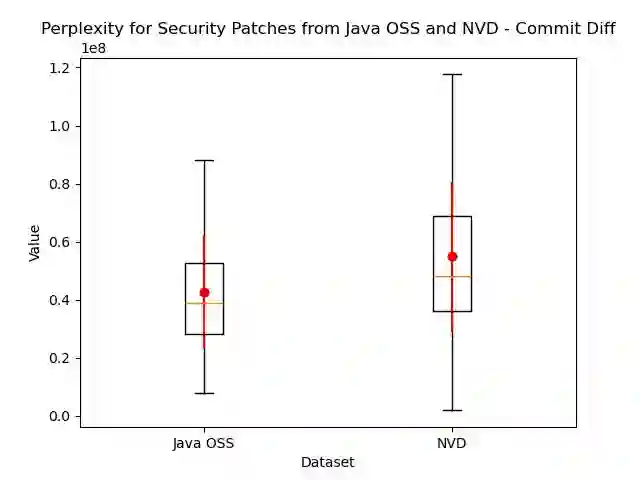
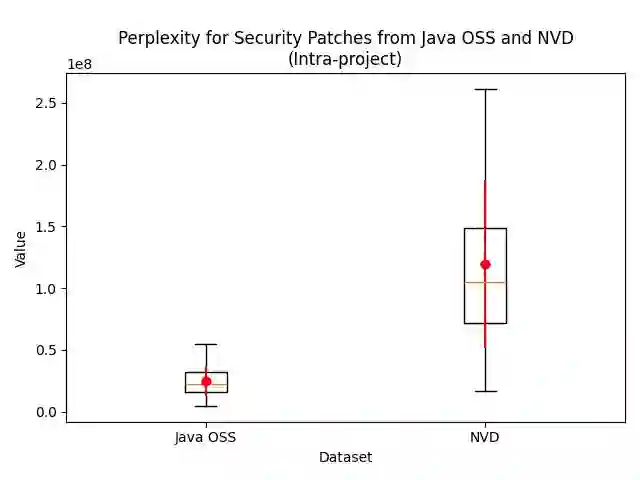
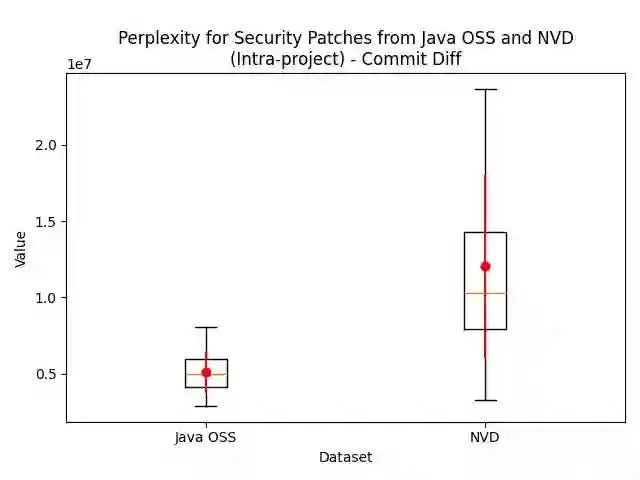
Attacks can exploit zero-day or one-day vulnerabilities that are not publicly disclosed. To detect these vulnerabilities, security researchers monitor development activities in open-source repositories to identify unreported security patches. The sheer volume of commits makes this task infeasible to accomplish manually. Consequently, security patch detectors commonly trained and evaluated on security patches linked from vulnerability reports in the National Vulnerability Database (NVD). In this study, we assess the effectiveness of these detectors when applied in-the-wild. Our results show that models trained on NVD-derived data show substantially decreased performance, with decreases in F1-score of up to 90\% when tested on in-the-wild security patches, rendering them impractical for real-world use. An analysis comparing security patches identified in-the-wild and commits linked from NVD reveals that they can be easily distinguished from each other. Security patches associated with NVD have different distribution of commit messages, vulnerability types, and composition of changes. These differences suggest that NVD may be unsuitable as the \textit{sole} source of data for training models to detect security patches. We find that constructing a dataset that combines security patches from NVD data with a small subset of manually identified security patches can improve model robustness.
翻译:攻击者可以利用未公开披露的零日或一日漏洞。为检测这些漏洞,安全研究人员监控开源仓库中的开发活动,以识别未报告的安全补丁。提交数量庞大,使得手动完成此任务不可行。因此,安全补丁检测器通常在从美国国家漏洞数据库(NVD)的漏洞报告中链接的安全补丁上进行训练和评估。在本研究中,我们评估了这些检测器在野外应用时的有效性。我们的结果表明,在NVD衍生数据上训练的模型性能显著下降,在野外安全补丁上测试时,F1分数下降高达90%,使其在实际应用中不切实际。一项比较野外识别的安全补丁与NVD链接的提交的分析表明,两者可以轻易区分。与NVD关联的安全补丁在提交消息、漏洞类型和变更构成方面具有不同的分布。这些差异表明,NVD可能不适合作为训练安全补丁检测模型的\textit{唯一}数据来源。我们发现,构建一个结合NVD数据中的安全补丁与一小部分手动识别的安全补丁的数据集,可以提高模型的鲁棒性。