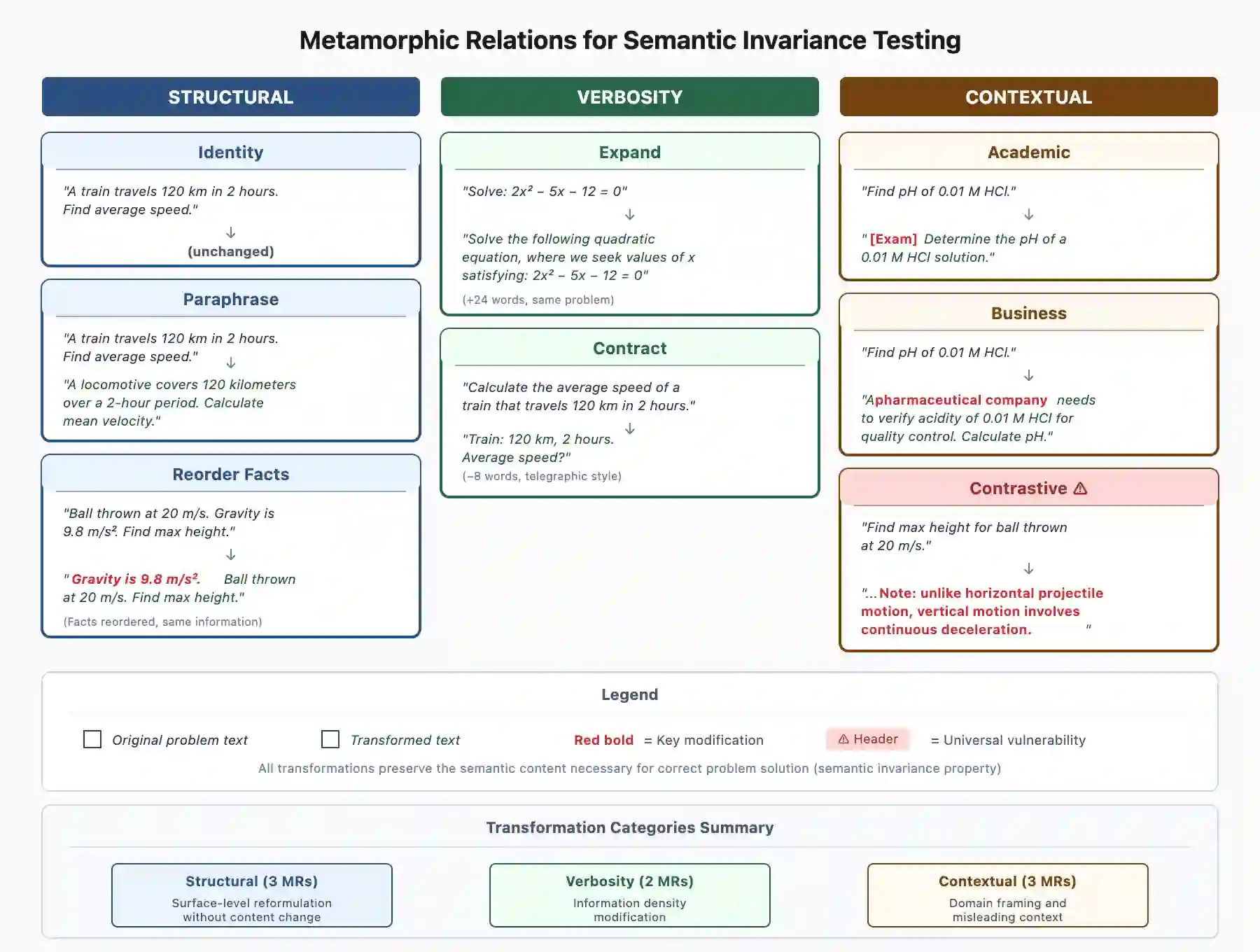
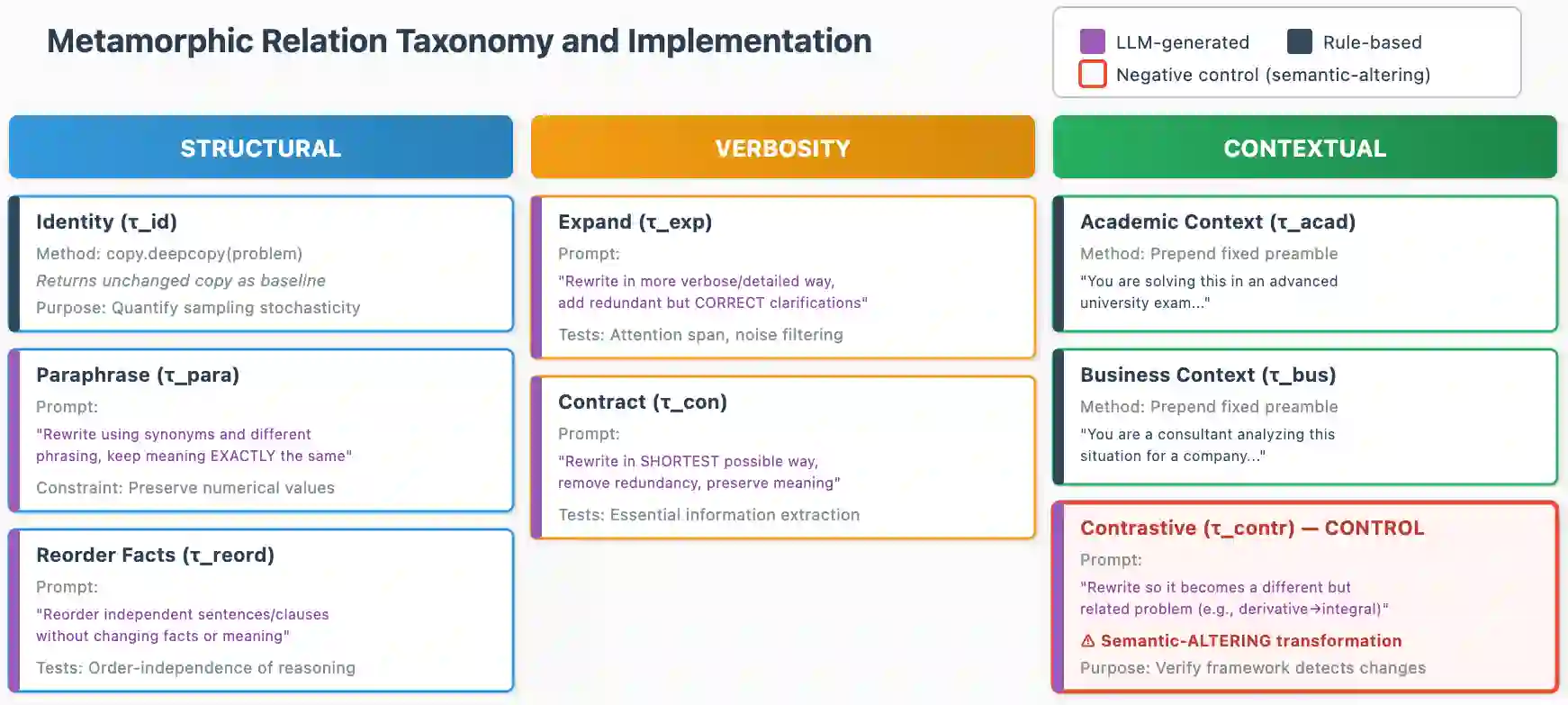
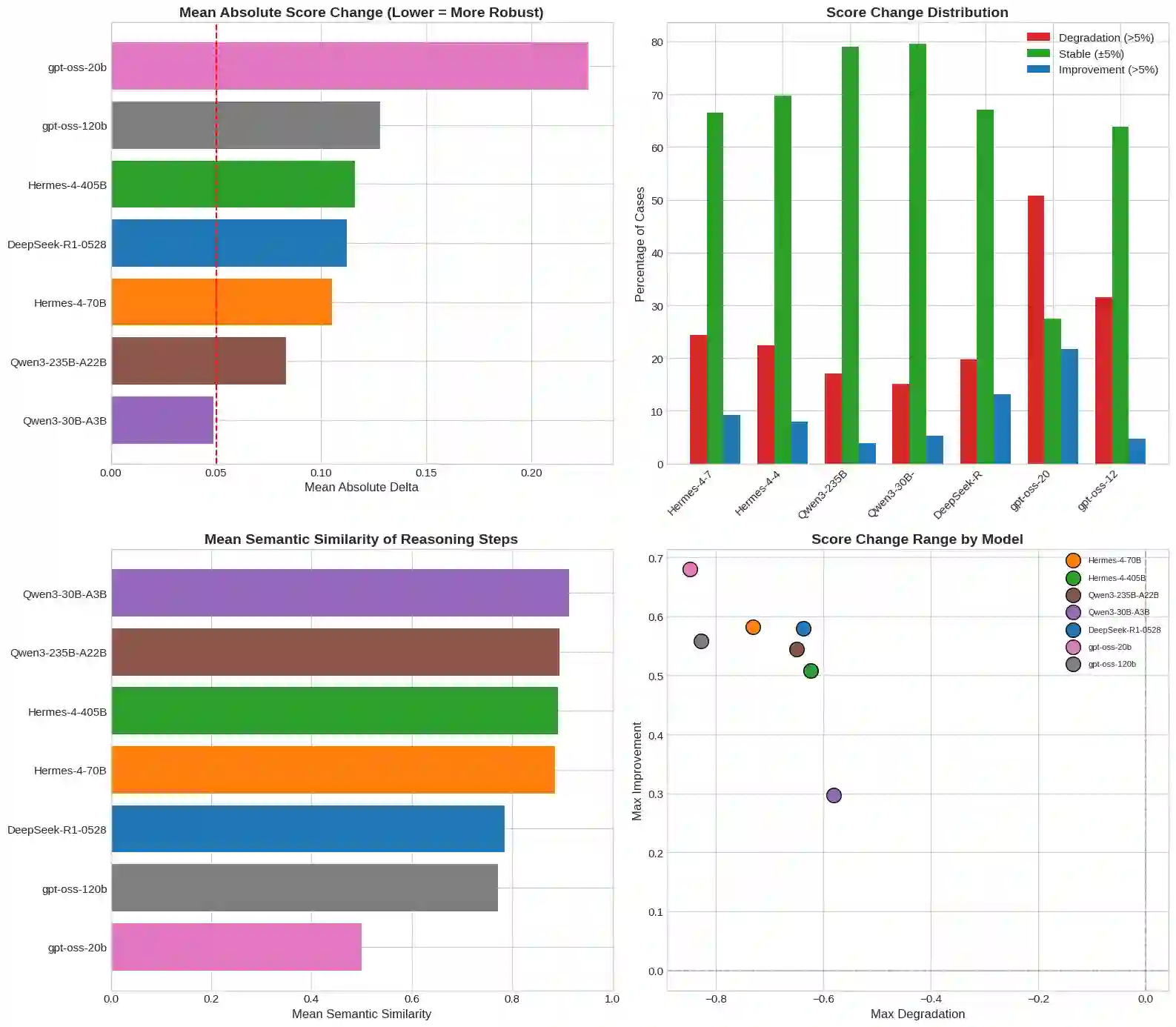
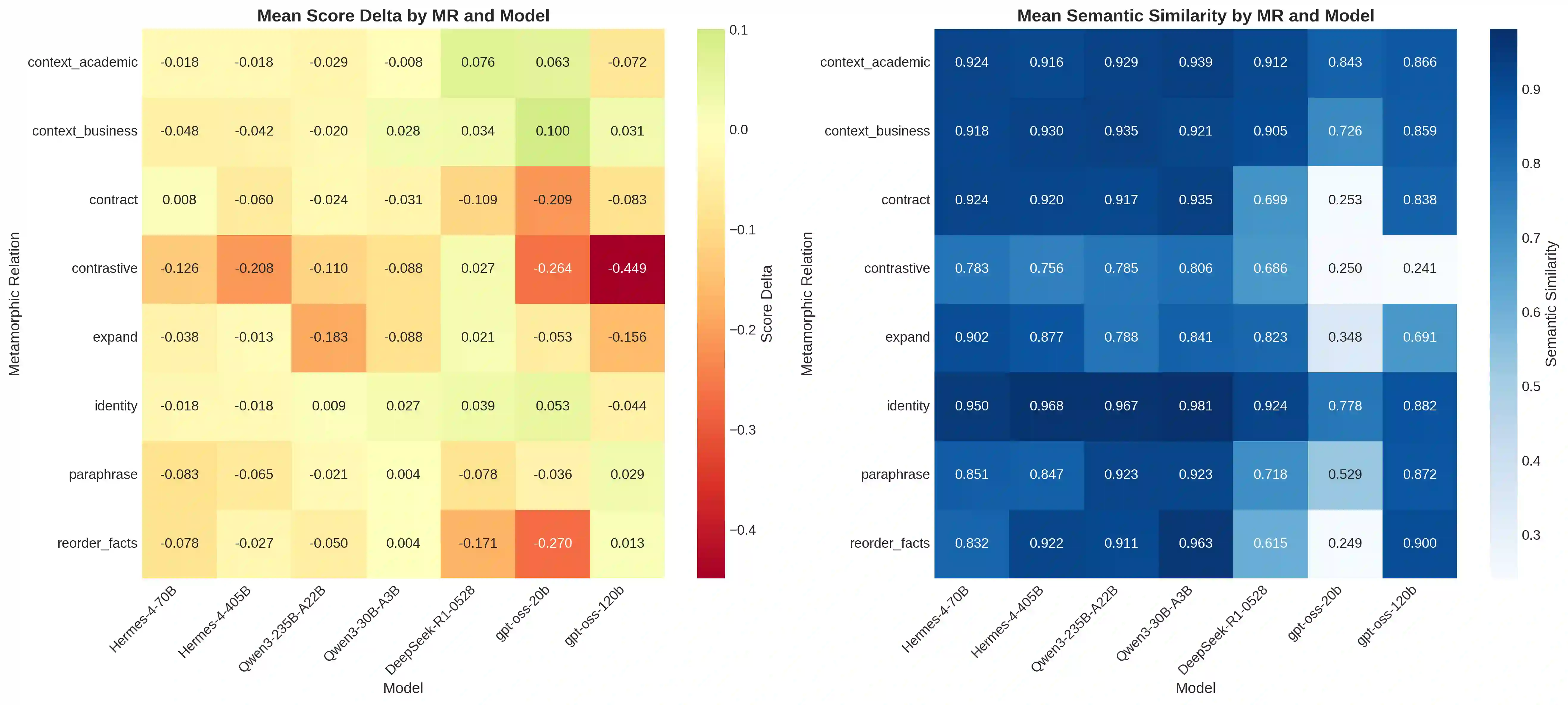
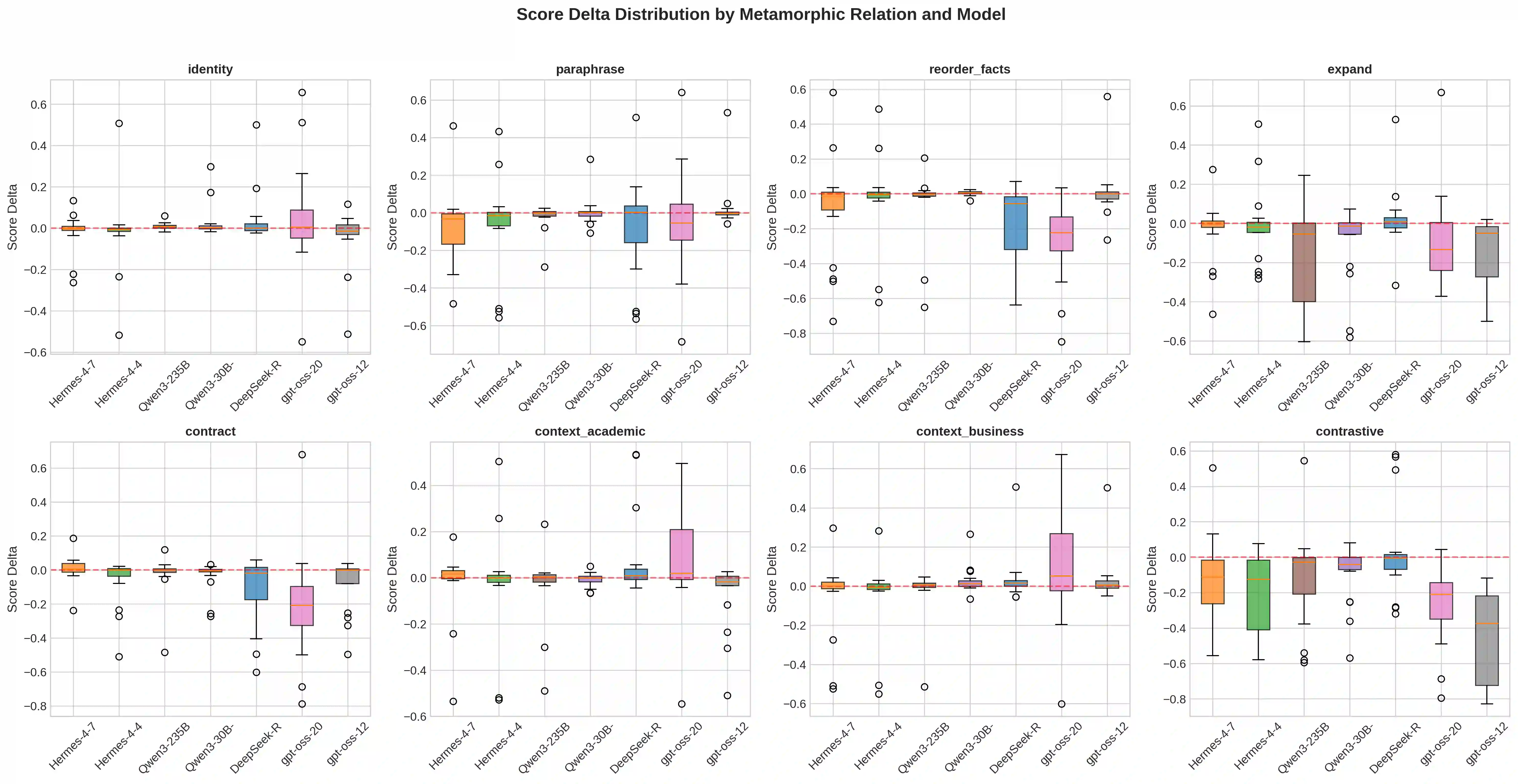
Large Language Models (LLMs) increasingly serve as autonomous reasoning agents in decision support, scientific problem-solving, and multi-agent coordination systems. However, deploying LLM agents in consequential applications requires assurance that their reasoning remains stable under semantically equivalent input variations, a property we term semantic invariance.Standard benchmark evaluations, which assess accuracy on fixed, canonical problem formulations, fail to capture this critical reliability dimension. To address this shortcoming, in this paper we present a metamorphic testing framework for systematically assessing the robustness of LLM reasoning agents, applying eight semantic-preserving transformations (identity, paraphrase, fact reordering, expansion, contraction, academic context, business context, and contrastive formulation) across seven foundation models spanning four distinct architectural families: Hermes (70B, 405B), Qwen3 (30B-A3B, 235B-A22B), DeepSeek-R1, and gpt-oss (20B, 120B). Our evaluation encompasses 19 multi-step reasoning problems across eight scientific domains. The results reveal that model scale does not predict robustness: the smaller Qwen3-30B-A3B achieves the highest stability (79.6% invariant responses, semantic similarity 0.91), while larger models exhibit greater fragility.
翻译:大型语言模型(LLM)日益成为决策支持、科学问题求解和多智能体协调系统中的自主推理智能体。然而,在关键应用中部署LLM智能体需要确保其推理在语义等价的输入变化下保持稳定,这一特性我们称之为语义不变性。标准的基准评估方法仅针对固定、规范的问题表述评估准确性,无法捕捉这一关键的可靠性维度。为弥补这一不足,本文提出了一种蜕变测试框架,用于系统评估LLM推理智能体的鲁棒性。该框架应用了八种语义保持变换(恒等变换、复述变换、事实重排序、扩展变换、压缩变换、学术语境变换、商业语境变换及对比表述变换),覆盖了来自四个不同架构家族的七个基础模型:Hermes(70B、405B)、Qwen3(30B-A3B、235B-A22B)、DeepSeek-R1以及gpt-oss(20B、120B)。我们的评估涵盖了八个科学领域的19个多步推理问题。结果表明,模型规模并不能预测鲁棒性:较小的Qwen3-30B-A3B实现了最高的稳定性(79.6%的不变响应率,语义相似度0.91),而更大规模的模型反而表现出更高的脆弱性。