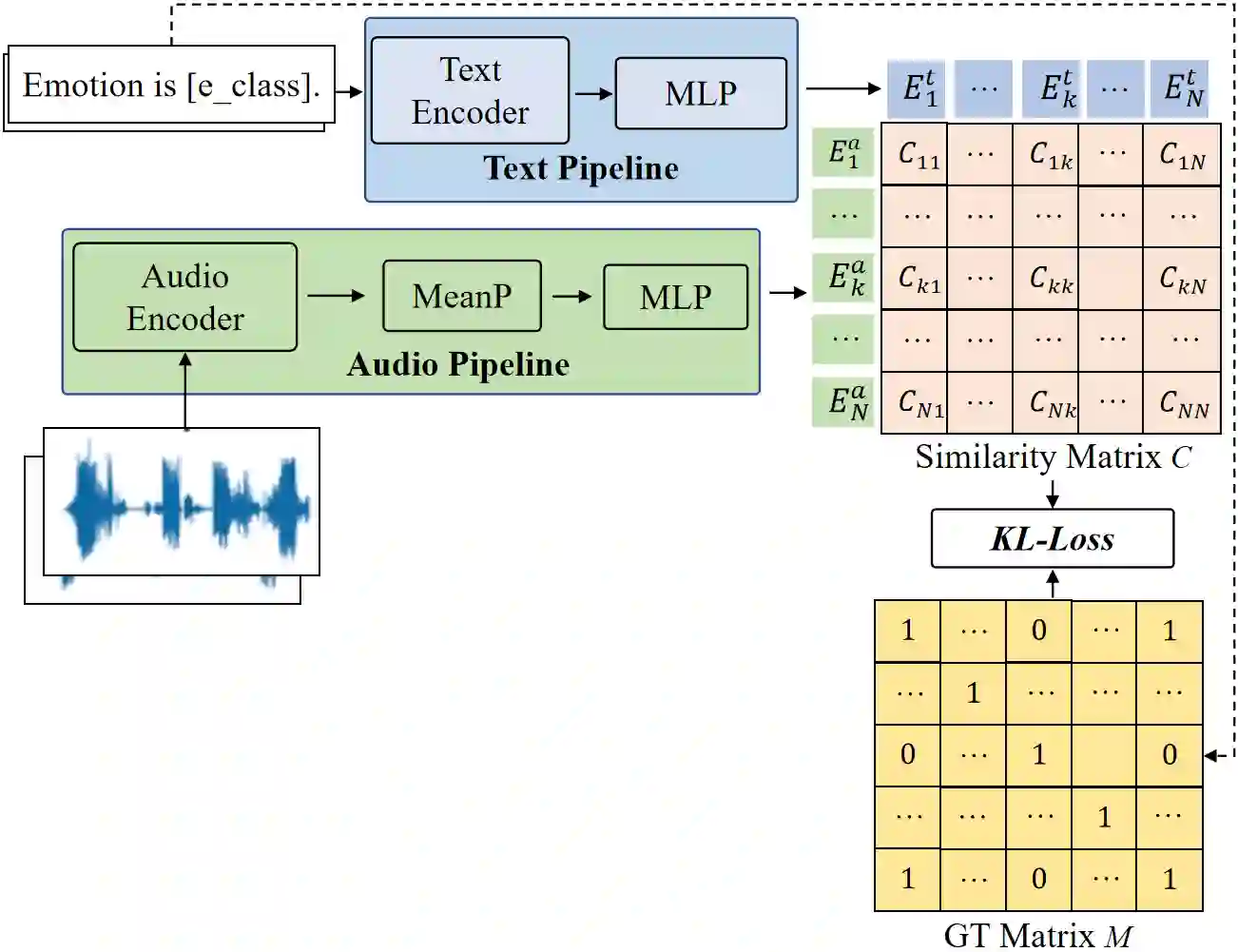
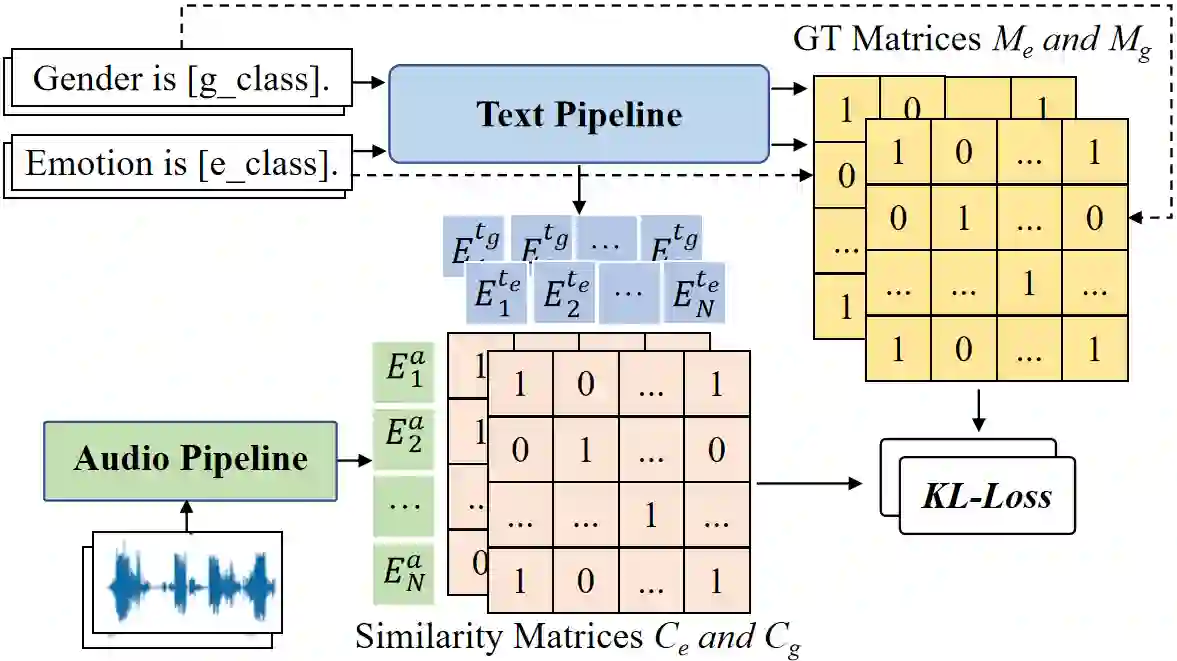
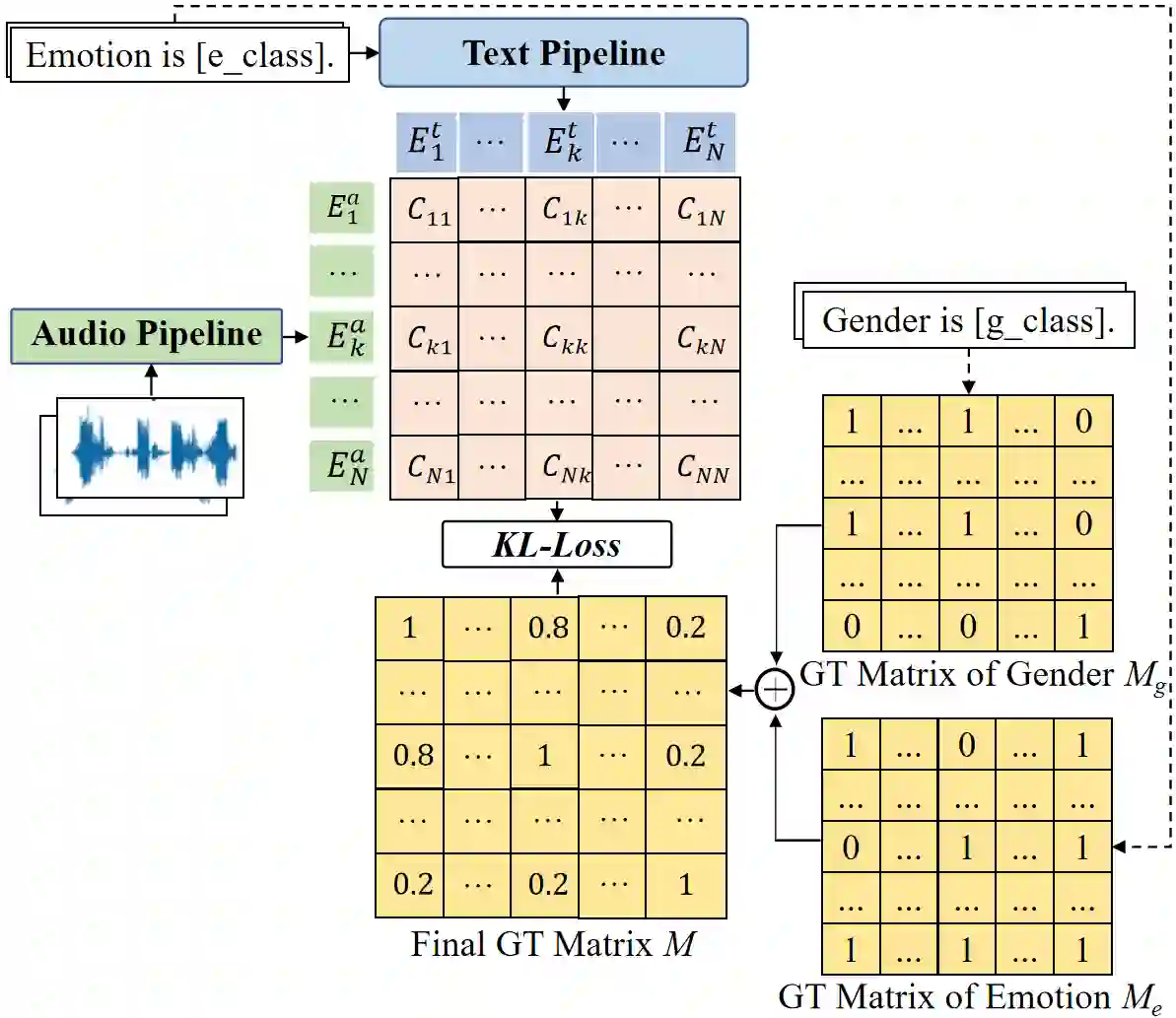
Contrastive cross-modality pretraining has recently exhibited impressive success in diverse fields, whereas there is limited research on their merits in speech emotion recognition (SER). In this paper, we propose GEmo-CLAP, a kind of gender-attribute-enhanced contrastive language-audio pretraining (CLAP) method for SER. Specifically, we first construct an effective emotion CLAP (Emo-CLAP) for SER, using pre-trained text and audio encoders. Second, given the significance of gender information in SER, two novel multi-task learning based GEmo-CLAP (ML-GEmo-CLAP) and soft label based GEmo-CLAP (SL-GEmo-CLAP) models are further proposed to incorporate gender information of speech signals, forming more reasonable objectives. Experiments on IEMOCAP indicate that our proposed two GEmo-CLAPs consistently outperform Emo-CLAP with different pre-trained models. Remarkably, the proposed WavLM-based SL-GEmo-CLAP obtains the best UAR of 81.43\% and WAR of 83.16\%, which performs better than state-of-the-art SER methods.
翻译:跨模态对比预训练近年来在多个领域取得了显著成功,然而其在语音情感识别(SER)中的优势研究仍较为有限。本文提出GEmo-CLAP——一种面向SER的性别属性增强对比语言-音频预训练(CLAP)方法。具体而言,我们首先利用预训练的文本和音频编码器构建了有效的SER情感对比学习模型(Emo-CLAP);其次,鉴于性别信息在SER中的重要性,进一步提出了两种新颖的模型——基于多任务学习的GEmo-CLAP(ML-GEmo-CLAP)和基于软标签的GEmo-CLAP(SL-GEmo-CLAP),以融合语音信号的性别信息,形成更合理的优化目标。在IEMOCAP上的实验表明,本文提出的两种GEmo-CLAP方法在使用不同预训练模型时均一致优于Emo-CLAP。值得注意的是,所提出的基于WavLM的SL-GEmo-CLAP取得了最佳未加权平均召回率(UAR)81.43%和加权平均召回率(WAR)83.16%,性能优于当前最先进的SER方法。