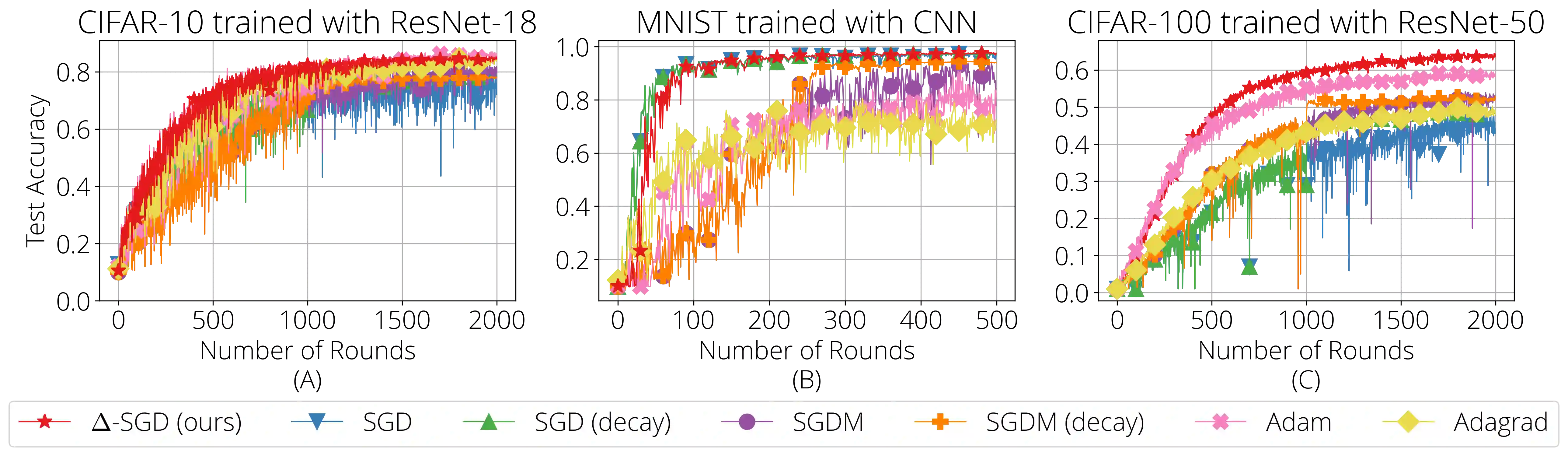
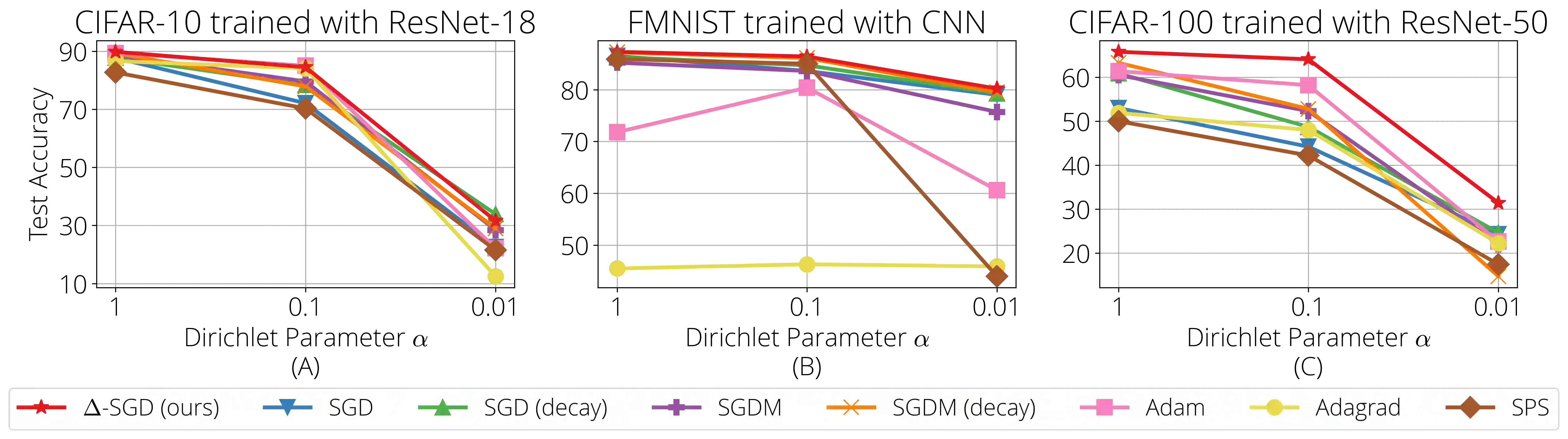
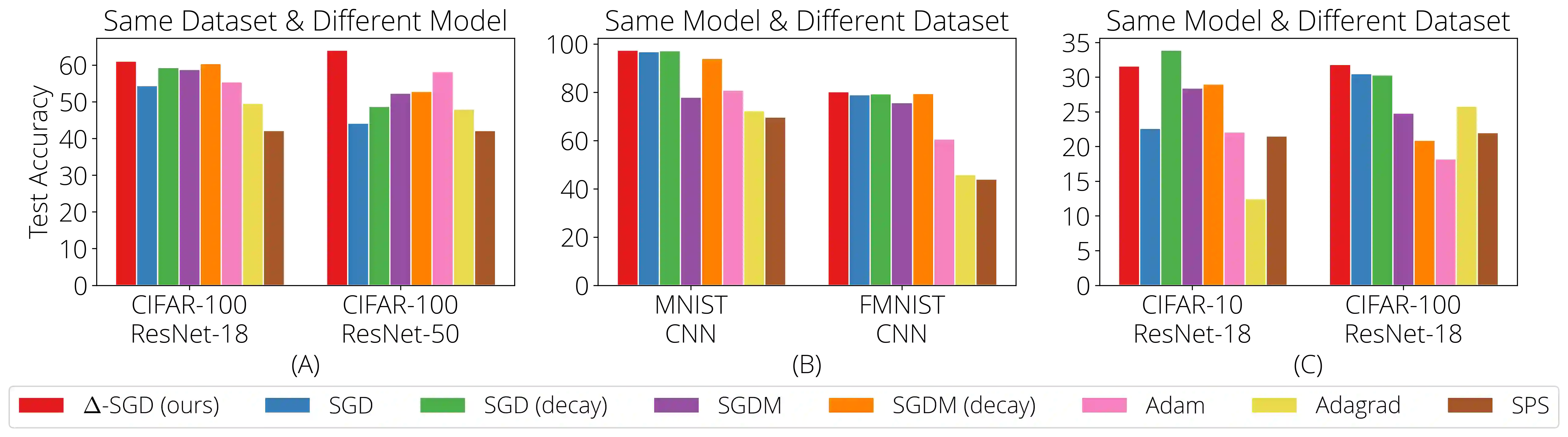
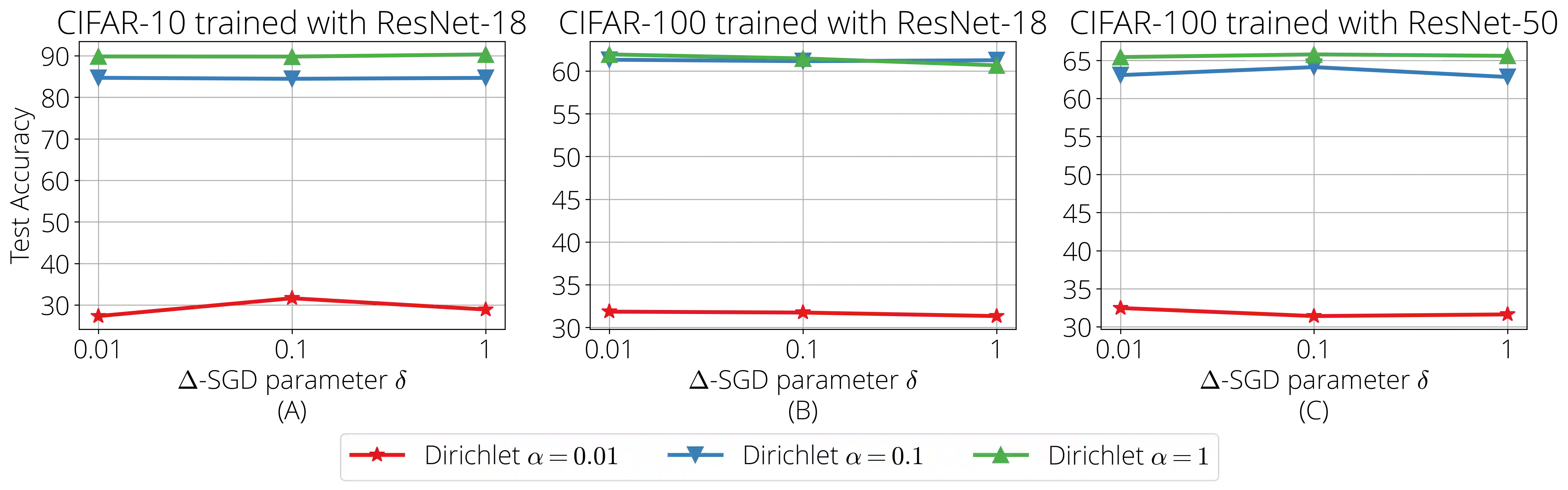
Federated learning (FL) is a distributed machine learning framework where the global model of a central server is trained via multiple collaborative steps by participating clients without sharing their data. While being a flexible framework, where the distribution of local data, participation rate, and computing power of each client can greatly vary, such flexibility gives rise to many new challenges, especially in the hyperparameter tuning on the client side. We propose $\Delta$-SGD, a simple step size rule for SGD that enables each client to use its own step size by adapting to the local smoothness of the function each client is optimizing. We provide theoretical and empirical results where the benefit of the client adaptivity is shown in various FL scenarios.
翻译:联邦学习(FL)是一种分布式机器学习框架,通过参与客户端的多次协作步骤训练中央服务器的全局模型,同时无需共享各自数据。尽管该框架具有高度灵活性(各客户端的本地数据分布、参与率和计算能力可能存在显著差异),但这种灵活性也带来了诸多新挑战,尤其是在客户端的超参数调优方面。我们提出$\Delta$-SGD——一种为SGD设计的简易步长规则,使每个客户端能够根据待优化函数的局部光滑性自适应调整自身步长。我们从理论和实验两方面证明,客户端自适应机制在多种FL场景中均能带来显著优势。