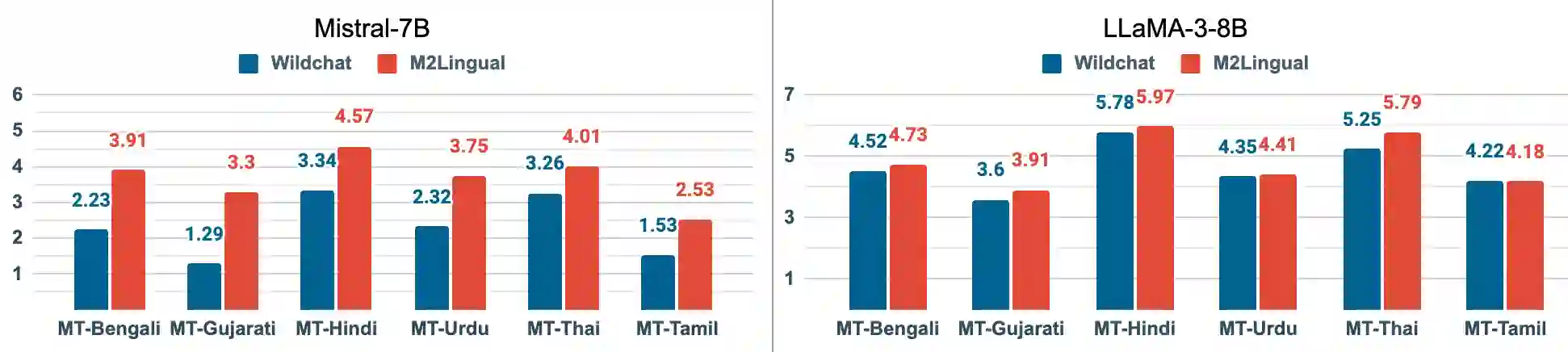
Instruction finetuning (IFT) is critical for aligning Large Language Models (LLMs) to follow instructions. Numerous effective IFT datasets have been proposed in the recent past, but most focus on high resource languages such as English. In this work, we propose a fully synthetic, novel taxonomy (Evol) guided Multilingual, Multi-turn instruction finetuning dataset, called M2Lingual, to better align LLMs on a diverse set of languages and tasks. M2Lingual contains a total of 182K IFT pairs that are built upon diverse seeds, covering 70 languages, 17 NLP tasks and general instruction-response pairs. LLMs finetuned with M2Lingual substantially outperform the majority of existing multilingual IFT datasets. Importantly, LLMs trained with M2Lingual consistently achieve competitive results across a wide variety of evaluation benchmarks compared to existing multilingual IFT datasets. Specifically, LLMs finetuned with M2Lingual achieve strong performance on our translated multilingual, multi-turn evaluation benchmark as well as a wide variety of multilingual tasks. Thus we contribute, and the 2 step Evol taxonomy used for its creation. M2Lingual repository - https://huggingface.co/datasets/ServiceNow-AI/M2Lingual
翻译:指令微调对于使大型语言模型遵循指令至关重要。近期已提出了许多有效的指令微调数据集,但大多集中于英语等高资源语言。本工作中,我们提出了一个完全合成的、基于新颖分类法指导的多语言、多轮指令微调数据集,称为M2Lingual,以更好地在多种语言和任务上对齐大型语言模型。M2Lingual共包含182K个指令微调对,这些数据对基于多样化的种子构建,涵盖70种语言、17项自然语言处理任务以及通用指令-响应对。使用M2Lingual微调的大型语言模型在性能上显著超越了大多数现有的多语言指令微调数据集。重要的是,与现有的多语言指令微调数据集相比,使用M2Lingual训练的模型在各种评估基准上始终取得具有竞争力的结果。具体而言,使用M2Lingual微调的模型在我们构建的翻译版多语言、多轮评估基准以及广泛的多语言任务上均表现出强劲性能。因此,我们贡献了该数据集及其创建所使用的两步Evol分类法。M2Lingual存储库地址:https://huggingface.co/datasets/ServiceNow-AI/M2Lingual