基于大语言模型(LLM)的多智能体系统(Multi-agent systems, MAS)在处理复杂协作任务方面展现出巨大潜力,其中智能体通常通过特定角色提示词进行编排。尽管这些提示词的质量至关重要,但在交互智能体之间对其进行联合优化仍然是一项非平凡的挑战,其主要原因在于局部智能体目标与整体系统目标之间存在不一致。为此,我们提出了 MASPO,这是一个旨在跨整个系统自动、迭代地优化提示词的新型框架。MASPO 的核心创新在于其联合评估机制:该机制评估提示词时并不仅仅关注其局部有效性,而是关注其促进后继智能体取得下游成功的能力。这种方式无需依赖真实标签,便能有效弥合局部交互与全局结果之间的差距。此外,MASPO 采用一种数据驱动的进化式束搜索,以高效探索高维提示词空间。在 6 个多样化任务上的大量实证评估表明,MASPO 持续优于最先进的提示词优化方法,平均准确率提升达到 2.9。我们的代码已发布于:https://github.com/wangzx1219/MASPO。
1. 引言
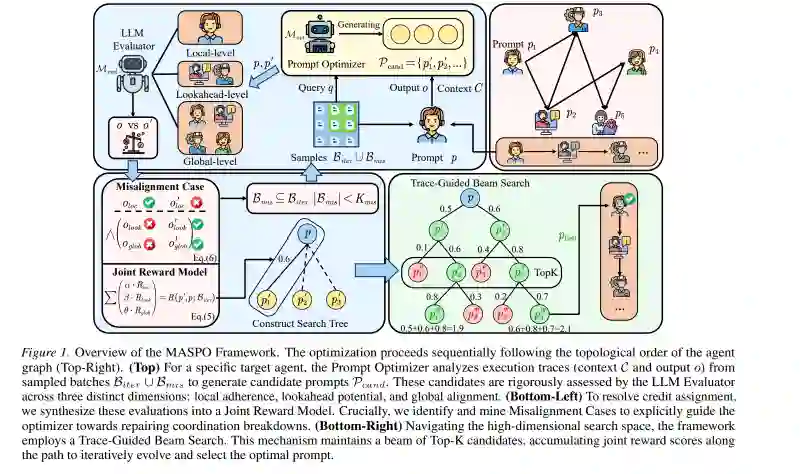
近年来,LLM 的进展(Achiam et al., 2023; Team et al., 2024)展现出卓越的上下文理解、指令遵循和复杂推理能力,在各种任务和场景中表现出强劲性能。在这些基础之上,多智能体系统(MAS)已成为解决多阶段问题的一种强大范式。通过编排异构智能体(Liang et al., 2024; Wang et al., 2025a; Du et al., 2024; Zhuge et al., 2024)进行通信与协作,MAS 往往能够超越单智能体对应方法的能力。在此类系统中,面向特定智能体的提示词设计至关重要,因为它们不仅定义了每个智能体的不同角色,还支配其交互动态和推理轨迹。然而,尽管这些提示词具有关键重要性,对其进行联合优化仍是一项非平凡挑战。不同于单智能体场景,MAS 优化涉及一个组合式搜索空间,其中某一智能体提示词的最优性本质上依赖于其他智能体的行为。 通常,MAS 通过专门化智能体之间的协作运行。现有提示词优化方法通常依赖标注数据来评估提示词质量,但这一范式并不适用于 MAS(Fernando et al., 2024a; Yuksekgonul et al., 2024)。在协作设置中,特定智能体可能被分配执行中间步骤,例如推理、反思或摘要,而不是生成最终输出。这会导致严重的信用分配问题。MAS 中一种关键失效模式是局部—全局不一致(Local-Global Misalignment):中间智能体完全满足其局部指令,却生成了会误导下游同伴的输出,最终导致整个系统失败。尽管近期的自监督策略(Xiang et al., 2025)利用比较反馈来评估推理质量,但它们仍局限于孤立范围,无法捕捉局部变化如何传播并影响全局系统结果。在 MAS 背景下,近期工作(Opsahl-Ong et al., 2024; Zhou et al., 2025)引入了利用树结构 Parzen 估计器(Tree-structured Parzen Estimators, TPE)的贝叶斯搜索策略。然而,这些方法受限于从固定的离散候选池中选择提示词,从而限制了其进行开放式优化和细粒度调整的能力。因此,亟需一个稳健框架,能够在动态多智能体环境中自动化生成提示词。 为应对这些挑战,我们提出 MASPO,这是一个面向多智能体环境量身定制的联合提示词优化框架。MASPO 引入了三项关键创新。首先,为解决信用分配困境,我们设计了一种多粒度联合评估机制,将局部有效性(Local Validity)、前瞻潜力(Lookahead Potential)和全局对齐(Global Alignment)相结合,通过智能体对整个因果链的贡献而非孤立输出来评估其效用。其次,我们提出不一致感知采样(Misalignment-Aware Sampling),这是一种有针对性的技术,能够显式挖掘并注入历史轨迹:在这些轨迹中,尽管局部任务成功,但协作最终失败,从而引导优化器诊断并纠正具体的交互失效。第三,针对协同适应协议,我们实现了一种坐标上升式策略,并辅以束刷新(Beam Refresh)机制;该机制通过实时重新对齐每个智能体的搜索树来确保稳定性,从而缓解由同伴智能体变化引起的非平稳性。 在多个不同领域开展的大量实验表明,MASPO 相较于现有基线方法能够持续带来显著性能提升。我们的主要贡献总结如下:
- 多粒度联合评估:我们提出一种复合评估指标,用以解决 MAS 中的信用分配困境。通过协同结合局部有效性、前瞻潜力和全局对齐,我们的方法能够捕捉智能体在协作链中的完整因果影响。
- 不一致驱动的生成式搜索:我们设计了一种由“不一致案例”(Misalignment Cases)显式引导的束搜索策略,即智能体满足局部角色要求但诱发系统级失败的场景。
- 自适应优化动态:我们提出一种基于坐标上升的调度协议,并辅以束刷新机制。这些技术能够有效缓解多智能体交互中固有的非平稳性,确保每个智能体适应其同伴不断演化的行为。