
Abstract: 基于LLM的代理系统,特别是通过MCP和A2A等协议进行规划、调用工具、维护持久记忆并将任务委托给同行代理的系统,引入了一种与独立模型推理截然不同的威胁面。代理会积累敏感上下文、持有凭证,并在没有任何单一主体完全控制的管道中运行,从而引发提示注入、上下文泄露、凭证盗窃和代理间消息中毒等威胁。当前的防御措施完全运行在软件栈内,可以被具有足够权限的攻击者(如被攻破的云运营商)悄然绕过。机密计算(CC)提供了一种基于硬件的替代方案:可信执行环境(TEE)将代理代码和数据与特权系统软件隔离,而远程认证则能够在分布式部署中实现可验证的信任。本文综述从四个部分综合了设计空间:一种统一的六种TEE平台分类法、一种基于代理中心的威胁模型、一种基于CC的防御的比较调查,以及六个开放挑战。尽管多种硬件信任原语已足够成熟用于针对性部署,但尚无广泛建立的端到端框架将其绑定为生产级代理AI的一致安全基板。
Introduction / 引言
大语言模型(LLM)正越来越多地被部署为代理系统的组成部分,这些系统执行规划、调用外部工具、维护持久记忆,并在多步骤的时间范围内代表用户行动。从无状态推理向自主代理的转变从根本上改变了安全问题。代理会在多个会话中积累敏感的用户上下文,持有服务凭证,调用真实世界的API,并与同行代理在没有任何单一主体完全控制的管道中进行通信。 这种扩展的操作范围创造了一个软件层防御难以应对的威胁面。嵌入在检索文档中的提示注入攻击可以劫持代理的规划循环,将其工具调用重定向到攻击者控制的端点。受损的云运营商可以检查模型权重、泄露对话历史,或悄悄修改传输中的工具输出。在多代理系统中,单个恶意代理可以破坏整个协作管道的推理过程。 近期的安全事件表明,这些威胁是实际存在而非假设性的。2025年的EchoLeak漏洞(CVE-2025-32711)展示了单个恶意邮件如何能在无需用户交互的情况下悄悄触发Microsoft Copilot泄露敏感数据。对无沙箱代理运行时的实证评估发现,超过75%的对抗性shell命令在面对缺乏运行时隔离的代理时都能成功执行。 现有缓解措施,包括提示防御、输出分类器、函数调用沙箱和代理隔离策略,完全在软件栈内运行。它们有一个共同限制:拥有足够权限低于软件边界的攻击者可以绕过它们。拥有虚拟机监控器访问权限的云提供商可以以明文读取LLM权重和用户上下文,无论应用层保护如何。密码学方法如全同态加密(FHE)和安全多方计算(MPC)提供了严谨的数学保证,但会带来两到四个数量级的额外开销,使其对十亿参数的交互式工作负载不切实际。 机密计算(CC)针对这一差距:数据使用中缺乏硬件强制保护。可信执行环境(TEE)提供硬件强制隔离,将代码和数据与特权系统软件(包括虚拟机监控器和操作系统)隔离,并启用远程认证——一种远程验证方可以通过它加密验证特定、预期的代码正在真实的TEE上以已知安全配置执行,然后才向其发送任何敏感数据的机制。 本文的主要贡献在于综合、比较分析和问题框架:(i)统一的TEE平台分类法和比较综述;(ii)基于代理中心的威胁模型;(iii)CC防御的比较调查;(iv)开放研究挑战的综合。
Scope, Methodology, and Analytical Lens / 范围、方法与分析透镜
Scope / 范围
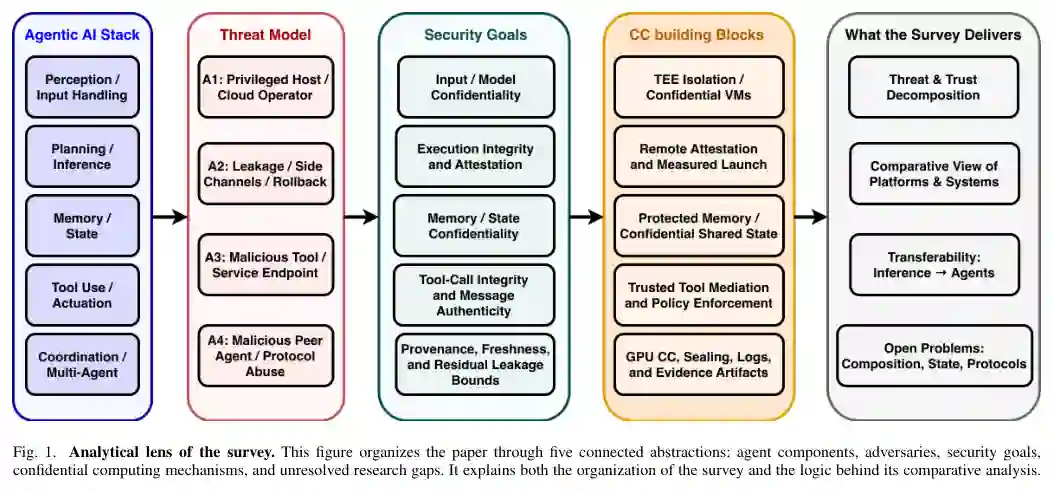
本文研究机密计算作为代理AI的基于硬件的防御基板,针对云、边缘和异构部署中的特权基础设施攻击者。研究范围有意比一般代理安全工作更窄:我们聚焦于硬件隔离和远程认证、受保护的内存和工具执行,以及跨代理信任建立。纯软件防御、对齐方法以及FHE和MPC等密码学计算机制仅作为比较点出现。 本综述贯穿使用三个分析维度:功能代理层(感知、规划、记忆、行动和协调)、攻击者权限(外部攻击者、受损共租户、恶意基础设施操作者和受损同行代理)和部署边界(进程级飞地、机密VM、安全世界或领域隔离以及CPU到GPU机密执行)。 我们还区分四个操作类别:独立推理系统、使用工具的单一代理、工作流代理和多代理系统。目前大部分证据来自机密LLM推理,这为感知和规划层的机密性提供了信息,但对定义更广泛代理栈的记忆、行动和协调问题只有部分可迁移性。 Fig. 1. Analytical lens of the survey. This figure organizes the paper through five connected abstractions: agent components, adversaries, security goals, confidential computing mechanisms, and unresolved research gaps. It explains both the organization of the survey and the logic behind its comparative analysis.
Corpus and Classification Protocol / 语料库与分类协议
本文是一个结构化综述,其严谨性依赖于透明的语料库和明确的编码规则。文献分三个阶段收集:从机密LLM推理、代理安全研究和主要平台或协议文档中获取种子集;向后和向前雪球搜索;及对特定术语进行针对性关键词搜索。 引用的文献被分为核心分析语料库和上下文语料库。每篇保留的核心论文按TEE基板、操作类别、受保护代理层、攻击者类别、安全目标、保护范围和转移状态进行编码。系统仅在保护实际工具使用、工作流执行、持久记忆处理或代理间协调时才被标记为直接面向代理;否则被视为部分可迁移。
Security Goal Taxonomy / 安全目标分类法
为避免“机密性”、“完整性”和“信任”等术语使用过于宽泛,本文使用九个安全目标类别:
- 输入机密性 在模型摄入之前和期间保护用户提示、检索文档和工具输入
- 模型机密性 保护权重、系统提示和其他专有推理工件不被泄露
- 执行完整性 确保经过认证的代码路径和运行时状态是依赖方所期望的
- 内存机密性 保护临时和持久代理状态,包括KV缓存、对话历史和向量存储
- 工具调用完整性 确保工具调用及其参数不被基础设施攻击者篡改,并仅在预期策略下释放
- 消息真实性 确保代理间或代理到工具的消息源自声称的发送方
- 来源 捕获消息、工具输出或委派结果来自何处以及哪些经过认证的组件影响了它
- 新鲜性 确保认证证据、委派声明和返回的结果是及时的而非重放的或过时的
- 侧信道抵抗 对抗通过时序、缓存、总线、页错误或相关微架构信号的信息泄露
这些类别刻意比完整的代理安全更窄,描述了所审查CC系统试图提供的具体安全属性。
What Counts as Agentic AI / 什么被视为代理AI
我们采用以下定义,与近期分类法一致:代理AI系统是由LLM驱动的实体,通过迭代规划循环、调用外部工具、读取和写入持久内存存储并与同行代理协调,在步骤间有限或无人工干预的情况下自主执行多步骤任务。 我们将代理分解为五个功能层,它们作为威胁模型的组织结构:
- 感知(Perception) 代理摄取输入:用户消息、检索文档、工具响应和代理间消息
- 规划/推理(Planning/Reasoning) LLM核心处理累积上下文并生成计划:工具调用序列、代码生成任务或子任务委派
- 记忆(Memory) 代理维护多个记忆层级:短期上下文、长期向量存储(通过RAG访问)、情景记忆和参数化记忆
- 行动/工具执行(Action/Tool Execution) 代理调用外部能力:网络搜索、代码执行、数据库查询、API调用和文件系统访问
- 协调(Coordination) 在多代理系统中,代理通过结构化协议进行通信和委派任务。MCP已成为广泛使用的代理到工具通信接口,而A2A协议补充了MCP,实现跨组织和平台边界的代理到代理委派
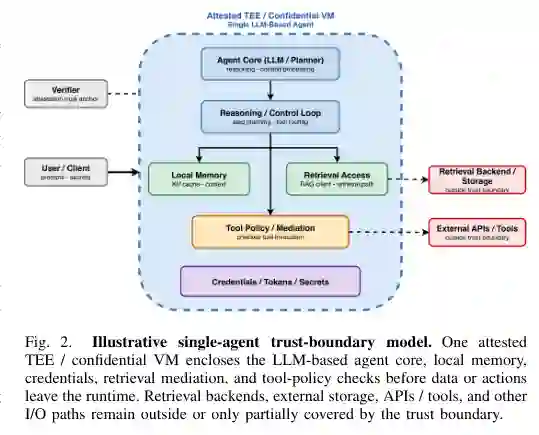
Fig. 2. Illustrative single-agent trust-boundary model. One attested TEE / confidential VM encloses the LLM-based agent core, local memory, credentials, retrieval mediation, and tool-policy checks before data or actions leave the runtime. Retrieval backends, external storage, APIs / tools, and other I/O paths remain outside or only partially covered by the trust boundary.
Targeted TEE Primer / 针对性TEE入门
机密计算通过在工作负载在硬件强制TEE内执行来保护使用中的数据。对于当前目的,只有三个平台属性需要预先了解:信任边界、认证模型和部署场景。 讨论的平台属于四种设计点:INTEL SGX在飞地内保护选定的应用组件,是最窄的信任边界;INTEL TDX和AMD SEV-SNP将边界移至VM级别,更适合完整代理服务的提升与转移保护;ARM TrustZone和ARM CCA代表Arm谱系,TrustZone在边缘和移动环境中广泛使用,而CCA在较新Arm平台上增加了基于领域的隔离;NVIDIA H100 CC将机密性扩展到GPU内存和执行。 远程认证将本地隔离转变为分布式信任机制:验证方可以基于测量的代码和平台状态决定是否释放秘密、授权工具访问或接受委派结果。
Agent-Centric Threat Model / 代理中心威胁模型
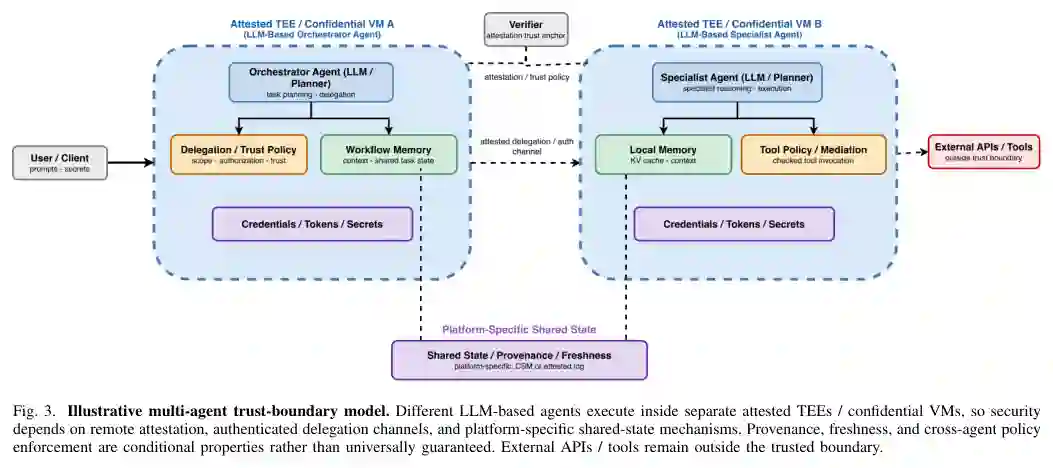
What Makes Agents a Distinct Security Problem / 代理为何构成独特安全问题
一个自然的问题是代理安全是否可归结为熟知的云服务安全。代理与微服务共享许多相同的基础设施,但四个结构性属性创造了一个微服务模型难以处理的安全问题: 控制平面通过数据可被语义操纵:在微服务中,应用逻辑是确定性代码,与处理的数据明确分离。在代理中,LLM本身就是控制平面,其决策基于输入上下文内容。嵌入检索语料库中的恶意文档可以重定向代理的整个工具调用和委派行为,而不触及任何身份验证边界。 授权是隐式的而非语法的:微服务在类型化的API边界强制执行授权。代理的有效授权却嵌入自然语言中:系统提示、用户指令和累积的对话上下文。攻击面在于数据的意义,而非其来源或格式。 状态是无界、累积且长期存在的:代理跨会话积累敏感上下文。LeftoverLocals漏洞展示了共享GPU内存中的KV缓存残留使共租户攻击者能够跨会话重建完整对话。 多代理委派缺乏意图传递性:当编排代理委派给专门代理时,用户原始意图和授权范围仅作为自然语言存在于上下文窗口中,每个中间代理都可以悄悄修改、误解或注入。目前没有标准机制能证明工具服务器执行的最终操作保持在用户最初授权编排代理委派的范围内。
Adversary Model / 攻击者模型
我们考虑四个攻击者类别,强度递增:
- A1:外部攻击者 - 不控制任何特权软件,可构造恶意输入并观察输出侧信道
- A2:受损共租户 - 控制同一云环境中的共置工作负载,可发动跨VM侧信道攻击,但无虚拟机监控器级访问权限
- A3:恶意基础设施操作者 - 控制虚拟机监控器、云管理平面和物理硬件配置,可读取和修改未保护的VM内存、拦截未加密的I/O、操纵调度。这是CC设计主要防御的攻击者
- A4:受损代理 - 一个或多个代理在多代理管道中被攻破,可将虚假上下文注入共享内存、伪造代理间消息、操纵合法同行的编排决策
CC防御直接应对A3,对A2提供有意义的保护,并为A4建立可认证的信任边界。它们不能阻止提示注入的语义效果(A1)。
Protected Assets, Trust Assumptions, and Attack Surface / 受保护资产、信任假设与攻击面
主要受保护资产包括:感知边界的用户提示、检索文档和工具输入;规划层的模型权重、系统提示和微调适配器;内存中的运行时状态如KV缓存、对话历史、向量存储内容和服务凭证;行动边的工具调用、工具参数和工具输出;协调边的代理间消息、委派声明、来源元数据和认证证据。 威胁模型做出四个信任假设:TEE硬件信任根按架构规范运行;认证边界内的测量代码是依赖方意图信任的代码;标准密码学原语未被破解;验证方正确检查认证结果、新鲜性和策略约束。 主要攻击面包括:输入摄入路径、模型服务路径、持久和临时内存状态、CPU-GPU传输路径、存储快照、工具调用接口、代理间消息通道、认证和重放处理逻辑,以及跨层元数据。
Per-Layer Threat Analysis / 逐层威胁分析
第1层:感知 - 威胁包括通过检索文档和工具输出进行的间接提示注入、RAG管道中外部知识源的投毒、传输中或未保护内存缓冲区中对用户输入的窃听。CC覆盖:对基础设施操作者(A3)最直接的输入机密性保护,以及摄入路径执行完整性的部分保护。对模型行为的语义注入效果(A1)仍在CC范围之外。 第2层:规划/推理 - 威胁包括通过操纵上下文进行的目标劫持、特权操作者的模型权重提取、系统提示泄露、通过多轮提示构造进行的越狱。CC覆盖:最直接的模型机密性和执行完整性保护。远程认证提供关于代码身份和配置的证据。 第3层:记忆 - 威胁包括基础设施操作者(A3)对长期向量存储的未授权读取、使完整对话重建成为可能的KV缓存泄露、多租户内存池中的跨用户污染、受损同行代理(A4)对情景记忆的投毒。CC覆盖:针对A3最直接的内存机密性保护,但对共享内存状态的来源、新鲜性和多租户隔离仅有部分保护。 第4层:行动/工具执行 - 威胁包括代理持有的服务凭证泄露给特权操作者(A3)、LLM生成的恶意代码在隔离沙箱外执行、工具响应被中间人修改。CC覆盖:最直接的工具调用完整性、执行完整性和内存中凭证保护。Omega平台展示了在机密代理运行时内的认证门控工具访问控制。 第5层:协调 - 威胁包括基础设施操作者(A3)窃听代理间消息、代理冒充(A4)、MCP中的协议级注入漏洞、多跳委派链中的信任传递性滥用。CC覆盖:对消息真实性和来源最直接的覆盖,以及当认证和重放保护正确组合时的新鲜性部分覆盖。CAEC能够在相互认证的CCA领域之间实现机密共享内存。协议级注入(A1)和多跳认证传递性(A4)仍是开放问题。
Coverage Summary / 覆盖总结
威胁到防御的覆盖矩阵将这一威胁模型操作化,展示代表性系统如何映射到五个代理层,以及当前调查的防御仍留下哪些主要空白。考虑的系统包括TEESlice、CMIF、TEECHAT、Omega、AttestMCP、CAEC和BlockA2A,它们在不同层提供直接或部分覆盖,但侧信道抵抗普遍是空白,且许多系统仅覆盖部分安全目标。
What Confidential Computing Does Not Solve / 机密计算未解决的问题
CC主要针对特权基础设施攻击者的安全目标子集:输入机密性、模型机密性、执行完整性、内存机密性、工具调用完整性、消息真实性、来源、新鲜性和部分侧信道抵抗。它不是代理安全、模型鲁棒性或端到端系统可信任性的一般解决方案。
- 语义错位与不安全目标 如果代理指定有误,TEE会忠实地执行有缺陷的行为
- 可信但恶意的或误导性输入 经过认证的身份不等于真实性或安全性;检索文档仍可能包含对抗性内容
- 可用性与拒绝服务 云操作者可拒绝调度、限速、终止或回滚
- 超出架构模型的侧信道 TEE不消除许多微架构和物理泄露通道
- 模型供应链妥协 认证不建立测量前工件的来源或完整性
- 数据离开信任边界后的安全 CC仅保护数据在信任边界内;下游滥用由协议设计、访问控制等决定
Related Work / 相关工作
先前工作分为四个部分重叠的线索:代理安全调查、机密计算调查、TEE针对ML和LLM推理的工作,以及代理通信的协议级安全分析。 代理AI安全调查:He等人、Yu等人和Deng等人对LLM代理中的安全与隐私问题、可信LLM代理、攻击与防御格局进行了调查,为威胁模型和分层分解提供了重要输入,但重点在攻击分类法和软件层防御。 机密计算调查:Zobaed和Salehi、Feng等人提供了TEE架构、认证机制和跨更广泛CC格局的部署权衡,但对代理系统的处理是广泛的,代理系统不作为第一类组织类别。 TEE针对ML和LLM推理工作:CMIF、TEESlice、TEECHAT及相关系统在单次推理期间保护模型权重和用户输入,为感知和规划层保护提供了最有力证据,但向记忆、行动和协调的迁移是部分和特定层的。 MCP和A2A的协议安全工作:Kong等人专注于代理通信协议的安全风险,AttestMCP及相关分析暴露了能力认证、来源认证和来源空白,为协调威胁模型提供了补充视角。 本综述的位置在于这四个线索的交集,将代理AI而非通用AI工作负载或协议设计本身作为组织问题,并比较平台、防御、覆盖边界和整个代理栈的开放问题。
Survey of CC for Core Agent Components / 核心代理组件的机密计算综述
Practical TEE Limitations for Agentic Systems / 面向代理系统的实际TEE限制
CC保护声明总是受到一组实际限制的制约,这些限制对代理AI尤为突出:
- 侧信道与受控泄露 推理和代理运行时仍可能通过时序、缓存争用、内存总线行为、页错误模式、推测执行效果或GPU残留状态泄露信息
- 回滚、重放与过时状态 许多TEE部署提供代码身份但对状态连续性保证较弱,除非叠加新鲜性和单调状态机制
- 加速器与I/O边界泄露 现代代理很少在纯CPU信任边界内运行,它们依赖GPU、存储路径、网络通道和工具面对I/O栈
- 元数据泄露与工作流可观察性 基础设施攻击者可能从元数据中学习敏感信息
- 可用性限制与运行脆弱性 TEE系统仍然易受拒绝服务、资源饥饿、认证服务中断等影响
Standalone LLM Inference as a Precursor / 独立LLM推理作为前驱
保护模型推理是CC用于AI系统的常见起点。大多数此小节中的系统并非完整意义上的代理:它们保护独立的推理会话或聊天服务,而非自主、使用工具、多步骤的代理。 CPU-TEE方法:Slalom将批量矩阵乘法操作委派给不可信GPU,同时CPU端TEE加密验证结果。TEECHAT在Azure机密VM上展示了端到端私有LLM聊天,在大模型上开销可忽略。 GPU-TEE方法:CPU到GPU信任扩展通过在数据穿越PCIe互连之前加密数据来实现。在INTEL TDX和NVIDIA H100 CC平台上的基准测试报告了仅4-8%的吞吐量惩罚,随批量增大而减小。 模型分区:TEESlice展示了隐私敏感信息集中在少量可识别的模型层中。仅隔离此子集可达到强隐私保证,为代理部署提供了潜在有用设计模式。 部分TEE屏蔽的漏洞:2026年的结果展示了预计算静态秘密基的密钥重用漏洞,可在约6分钟内恢复LLaMA-3 8B模型的秘密排列和权重。
Protecting Agent Memory / 保护代理内存
代理记忆是代理栈中价值最高的目标之一:长期向量存储积累数月的专有交互,微调适配器编码机密领域知识,KV缓存包含逐字对话重建。 KV缓存保护:LeftoverLocals漏洞展示了共享GPU内存允许共租户攻击者读取KV缓存内容。基于TEE的KV保护通过ARM TrustZone处理KV对,但受限于安全世界的约束内存预算。 多租户向量存储:协作记忆提出共享RAG内存池上的动态访问控制,将其扩展到TEE支持的向量存储是一个自然但目前未实现的方向。
Tool-Using and Workflow Agents / 使用工具与工作流代理
工具使用和工作流代理是本节中第一个直接面向代理的类别。主要保护目标转向执行完整性、工具调用完整性,以及委派工作流中的消息真实性和来源。 Omega平台:作为当前文献中较全面的CC代理运行时之一,Omega在AMD SEV-SNP机密VM内部署了一个工具使用代理,该代理生成并执行Python代码、运行shell命令、调用REST API并执行多步推理。它通过仅允许对经过认证和完整性验证的Python代码进行执行的策略来保护工具调用完整性。但是其外部工具交互依赖API密钥和秘密管理,这些机制本身的安全属性取决于底层的CC平台和密钥管理基础设施。
Platform-Specific Deployment Tradeoffs / 平台特定部署权衡
本节详细比较六种TEE平台在代理部署中的特性。
Intel SGX / 英特尔软件保护扩展
提供进程级飞地,最窄的信任边界。对于想要隔离代理栈中一个小型可信组件的部署具有吸引力,例如凭证管理器或策略引擎。但在机密VM上运行的代理运行时需要在飞地中容纳整个LLM,受到飞地内存大小和昂贵的飞地转换的限制。
Intel TDX / 英特尔信任域扩展
将信任边界移至VM级别。支持更大的组件(如完整的LLM运行时)映射到单一信任边界内,无需显式将代码重构为压缩飞地。但TDX引入更广泛的TCB,因为它信任整个VMM的机密部分。
AMD SEV-SNP / AMD安全加密虚拟化-安全嵌套分页
提供类似的VM级机密性,具有反向映射和嵌套分页支持。SEV-SNP在虚拟化工作流和用户空间隔离之间取得了不同平衡,不依赖于特定于Intel的飞地范式。
ARM TrustZone / ARM安全区
在移动和边缘代理部署中广泛使用,提供安全世界与普通世界的隔离。适合资源受限的客户端设备,安全世界有严格的内存预算。
ARM CCA / ARM机密计算架构
在Armv9-A中引入四世界隔离模型,通过领域管理器减少TCB。为云和边缘工作负载提供了更灵活、隔离更强的隔离模型。
NVIDIA H100 Confidential Compute / NVIDIA H100机密计算(NCC)
将信任边界扩展到GPU内存和执行。通过计算保护区域(CPR)在工作负载驻留在GPU HBM时提供内存机密性和完整性。然而,GPU TEE不能作为独立信任锚点;它依赖CPU端CC根(如TDX或SEV-SNP)来实现端到端系统信任。
Comparative Takeaway / 比较总结
平台格局不是简单的从最好到最差的排序。细粒度TEE如SGX对有小型可信组件的部署有吸引力,机密VM运行时如TDX和SEV-SNP更适合可部署的云运行时,加速器支持的机密执行如H100 CC适合GPU重数据中心环境的大模型推理。ARM TrustZone在边缘和设备部署中最自然,而ARM CCA代表跨越边缘和云用例的新兴领域/CVM模型。
Cross-Cutting Design Lessons / 跨领域设计经验
平台选择不意味着自动获得端到端安全。每个平台自己的信任边界保护某些组件但不保护整个代理管道。TEE使用引入了新的操作脆弱性。性能开销取决于工作负载特征。来自不同平台的认证证据需要一致的解释框架。超出现有架构模型的侧信道仍然存在。
Multi-Agent Coordination and Confidential Computing / 多代理协调与机密计算

Protocol-Level Vulnerabilities in MCP and A2A / MCP和A2A的协议级漏洞
在标准协议分析之外,几项研究调查了MCP和A2A中可被代理工作流中的基础设施攻击者利用的特定协议级漏洞。工具和资源接口中的脆弱性位于控制平面和数据平面的交叉点,使得注入和信任传递性问题尤为严重。 MCP中的授权是隐式的而非语法层的,无法通过签名防止注入。在多代理系统中,单恶意代理可毒害整个协作管道。AttestMCP通过将TEE认证添加到MCP请求中来解决此问题,但当前实现扩展到工具调用会话,且不直接证明工具服务器本身的安全态势。
Inter-Agent Trust via Attestation / 通过认证建立代理间信任
一旦多个代理在分离的TEE上执行,它们必须建立相互信任。远程认证可在完全陌生的机器之间建立信任。实际推进需要引入可信代理中继点,并在安全通信中建立合理的轮次。新鲜性是另一个主要问题:持有过期认证证据的代理仍是足够强大的对手。
Confidential Shared Memory for Multi-Agent Systems / 多代理系统的机密共享内存
CAEC是在ARM CCA领域内为多代理工作负载提供机密共享内存的主要代表之一。尽管CAEC本身是一个小规模演示,但它说明了共享内存方法在大规模下的结构限制。共享内存原语要求所有参与者位于同一领域,限制了可扩展性。 Fig. 4. Platform landscape for confidential computing in agentic AI. The surveyed platforms occupy different regions of the deployment space rather than forming a simple best-to-worst ranking. Fine-grained TEEs such as Intel SGX are often attractive for small trusted components, confidential- runtime platforms such as Intel TDX and AMD SEV-SNP are better suited to deployable cloud runtimes, and accelerator-backed confidential execution such as NVIDIA H100 CC is relevant for large-model inference in GPU-heavy datacenter settings. ARM TrustZone remains most natural for edge and device deployments, while ARM CCA represents an emerging Arm realm/CVM model spanning edge and cloud use cases. Positions are illustrative and qualitative, emphasizing typical deployment niches rather than a quantitative ranking or maturity ordering. Accelerator-backed platforms such as NVIDIA H100 CC typically rely on a CPU-side confidential computing root (e.g., TDX or SEV-SNP) for end-to-end system trust and do not act as standalone trust anchors.
Open Research Challenges / 开放研究挑战
Compound Attestation for Multi-Hop Agent Chains / 多跳代理链的复合认证
当代理A委派给代理B,B再委派给代理C时,运行在A的TEE中的代理如何验证C的认证声明完整保留了A原始委派意图?目前没有标准机制来证明最终由工具服务器执行的行动保持在用户最初授权编排代理委派的范围内。
TEE-Backed RAG and Vector Store Isolation / TEE支持的RAG与向量存储隔离
当前对代理记忆的保护方法有所改进,但需要系统级的端到端TEE保护,涉及数据摄入路径的完整性、运行时内存隔离与认证和来源机制的结合。统一RAG框架、向量存储基元和来自CC的认证机制的标准化接口仍是一个开放工程挑战。
CC-Aware Agent Communication Protocol Design / 面向CC的代理通信协议设计
现有协议如MCP和A2A将认证和安全信道视为事后考虑。重新设计或扩展这些协议以支持认证双向认证、签名请求、来源元数据以及提及的复合认证模式代表了新的研究机会。
Side-Channel Leakage in Autoregressive Inference / 自回归推理中的侧信道泄露
自回归解码中的令牌级时序模式可揭示上下文长度、主题领域甚至特定令牌序列。这使得侧信道对于代理尤其有害,因为记忆内容足以揭示会话意图。设计TEE感知的自回归生成模式,使令牌释放模式与令牌内容无关,仍是一个开放挑战。
GPU-TEE Performance at LLM Scale / LLM规模下GPU-TEE的性能
尽管NVIDIA H100 CC的基准测试显示CPU到GPU PCIe加密带来小开销,但代理负载通常涉及频繁的检索循环、工具调用和上下文窗口操作,这些会加重该加密开销。对足够大的批量或长期持续推理会话,开销可以摊销。未来的代理工作负载可能无法利用这种大小和一致性。
Regulatory Alignment and Compliance / 监管对齐与合规
与AI安全和基础设施安全的监管框架对齐。特别受影响的框架是EU AI法案和数字运营弹性法案(DORA)。从技术层面看,CC通过硬件化信任边界和可审计的认证证据支持合规主张。但监管目标与CC能力之间存在若干差距。建立CC部署的具体合规要求需要与监管者、审计员、平台提供商和代理部署者的更密切合作。
Conclusion / 结论
尽管多种硬件信任原语(如SGX、TDX、SEV-SNP、TrustZone、CCA和H100 CC)已足够成熟用于针对性部署,但尚未有一个广泛建立的端到端框架将它们绑定为生产代理AI的一致安全基板。本文在CC和代理AI的交集处综合了设计空间:一个统一的六种TEE平台分类法、一个覆盖五个代理层和九个安全目标的代理中心威胁模型、对CC防御的比较调查,以及六个开放挑战包括复合认证、GPU-TEE性能和监管对齐。 在当前状态下,CC提供了针对特权基础设施攻击者的有意义的保护,特别是对模型推理、凭证和短期内存。但代理系统提出的独特要求——持久记忆机密性、工具调用完整性、跨代理来源和复合认证——在已建立的生产级实现中尚未完全解决。未来的研究应优先考虑将认证从单个节点扩展到多跳代理链、使TEE隔离适用于代理记忆存储、设计具有CC意识的代理通信协议,并解决LLM规模下的GPU-TEE性能差异。
原文信息
英文题目:When Agents Handle Secrets: A Survey of Confidential Computing for Agentic AI 作者:Javad Forough, Marios Kogias, Hamed Haddadi arXiv ID:2605.03213v2 类别:cs.CR(密码学与安全),cs.AI(人工智能) 原文链接:http://arxiv.org/abs/2605.03213v2

