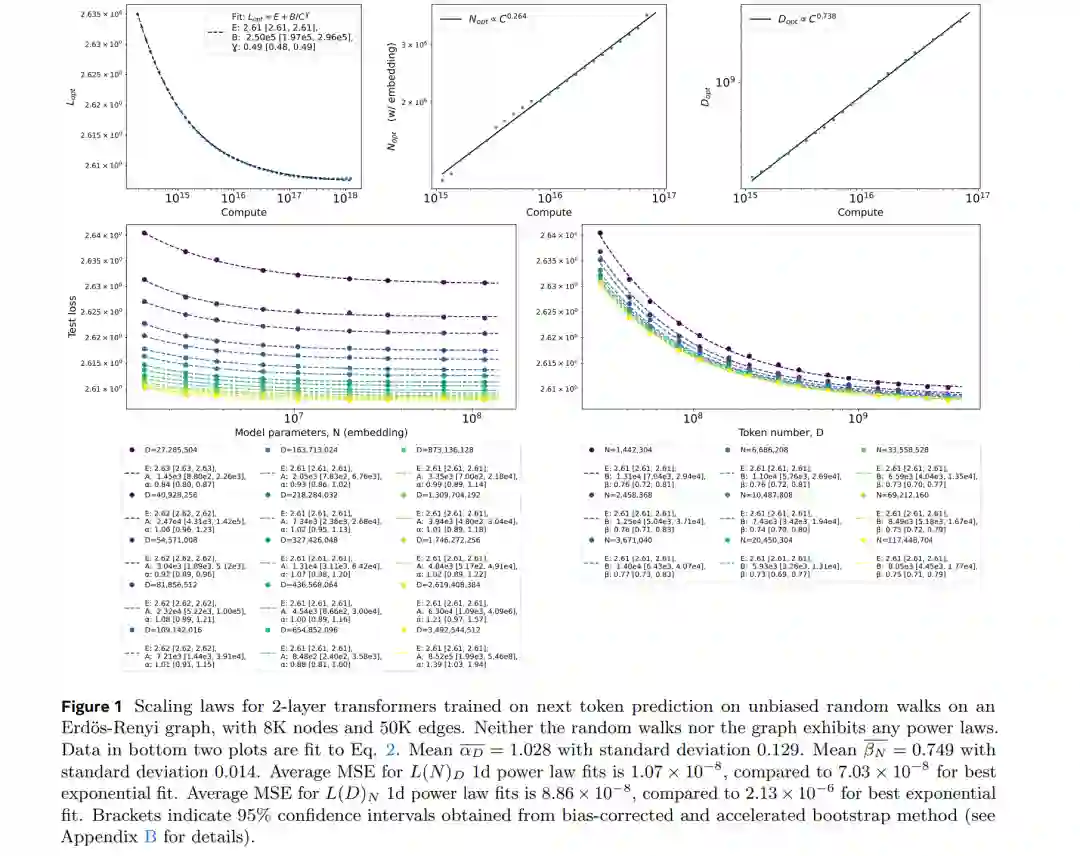
缩放定律在现代 AI 革命中发挥了重要作用,为从业者提供了模型性能如何随数据、计算和参数增加而提高的预测能力。这引发了对神经缩放定律起源的浓厚兴趣,一个常见的建议是它们源于数据中已经存在的幂律结构。在本文中,我们研究了在具有可调复杂度的图上训练预测随机游走的 Transformer 的缩放定律。我们证明,即使在数据相关性中不存在幂律结构的情况下,这种简化设置也会产生神经缩放定律。我们进一步考虑通过在从越来越简化的生成语言模型(从 4,2,1 层 Transformer 到二元语言模型)采样的序列上进行训练,系统地降低自然语言的复杂度,揭示了缩放指数的单调演变。我们的结果还包括从 ER 和 BA 随机图系综的随机游走训练中获得的缩放定律。最后,我们重新审视了语言建模的常规缩放定律,证明使用上下文长度为 100 的 2 层 Transformer 可以复现几个重要结果,对先前文献中使用的各种拟合进行了批判性分析,展示了一种与当前文献实践不同的获取计算最优曲线的替代方法,并提供了初步证据,表明最大更新参数化可能比标准参数化更具参数效率。
1 引言
现代深度学习最重要的启示之一是:随着计算资源和数据规模的有效增加,模型能力会呈现稳健的提升(Sutton, 2019)。这一现象通过神经缩放定律(Neural Scaling Laws, NSL)得到了部分量化表征(Cortes et al., 1993; Hestness et al., 2017; Kaplan et al., 2020; Henighan et al., 2020; Hoffmann et al., 2022)。这些定律表明,在众多视觉和自然语言任务中,测试损失(test loss)会随着模型参数量 $N$、数据集大小 $D$ 以及计算量 $C$ 的增加,在多个数量级范围内遵循简单的幂律(power law)规律性下降。神经缩放定律的发现对语言模型预训练实践产生了重大影响,它使从业者能够确定如何随计算量的增加而最优地扩展模型规模和数据集规模(Kaplan et al., 2020; Hoffmann et al., 2022; Chowdhery et al., 2022; Grattafiori et al., 2024; Yang et al., 2024, 2025; Liu et al., 2024; Jiang et al., 2024; Tian et al., 2025)。此外,它还为架构、优化算法和数据的基准测试提供了一种衡量途径。 这些经验性结果引发了大量旨在理解神经缩放定律起源的理论研究。具体而言:为何测试损失会在 $N, D, C$ 跨越多个数量级时呈现幂律下降?又是什么决定了幂律指数?对这一问题的清晰回答可能具有显著的实践价值,因为一旦理解了指数的决定因素,我们便可能掌握提升这些指数的方法,从而提高深度学习方法的渐近效率(asymptotic efficiency)。 一种普遍的观点认为,测试损失中的幂律缩放源于数据集本身固有的幂律特征。例如,众所周知,文本语料库中的词频遵循齐普夫定律(Zipf’s law),自然语言语料库中还存在许多其他已表征的幂律现象(Piantadosi, 2014; Altmann and Gerlach, 2016)。自然图像的光谱也表现出幂律特征(Ruderman, 1994; Maloney et al., 2022)。多项理论工作已经证明,在线性回归或核回归(kernel regression)中,测试损失的幂律确实源自数据(或由数据定义的特征)中的幂律(Bordelon et al., 2020; Bahri et al., 2021; Spigler et al., 2020; Maloney et al., 2022; Lin et al., 2024; Paquette et al., 2024; Bordelon et al., 2024)。更一般地,如果我们假设模型需要学习一组离散任务以达到特定的测试损失值,且这些任务按幂律权重分布,那么测试损失也会遵循幂律(Michaud et al., 2024; Ren et al., 2025)。 然而,上述基于均方误差(MSE)损失的线性模型理论,与采用交叉熵损失的自回归序列建模场景相去甚远。因此,目前尚不清楚这些理论在多大程度上能代表自然语言建模中观察到的神经缩放定律。一种潜在有效的方法是研究具有**可调复杂度(tunable complexity)**数据集的序列建模,通过系统性地将数据集从现实极限降至高度简化的极限,并追踪神经缩放定律行为的变化。可调复杂度数据集的另一个优势是它们可能允许在不同尺度间进行更合理的模型比较:将小模型与大模型进行妥善对比时,也应相应地增加数据集的复杂度。反之,数据集的复杂度不仅取决于其规模,还取决于相关程度、层级结构和组合结构(Cagnetta et al., 2024)。 为此,我们提议研究图(graphs)上随机游走的序列建模。图及其推广形式——超图和层级图结构——能够捕获多种利害数据的大部分特征,包括语言、游戏和形式数学的许多特性。特别是,图上的游走可以对应于从 n-gram 模型(第 3 节)生成数据,从而提供了一种简化的语言模型。另一方面,在更抽象的层面上,图上的游走可用于建模逐步推理和思维链(Chain of Thought)推理(Khona et al., 2024; Besta et al., 2024)。
1.1 我们的贡献
本文的主要贡献如下: * 我们证明了在 Erdös-Renyi 和 Barabási-Albert 等随机图的随机游走上训练、执行“下一标记预测”(next-token prediction)的 Transformer 表现出神经缩放定律。特别是,我们通过实验展示了首个即使输入数据完全不具备幂律结构时依然存在缩放定律的案例(见图 1)。 * 我们通过在逐步简化的生成式语言模型上进行训练,系统性地降低了语言设置的复杂度,并测量了各复杂度水平下的神经缩放定律(见图 2)。 * 我们对大语言模型原始的神经缩放定律结果进行了批判性审视,并指出:(i) 最优拟合应为如公式 2 所示的一维拟合,而非文献中常见的某些二维参数拟合;(ii) 展示了一种用于获取计算最优缩放定律的简单神经网络回归方法,该方法不同于现有文献,且在拟合损失曲线方面具有更高的精度(见图 10, 17, 18)。 * 我们证明了先前工作中发现的语言缩放定律完全可以在上下文长度为 100 的双层 Transformer 中体现。实验表明,Kaplan 与 Chinchilla 缩放定律之间的重大差异可以通过是否包含嵌入层参数来解释(Porian et al., 2024; Pearce and Song, 2024)。我们还提供了初步结果,显示最大更新参数化($\mu$P, Yang and Hu, 2021)可能比标准参数化更具参数效率(见图 13, 14),这意味着 $\mu$P 下的计算最优缩放并不对应于每个参数恒定的标记(token)数量。