

论文题目:Scaling Generalist Data-Analytic Agents
本文作者:乔硕斐(浙江大学)、赵延秋(浙江大学)、邱志松(浙江大学)、王潇斌(阿里巴巴)、张锦添(浙江大学)、赵斌(浙江大学)、张宁豫(浙江大学)、蒋勇(阿里巴巴)、谢朋峻(阿里巴巴)、黄非(阿里巴巴)、陈华钧(浙江大学)
发表会议:ICLR 2026
论文链接:https://arxiv.org/abs/2509.25084
代码链接:https://github.com/zjunlp/DataMind
欢迎转载,转载请注明出处****

一、引言
随着大语言模型在数学、代码、科学推理等任务上展现惊人能力,AI正迈入“下半场”——从单纯的对话问答转向解决复杂的、领域特定的智能体任务。其中,数据分析智能体因其在自动化科学研究中的核心地位,成为实现“AI创新”的关键支柱。然而,当前的数据分析智能体大多基于闭源模型,依赖复杂的提示工程或多智能体协作框架,且难以应对真实世界中多样化的数据格式、大规模文件以及长程、多步的复杂推理。
面对这一现状,我们提出了 DataMind,一个可扩展的、面向开源模型的数据合成与智能体训练方案。DataMind 系统性解决了构建开源数据分析智能体的三大核心挑战:
- 数据资源匮乏:公开基准多用于评估,缺乏带步骤标注的大规模训练轨迹;
- 训练策略不当:如何稳定地进行长程智能体训练,以及如何分配SFT和RL的阶段以获得最优性能,尚不明确;
- 多轮代码执行不稳定:并行智能体生成与多轮代码执行在有限内存下极易出错。
基于DataMind方案,团队构建了高质量训练集 DataMind-12K,并训练了 DataMind-7B 与 DataMind-14B 模型,本文将深入解读这一工作的核心技术与关键发现。 二、方法
DataMind 的完整流程包含四个精心设计的核心组件,形成了一套从数据到训练再到工程落地的完整闭环。
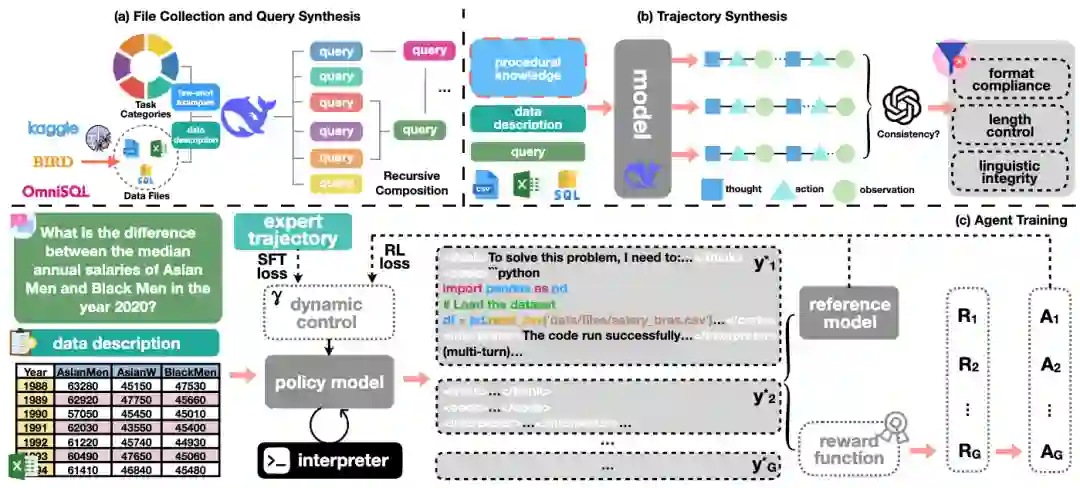
1. 高质量数据合成与筛选
- 多样化的文件收集:从Kaggle、BIRD、OmniSQL等来源收集了数千个.csv、.xlsx和.sqlite文件,覆盖金融、医疗、电商等多个领域。
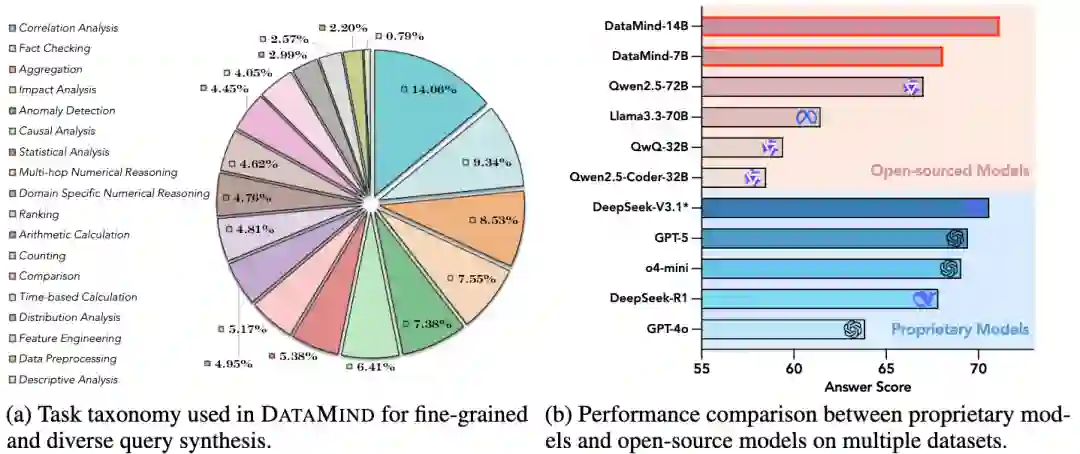
- 细粒度任务分类:为了生成多样化的查询,论文定义了一个包含 18类 数据分析任务的细粒度分类法(如聚合、排序、相关性分析、因果分析、异常检测等),并为每类任务设计了示例。
- 递归式易到难组合:为了提升查询的复杂度,团队采用递归组合策略,将多个任务类型串联成链(例如,先聚合再排序,最后进行统计分析),通过迭代2-5次,创造出远超单一任务能力的“多跳”分析挑战。
- 知识增强的轨迹采样与过滤:为确保轨迹质量,团队首先为每类任务构建了高层次的专家工作流知识。然后,为每个查询采样多条轨迹,并使用GPT-4o-mini作为裁判,进行自洽性过滤 (self-consistent filtering):仅保留最终答案一致的轨迹。对于不一致的轨迹,将裁判的思考链作为外部反馈,引导模型进行 反思修正,从而进一步丰富轨迹池的多样性。最后,通过格式、长度和语言完整性等多重规则过滤,最终得到 11,707条 高质量轨迹数据集DataMind-12K。
2. 动态平衡的训练目标
在训练阶段,论文发现传统的SFT-then-RL范式难以稳定。SFT虽能快速学习范式,但容易过拟合;RL探索空间大,但极不稳定。为此,DataMind引入了动态系数 来联合优化SFT和RL损失: 通过余弦衰减调度,训练初期以SFT为主(高),为模型提供稳定引导;后期逐步降低,鼓励RL自主探索,从而在稳定性和探索能力之间取得动态平衡。 3. 内存高效且稳定的多轮执行框架
为了解决多轮代码执行中内存爆炸和运行不稳定的问题,DataMind设计了三大工程优化:
- 异步生成与执行:将智能体的生成过程和代码执行过程解耦,避免相互阻塞。
- 分块代码维护:摒弃传统Notebook的全局变量池,仅保留文本代码块。运行时,将当前代码块与历史代码拼接执行,达到相同效果的同时大幅降低内存峰值。
- 沙箱安全控制:为每条轨迹隔离运行环境,严格控制CPU时间和内存使用,并过滤不安全函数调用,确保训练过程的安全稳定。
4. 多维度的奖励设计
奖励函数由三部分构成:格式奖励(确保输出格式规范)、答案奖励(使用GPT-4o-mini评估答案正确性)和长度奖励(惩罚冗长输出,鼓励简洁)。奖励设计核心在于:只要答案正确,模型即可获得较高保底奖励(≥0.5),再根据答案长度进行微调,有效抑制模型通过生成无效长文来“投机”的行为。 三、主要实验
本文三个具有代表性的数据集上对DataMind进行了初步评估:DABench(表格数据分析)、TableBench(复杂表格推理)和BIRD(Text-to-SQL)。对比的基线包括GPT-4o、o4-mini、DeepSeek-R1、DeepSeek-V3.1、GPT-5等闭源模型,以及Llama-3.3、Qwen-2.5系列和专门为数据相关任务微调的TableLLM、OmniSQL等开源模型。
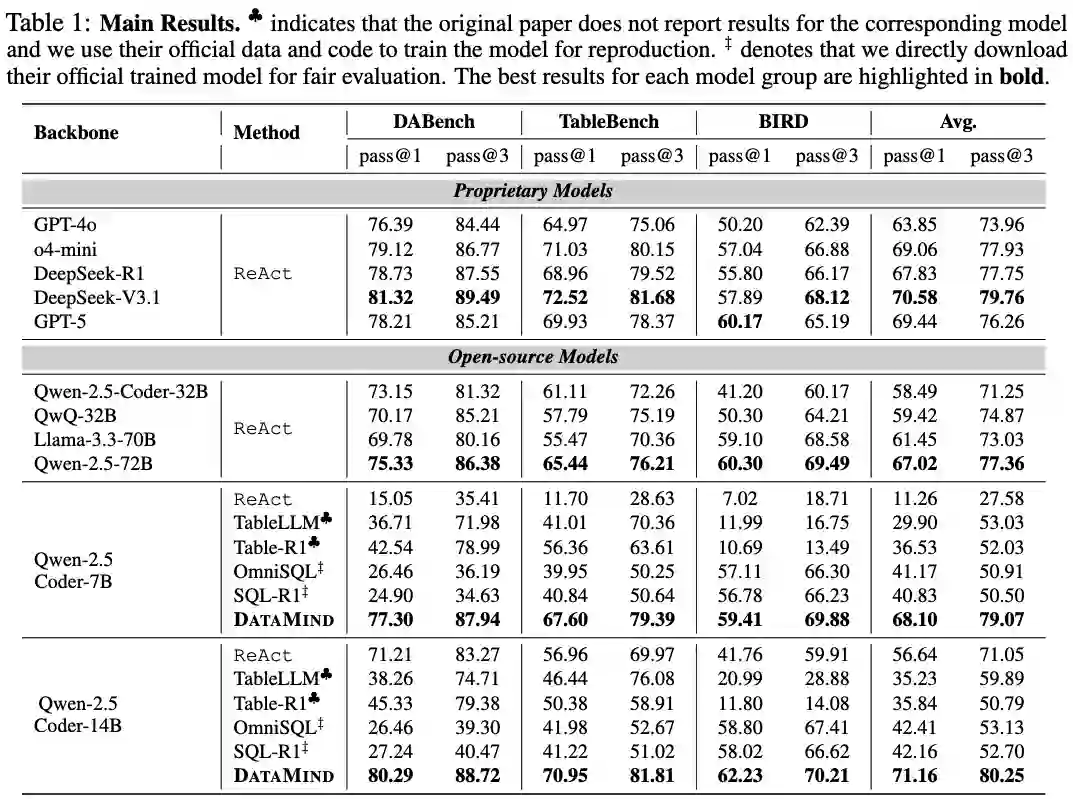
从实验结果中我们可以观察到以下几点:
- 模型性能表现:在本次评测设定下,DataMind-14B 的平均得分为 71.16%,高于对比的 DeepSeek-V3.1(70.58%)和 GPT-5(69.44%)等模型。DataMind-7B 的平均得分为 68.10%,在所有的开源模型中取得了最好结果。
- 任务泛化能力:与一些专精于特定任务的模型(如OmniSQL在BIRD上表现较好,但在其他数据集上下降明显)相比,DataMind在三个数据集上的得分相对均衡,显示出较强的泛化能力。
- 数据效率:值得注意的是,DataMind-12K的训练规模仅为1.2万条,远小于TableLLM的2万条和OmniSQL的250万条。这说明高质量的数据合成和筛选策略可以在一定程度上提高了数据利用效率。
四、分析
自一致过滤优于最佳轨迹选择:实验发现,保留所有通过自一致检验的轨迹(即使不选择Judge Model认为的最佳),比只选择单条最佳轨迹更能提升模型性能。这表明,推理路径的多样性对智能体学习至关重要,丰富的解题策略比单一的高质量答案更有价值。
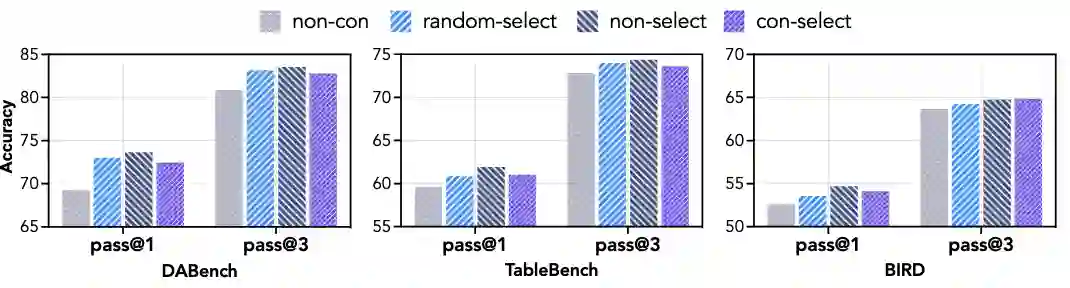
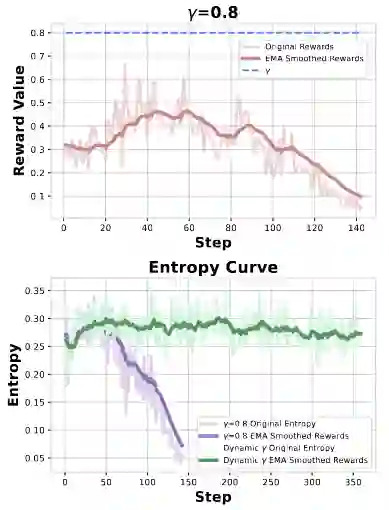
SFT损失既可以是RL的稳定器也可以是绊脚石:动态调整SFT损失的权重可以稳定RL训练。实验显示,如果全程没有SFT损失(=0)或SFT损失占比较小(=0.2),训练过程会迅速崩溃;如果全程保持高权重(=0.8),模型则会因过拟合SFT数据而陷入局部最优,丧失探索能力。只有采用动态衰减策略,才能让模型先“站稳”(SFT引导),后“奔跑”(RL探索),实现持续稳定的性能提升。 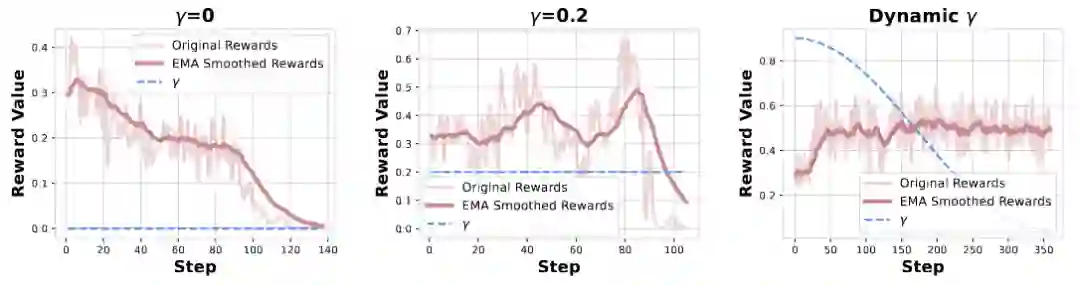
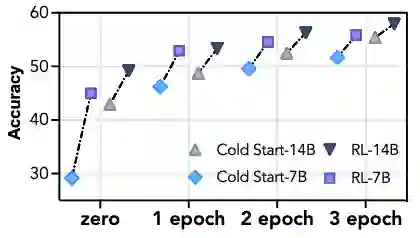
RL能缩小差距,但无法逆转顺序:在不同程度的SFT Cold Start后接入RL,结果表明:RL可以显著缩小不同性能基座模型之间的差距,但最终性能依然与基座模型的初始能力呈正相关。这印证了一个观点:RL的主要作用是激发和调动模型在SFT阶段习得的潜在能力,而非凭空创造新的能力。
五、总结
本文提出了 DataMind,一个面向通用数据分析智能体的可扩展数据合成与训练方案。通过系统性解决数据、训练和工程层面的核心挑战,DataMind成功训练出 DataMind-7B/14B 两个模型,在多个基准上超越了包括GPT-5在内的顶尖闭源模型。更重要的是,本文开源了全部数据和模型(DataMind-12K、DataMind-7B/14B),并分享了在数据过滤、训练策略、RL作用等方面的宝贵经验,旨在为社区在智能体训练这一前沿领域提供可操作、可复现的实践指南。
