
未来的军事系统日益作为由异构人类智能体与人工智能体组成的分布式社会-技术集合体运作。虽然多智能体强化学习为自适应协调提供了强大的范式,但无约束学习在结构上与指挥权限、法律责任以及在对抗条件下的认知稳定性不相容。本文基于协调约束多智能体强化学习,构建了一个严格的分布式军事人工智能理论框架。我们形式化了在部分可观测、显式通信和信增益条件下的多智能体学习,将"协调"作为一个首要控制变量引入,用以捕捉语义对齐、信任和组织完整性。通信被建模为一种认知性行动,它同时产生信增益和协调损耗。我们利用李雅普诺夫方法推导了稳定性条件,并证明有限自主性和通信速率限制对于协调的集体行为是必要的。所得理论调和了自适应智能与指挥意图、治理和合法控制,为分布式军事人工智能系统的设计提供了原则性基础。
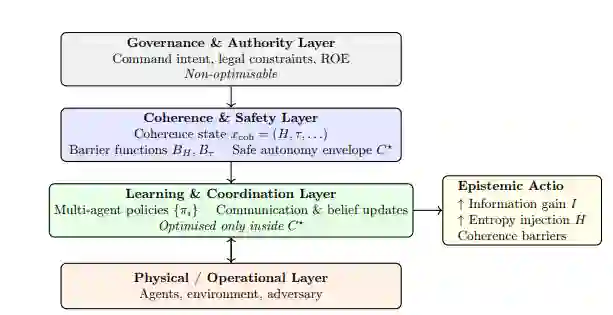
图1:分布式军事人工智能的治理架构。 分布式智能被建模为一个分层动力系统,其中强化学习仅在协调安全自主边界 C⋆ 内运行。治理与权限定义了容许的状态和行动,但并非优化目标。协调被视为一个由障碍函数和不变性条件约束的安全关键状态变量。每当提议的更新会违反协调或信任边界时,学习与协调过程都会被映射回 C⋆ 内。通信是一种认知性行动,它同时增加信增益并引入熵,从而将学习动力学与协调保持相耦合。因此,自主性是状态依赖的,而非二元的。
成为VIP会员查看完整内容
相关内容

Arxiv
39+阅读 · 2023年12月2日
Arxiv
19+阅读 · 2023年5月17日

最新内容
相关VIP内容
相关资讯