

具身人工智能(Embodied AI)将感知、认知、规划与交互集成到在开放世界、安全关键环境中运行的智能体中。随着这些系统获得自主性并进入交通、医疗、工业或辅助机器人等领域,确保其安全在技术上极具挑战,在社会层面也至关重要。与数字AI系统不同,具身代理必须在不确定感知、不完全知识和动态人机交互下行动,失败可直接导致物理伤害。这篇综述全面而结构化地审视了具身AI的安全研究,考察了从感知到认知、规划、动作与交互以及智能体系统的整个具身管线的攻击与防御。我们引入了一个多层级分类法,统一了分散的工作,并将具身特定的安全发现与视觉、语言和多模态基础模型的更广泛进展联系起来。我们的综述综合了400多篇论文的见解,涵盖对抗性、后门、越狱和硬件级攻击;攻击检测、安全训练和鲁棒推理;以及风险意识人机交互。这一分析揭示了几个被忽视的挑战,包括多模态感知融合的脆弱性、越狱攻击下规划的不稳定性,以及开放场景下人机交互的可信性。通过将领域组织成一个连贯的框架并识别关键研究空白,本调查为构建不仅在现实部署中具备能力和自主性,而且安全、鲁棒且可靠的具身代理提供了路线图。
1 Introduction / 引言
具身人工智能(Embodied AI)旨在赋予自主代理感知、推理、规划和与物理世界交互的能力。与纯数字AI系统不同,具身代理在动态、不确定且安全关键的环境中运行,例如自动驾驶、协作机器人、智能医疗和辅助机器人。在这些场景中,不安全的感知、有缺陷的推理、错误的规划或不安全的交互不仅会导致任务性能下降,还会引发真实世界的事故、物理伤害和人类信任的丧失。 近年来,整个具身AI管线取得了快速进展。感知、认知、规划和交互能力的提升显著扩展了具身代理的能力。然而,这些能力也扩大并复杂化了攻击面。曾经主要出现在数字领域的安全挑战,如视觉中的对抗性样本或语言模型中的越狱提示,在物理环境中会带来严重得多的后果。例如,对视觉传感器的微小扰动可能导致自动驾驶汽车误解停止标志,而恶意投毒的训练数据可能损害任务规划并产生不安全的轨迹。错位或不可预测的人机交互可能进一步产生直接危及用户的行为。
尽管其重要性日益增加,具身AI特有的安全挑战仍未得到充分审视。现有AI安全调查主要关注纯数字系统,如视觉基础模型、大语言模型(LLMs)、多模态大语言模型(MLLMs)或数字代理。虽然这些工作提供了有价值的攻击和防御分类,但它们很少涉及感知、认知、规划和交互紧密耦合且必须在真实世界约束下运行的具身设置。因此,对具身AI安全的全面处理不仅需要综合每个组件内的研究,还需要整合来自更广泛AI安全领域中直接适用于具身系统的见解。
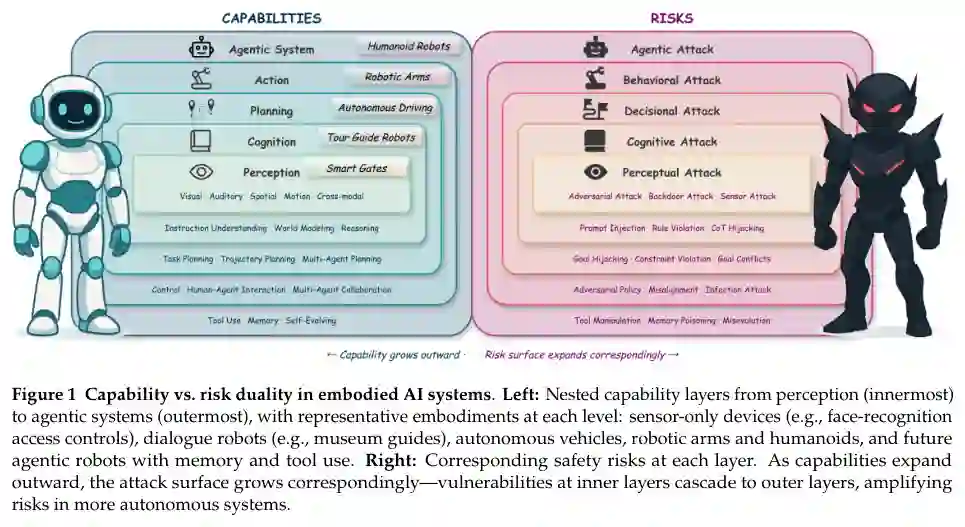
能力-风险二元性。本调查的一个关键组织原则是能力-风险二元性:具身管线的每一层不仅代表一个功能性组件,还代表一种能力扩展,而这种扩展会引入相应的新漏洞,如图1所示。真实世界的具身系统在能力堆栈的深度上各不相同。在最内层,仅传感器设备(如人脸识别门禁)代表了最简单的具身系统,对手只能攻击感知输入。添加认知能力会产生如博物馆导览机器人等能够进行对话和场景理解的智能体,从而在推理和语言理解方面开辟了攻击面。融入规划能力可实现导航和决策制定,如在自动驾驶车辆中,对手还可以操控路径规划和轨迹预测。在动作与交互层,机械臂和人形机器人获得了物理操控环境的能力,使得控制和人与机器人交互面临被利用的风险。最后,智能体系统通过持久记忆、工具使用和自我进化增强了所有先前的能力,创造了最广泛的攻击面,其中内层的任何漏洞都可能向外级联。这种二元性——更深的能力意味着更广泛的风险——激励了我们的分层分类法,并构成了本调查其余部分的结构:每个章节既讨论了其能力层特有的攻击,也探讨了内层漏洞向外层故障传播的路径。
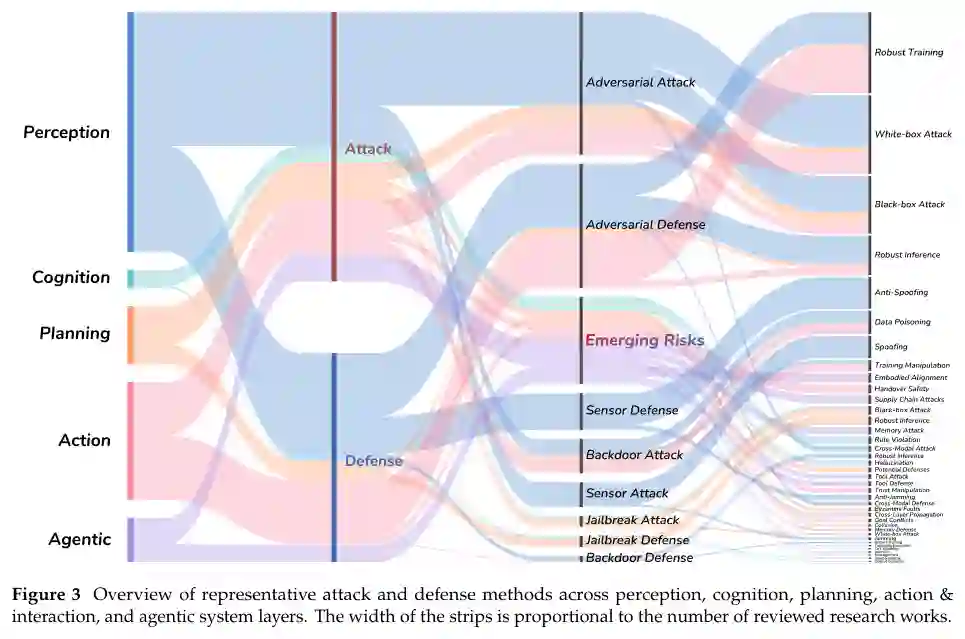
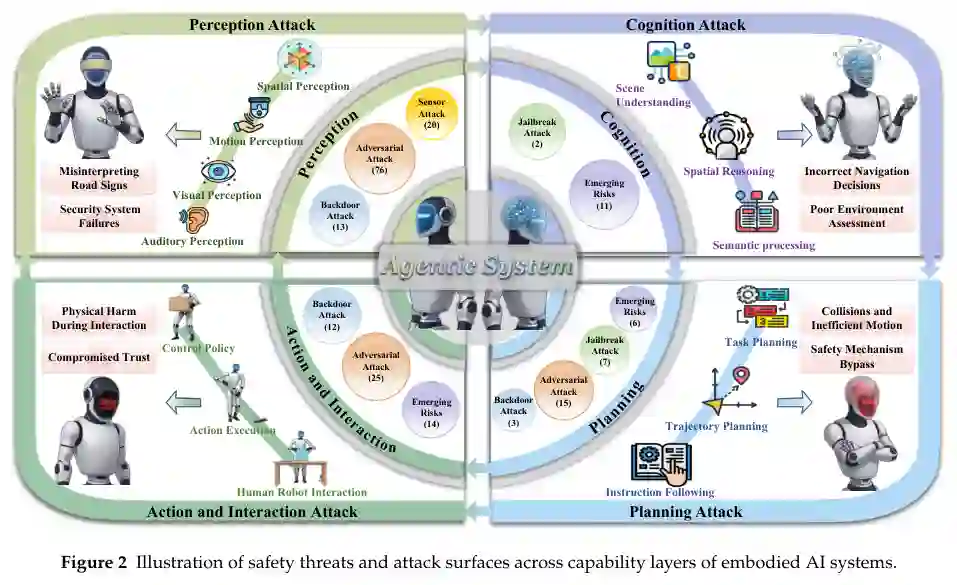
为满足这一需求,我们对具身AI的安全研究进行了系统性调查。我们提出了一个多层级分类法,将漏洞和防御组织在具身AI系统的五个关键组件中:感知、认知、规划、动作与交互,以及智能体系统。对于每个组件,我们分类了攻击和防御,包括对抗性感知、不安全推理、扰动下的规划、不安全控制和交互,以及智能体级别的风险,如工具滥用、记忆中毒和级联故障,如图2所示。我们进一步将分析扩展到包括来自传统AI安全的高度相关研究,涵盖视觉、语言和多模态基础模型,重点关注那些对具身智能有明确影响的研究。图3提供了不同攻击和防御类型及其在管线组件中分布的概览。这种双重视角将具身AI安全置于更广泛的AI安全生态系统中,同时突显了当智能部署在物理世界时出现的独特风险。 基于现有文献,我们识别并总结了各种攻击带来的威胁,如表1所示。在感知层,对抗性攻击在感官输入(如视觉或听觉数据)中引入细微扰动,导致错误分类和错误的环境解释。后门攻击在模型中嵌入隐藏触发器,在出现提示时激活恶意行为,而传感器攻击(如欺骗和干扰)会破坏传感器数据,导致环境感知失败或系统关闭。这些漏洞可能导致对象误读、障碍物检测失败或导航错误。在认知层,对抗性攻击操纵推理过程,导致系统做出不安全或错误的决策,例如有缺陷的空间理解或上下文误读。在规划层,各种攻击,包括对任务规划和轨迹规划的对抗性攻击、越狱攻击和后门攻击,可以操纵模型计划的行动,导致不安全的轨迹、碰撞或未能遵循预期目标。在动作与交互层,对抗性操纵和后门攻击可以在人机交互过程中绕过安全机制,引发有害或意外的行为。最后,在智能体系统中,威胁来自代理扩展的自主性:工具滥用可能导致有害的代码执行或意外的物理行为,记忆中毒可能破坏代理的经验存储以导致持续的不安全行为,记忆泄漏可能暴露来自代理记忆存储的私有用户数据和特权上下文,而当自我进化的代理侵蚀自身对齐时,级联故障可能在内层之间传播。
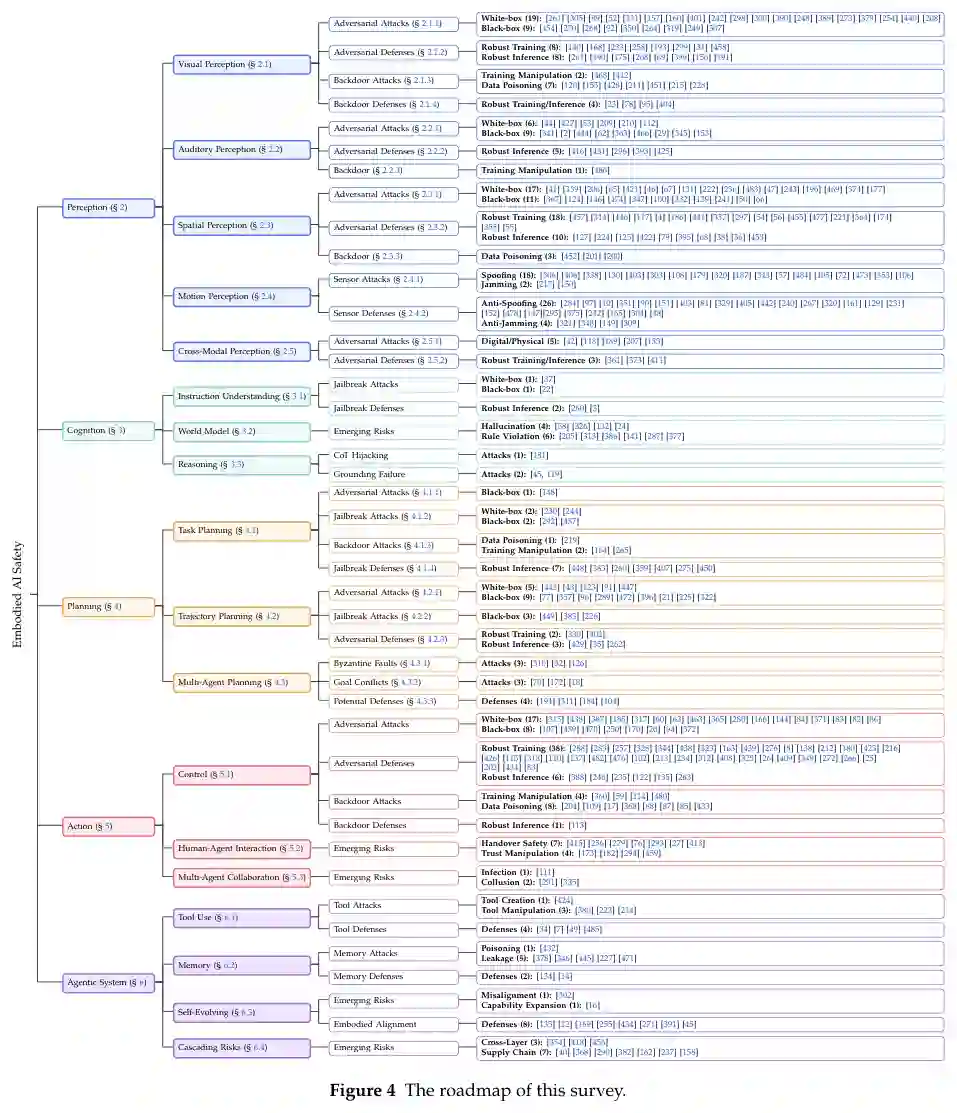
与现有调查的差异。先前的调查从互补的角度审视了具身AI安全。[397]提供了漏洞和攻击面的早期分析,但对防御策略的覆盖有限。[381]侧重于导航中的鲁棒性问题,但未扩展至认知、操作或人机交互。[324]提出了概念基础和系统级安全原则,但没有开发详细的攻击-防御分类法。[24]分析了世界模型安全,特别是预测性故障,而对感知、规划和交互风险的探讨较少。[247]认为具身故障源于系统级不匹配而非孤立的LLM或CPS缺陷,但未开发组件级的攻击-防御分类法。[366]从闭环传播的角度考察了对抗性鲁棒性,但侧重于对抗性攻击,未涵盖后门、越狱或智能体级威胁。[143]调查了LLM控制机器人的安全威胁和防御,但范围狭窄地局限于LLM集成,未涉及更广泛的感知或交互层。[281]提供了一个政策导向的风险分类法,涵盖物理、信息和社会维度,但未分析具体的攻击机制或防御。[376]从物联网角度以双脑架构框架调查了具身AI,但将安全与隐私视为使能技术的一个组成部分,而非开发攻击-防御分类法。相比之下,本调查综合了整个具身管线的攻击和防御,并整合了传统AI安全的见解,以提供对具身AI安全的统一、机制导向的理解。图4提供了本调查的路线图。
2 Perception / 感知
感知构成了具身AI的最内层,赋予了代理通过多种感知模态解读环境的基础能力。在这一层,攻击面始于感官边界:对手可以通过对抗性扰动、传感器欺骗和后门触发器来破坏代理所感知的内容。由于感知支撑着所有外层,这一阶段的错误会在整个系统中传播和放大:一个被错误分类的对象会导致有缺陷的推理、不安全的规划和危险的动作。每种模态通过不同的传感器和信号类型与物理世界交互,产生了很大程度上特定于模态的威胁模型、攻击技术和防御。本节按感知模态组织:视觉感知(第2.1节)解决基于摄像头的感知漏洞,重点强调视觉语言模型中使用的现代视觉编码器(如CLIP、ViT和SigLIP);听觉感知(第2.2节)涵盖对语音识别和说话人验证系统的攻击,这些系统对于基于语音的人机交互至关重要;空间感知(第2.3节)研究对3D理解的威胁,包括SLAM、深度估计、姿态估计和神经场景表示(如NeRF和3DGS);运动感知(第2.4节)解决惯性测量、GPS和本体感知中的漏洞;跨模态感知(第2.5节)讨论对多模态感知系统和传感器融合的攻击。对于每种模态,我们审查攻击、防御和评估基准。传感器级攻击(欺骗和干扰)被整合到每种模态中,而非单独处理。
2.1 Visual Perception / 视觉感知
视觉感知涵盖基于摄像头的任务,如目标分类、目标检测(包括车道检测)、目标跟踪、语义分割和视频理解(动作识别、光流和视频目标分割),每一项都对具身下游任务至关重要。现代视觉编码器,包括对比视觉语言模型(如CLIP和SigLIP)和视觉变换器(ViT),作为共享感知骨干,其漏洞会传播到所有下游系统。本小节整合了所有视觉感知安全研究:操纵或保护像素级输入的对抗性攻击和防御,以及在视觉模型中嵌入或移除隐藏触发器的后门攻击和防御。
# 2.1.1 Adversarial Attacks / 对抗性攻击
对视觉管线的对抗性攻击通常发生在两个领域:数字空间中对像素值的扰动,以及物理世界中对真实世界信号(如路标和手电筒)的操纵以欺骗感知系统。 白盒攻击利用完整的模型访问权限来制造精确的扰动,分为数字和物理攻击策略。数字攻击直接在数字空间中操纵输入。对于目标分类,Melis等人引入了针对iCub机器人视觉管线的区域约束扰动。对于目标检测,Thys等人使用对抗性补丁来隐藏检测或降低定位精度。对于单目标跟踪,RTAA利用时间信息。对于多目标跟踪,Tracker Hijacking利用稀疏帧扰动诱导长期跟踪失败。对于语义分割,CAA执行对联合网络的多任务攻击。现代视觉编码器引入了超越任务特定模型的新攻击面。对于对比视觉语言编码器如CLIP和SigLIP,AnyAttack在LAION-400M上预训练了一个自监督扰动生成器,无需标签监督即可产生跨模型攻击向量。物理攻击修改对象或场景以在真实的捕获条件下欺骗感知。对于目标分类,DARTS和RP2通过粘贴贴纸或打印图案等方式进行物理攻击。对于目标检测,ShapeShifter将期望变换扩展至物理域。 黑盒攻击在没有模型访问权限的情况下运作,依赖于可转移性、基于查询的优化或替代模型。在数字域,对于多目标跟踪,AdvTraj混淆了关联阶段。对于语义分割,PB-UAP生成跨模型可转移的黑盒通用扰动。在物理域,对于目标分类,ELA预测交通标志姿态并训练RL代理实时投射对抗性激光图案。对于目标检测,CAMOU扰动车辆外观。
# 2.1.2 Adversarial Defenses / 对抗性防御
视觉防御通过在训练或推理阶段纳入鲁棒策略,保护目标分类、检测、跟踪和分割管线免受对抗性操纵。 鲁棒训练通过纳入对抗性示例、增强数据或特征恢复来强化模型。对于目标分类,Kalin等人使用可见光和红外图像并基于对抗性表面分析重新训练模型。对于目标检测,DSNet、IA-YOLO和BAD-Net联合学习可见性增强、特征恢复或去雾。对于语义分割,RP-PGD采用对抗性训练。鲁棒推理通过输入或输出审核来防御模型。对于目标分类,Melis等人检测并过滤在深度特征空间中偏离训练分布的输入。现代视觉编码器也需要架构感知的防御。对于CLIP系列编码器,TeCoA引入了提升零样本鲁棒性的对比对抗性微调。输出审核通过分析输出行为或跨变换比较预测来验证模型预测。对于目标检测,SentiNet基于输出进行检测。
# 2.1.3 Backdoor Attacks / 后门攻击
对视觉感知的后门攻击在模型训练期间嵌入隐藏触发器,使得系统对良性输入表现正常,但触发器出现时执行对手选择的行为。这些攻击通过训练操纵或数据投毒来针对视觉模型。训练操纵攻击通过操纵训练目标或程序来嵌入后门。对于ViTs,TrojViT通过RowHammer位翻转注入木马。数据投毒攻击通过将带触发器的样本注入训练数据来嵌入后门。Han等人针对目标检测器使用物理对象作为触发器。现代视觉编码器也易受后门攻击。对于视觉语言编码器,单个受损编码器会将后门行为传播到所有下游任务。
# 2.1.4 Backdoor Defenses / 后门防御
视觉感知的后门防御旨在检测或移除训练期间植入的隐藏视觉触发器。当前针对特定任务视觉后门攻击的防御研究仍然有限,这突显了在具身系统中保护视觉感知的一个重要开放挑战。对于现代视觉编码器,后门防御必须在编码器级别运作。对于ViTs,Doan等人利用独特的补丁变换响应来检测触发器。对于CLIP系列编码器,CleanCLIP通过多模态对比微调重新对齐模态表示以削弱后门关联。
2.2 Auditory Perception / 听觉感知
听觉感知通过语音识别器和说话人验证器支持人机交互和基于语音的控制。本小节整合了所有听觉感知安全研究。
# 2.2.1 Adversarial Attacks / 对抗性攻击
对听觉感知的对抗性攻击在数字空间通过扰动音频波形,和在物理空间通过操纵信号(如语音注入和说话人欺骗)来运作。白盒攻击在物理域针对语音识别器,Carlini等人将音频命令转换成人类无法理解的形式。Metamorph采用类似背景音频的扰动。对于说话人验证器,Li等人纳入房间脉冲响应以保持在通过空中播放下的有效性。黑盒攻击在数字域,TSMAE调整播放速度以攻击语音识别器。Occam为云API引入仅决策的对抗性示例。
# 2.2.2 Adversarial Defenses / 对抗性防御
听觉防御通过鲁棒推理策略保护语音识别器和说话人验证器系统免受对抗性扰动。对于语音识别器的输入审核,Samizade等人提取MFCC特征并使用CNN分类良性和对抗性样本。音频净化采用扩散模型来净化和恢复输入信号。
# 2.2.3 Backdoor Attacks and Defenses / 后门攻击与防御
听觉感知的后门研究仍处于萌芽阶段。TrojanModel通过训练操纵将后门插入语音识别器的声学模型,但尚未提出专门的防御,这突显了保护基于语音的具身系统的一个重要开放挑战。
2.3 Spatial Perception / 空间感知
空间感知使具身代理能够构建、维护和推理环境的3D表示,以进行导航、操作和避障。它涵盖点云分类、3D目标检测与跟踪、轨迹预测、深度与姿态估计、SLAM和神经场景表示。本小节整合了所有空间感知安全研究。
# 2.3.1 Adversarial Attacks / 对抗性攻击
对空间感知模型的对抗性攻击在数字空间扰动点云、深度图或神经场景表示,或在物理空间操纵3D对象几何体、LiDAR信号或摄像头输入,以破坏检测、定位和导航。白盒攻击中,针对3D目标检测器,FLAT操纵车辆轨迹以影响LiDAR运动补偿。针对SLAM系统,Yoshida等人对LiDAR点云施加小的、时机恰当的扰动以破坏扫描匹配。对于场景表示模型,Poison-Splat引入了一种针对3DGS的数据投毒攻击。黑盒攻击在数字域,Hau等人强制传感器记录注入点,从而将真实点推出目标的边界框。在物理域,SpotAttack使用基于遗传算法的全局搜索来优化非反射性对抗点。
# 2.3.2 Adversarial Defenses / 对抗性防御
空间防御通过鲁棒训练和鲁棒推理策略保护点云分类器、3D目标检测器、SLAM系统和神经场景表示免受对抗性扰动。鲁棒训练包括对抗性训练、多模态融合、场景增强、环境增强、形式化安全方法和风险感知规划。鲁棒推理的输入审核检测异常输入、预处理点云或恢复降级数据。对于点云分类器,PointGuard提供认证的鲁棒性保证。对于3D目标检测器,LiDARPure采用扩散模型来净化输入点云。
# 2.3.3 Backdoor Attacks and Defenses / 后门攻击与防御
针对空间感知的后门攻击通过数据投毒针对3D目标检测器和LiDAR分割。Zhang等人和BadLiDet分别展示了在鸟瞰图表示中的像素级触发器注入和为3D目标检测器设计的不易察觉的点级扰动。尚未提出专门针对空间后门的防御,这是保护具身系统中3D感知的一个重要开放挑战。
2.4 Motion Perception / 运动感知
运动感知使具身代理能够通过惯性测量单元、视觉和LiDAR里程计、全球导航卫星系统接收器以及同时定位与建图管线来估计自身的姿态、速度和轨迹。受损的运动感知直接导致危险的物理行为。
# 2.4.1 Sensor Attacks / 传感器攻击
对运动感知的传感器攻击在数据到达感知算法之前操纵原始传感器信号,利用硬件漏洞、信号处理管线或物理层特性。欺骗攻击通过注入或呈现虚假但物理上看似合理的信号来操纵传感器输入。对于GNSS,重放欺骗捕获并重传带有有意延迟的认证信号。对于IMU,声学注入利用惯性传感器的机械共振。RF注入针对雷达等射频传感器。干扰攻击通过干扰破坏或阻塞合法的传感器信号。
# 2.4.2 Sensor Defenses / 传感器防御
运动感知的防御通过异常检测、跨传感器验证、鲁棒状态估计以及反欺骗/反干扰机制来保护运动估计。反欺骗方法包括检测、认证和缓解。
2.5 Cross-Modal Perception / 跨模态感知
跨模态感知通过融合多种传感器类型来增强鲁棒性和情境意识,但也引入了特有的攻击面。
# 2.5.1 Adversarial Attacks / 对抗性攻击
对抗性攻击利用融合漏洞(模型架构、注意力权重或决策逻辑)生成跨模态扰动,这些扰动从一个传感器(通常是相机)不可察觉地转移到另一个传感器。
# 2.5.2 Adversarial Defenses / 对抗性防御
防御包括鲁棒训练/推理,例如通过跨模态对比微调进行特征级对齐以抵抗对抗性转移,以及在融合前对每种模态进行独立净化。
3 Cognition / 认知
认知层使具身代理能够理解指令、构建和维护世界知识,并基于这些知识进行推理。与感知不同,认知漏洞不会破坏传感器输入,而是扭曲代理对感知信息的语义理解或逻辑处理,导致环境误读、上下文错误和潜在的不安全行为。
3.1 Instruction Understanding / 指令理解
指令理解将自然语言命令映射到可执行任务。攻击者成功破坏指令理解可能通过误导指令来操纵代理。越狱攻击通过精心设计的提示绕过安全对齐,诱使代理执行禁止或被拒绝的任务。
3.2 World Model / 世界模型
世界模型是代理对环境的内部表征,用于预测未来状态并指导决策。新兴风险包括幻觉,导致代理基于不存在的对象或关系做出决策,以及规则违规,代理学习或操作有缺陷的环境动态导致目标违背。
3.3 Reasoning / 推理
推理涉及高级认知过程,如因果推理、多步逻辑推断和基于常识的决策。新兴攻击包括思维链劫持,通过提示嵌入引入错误偏差,以及基础失败攻击,通过错误认知破坏逻辑推理。
4 Planning / 规划
规划层将感知和认知的输出转化为在物理世界中执行可行且安全的行动序列。规划中的漏洞可能导致碰撞、危险动作的执行以及安全关键约束的违反。
4.1 Task Planning / 任务规划
任务规划将高级目标分解为有序的子任务或行动步骤。对任务规划的攻击包括对抗性攻击、越狱攻击和后门攻击。越狱攻击利用提示注入绕过安全约束。后门攻击通过数据投毒或训练操纵将隐藏触发器嵌入规划器。越狱防御通常采用安全推理策略。
4.2 Trajectory Planning / 轨迹规划
轨迹规划将任务级别序列转换为无碰撞的时空路径。对抗性攻击可以引入障碍物或操纵轨迹生成。越狱攻击可绕过动作空间约束。对抗性防御包括鲁棒训练和鲁棒推理。
4.3 Multi-Agent Planning / 多智能体规划
多智能体规划涉及多个代理之间的协调。拜占庭故障指一个或多个代理表现恶意或故障导致系统性能下降。目标冲突指代理之间目标不一致导致对抗性协调或资源冲突。潜在防御包括基于信誉的机制和鲁棒共识协议。
4.4 Benchmarks / 基准
当前的规划安全基准包括对抗性规划和越狱设置的基准。
5 Action and Interaction / 动作与交互
动作与交互层是具身代理采取物理行动并与环境、人类或其他代理交互的层面。该层的漏洞直接导致物理伤害,是最关键的安全边界。
5.1 Robot Control / 机器人控制
机器人控制涉及低级执行命令。对抗性攻击包括白盒和黑盒攻击。防御包括鲁棒训练和鲁棒推理。后门攻击在控制策略中嵌入触发器。后门防御目前非常有限。
5.2 Human-Agent Interaction / 人机交互
人机交互涉及接近、交接和任务共享等场景。新兴风险包括交接安全、信任操纵和社会工程。
5.3 Multi-Agent Collaboration / 多智能体协作
多智能体协作中攻击可以感染或串通,导致不安全行为或安全危及任务目标。
6 Agentic System / 智能体系统
智能体系统层集成了工具使用、记忆和自我进化能力,使代理在长时间范围内自主运行。这种扩展的能力伴随着更广泛的攻击面。
6.1 Tool Use / 工具使用
工具使用允许代理调用外部API、库或物理执行器。攻击包括工具创建和工具操纵。防御包括安全检查、白名单和异常检测。
6.2 Memory / 记忆
记忆存储允许代理跨会话保留状态和知识。攻击包括记忆投毒和记忆泄漏。防御包括加密和访问控制。
6.3 Self-Evolving / 自我进化
自我进化允许代理通过经验改进能力。新兴风险包括对齐漂移和能力扩展。
6.4 Cascading Risks / 级联风险
级联风险涉及跨层传播和供应链风险。跨层漏洞从感知层传播到智能体层,导致系统范围故障。供应链攻击在训练或流水线中注入后门。
7 Open Challenges / 开放挑战
尽管取得了进展,但具身AI安全仍存在许多开放挑战。未来研究的关键领域包括多模态感知融合的脆弱性、越狱攻击下规划的不稳定性、开放场景下人机交互的可信性、物理世界中的防御验证、可转移性和泛化性,以及具身安全与数字域交叉的界定。
8 Future Trends / 未来趋势
未来趋势包括安全对齐的具身基础模型、实时自适应防御、具身安全基准,以及监管与合规。
9 Conclusion / 结论
本调查系统性地回顾了具身AI的安全研究,提出了一个从感知到智能体系统的五层分类法。我们综合了超过400篇论文,识别了各层的主要攻击和防御类型,并揭示了几个被忽视的挑战。通过将领域组织成一个连贯的框架并识别关键研究空白,本调查为构建不仅在现实部署中具备能力和自主性,而且安全、鲁棒且可靠的具身代理提供了路线图。
原文信息
英文题目: Safety in Embodied AI: A Survey of Risks, Attacks, and Defenses 作者: Xiao Li, Xiang Zheng, Yifeng Gao, Xinyu Xia, Yixu Wang, Xin Wang, Ye Sun, Yunhan Zhao, Ming Wen, Jiayu Li, Xun Gong, Yi Liu, Yige Li, Yutao Wu, Cong Wang, Jun Sun, Yixin Cao, Zhineng Chen, Jingjing Chen, Tao Gui, Qi Zhang, Zuxuan Wu, Xipeng Qiu, Xuanjing Huang, Tiehua Zhang, Zhipeng Wei, Hanxun Huang, Sarah Erfani, James Bailey, Jianping Wang, Wei-Ying Ma, Bo Li, Xingjun Ma, Yu-Gang Jiang arXiv ID: 2605.02900 类别: cs.CR, cs.AI, cs.CV, cs.RO Comments/项目信息: 51 pages, 4 figures, 19 tables. Project page: https://github.com/x-zheng16/Awesome-Embodied-AI-Safety 原文链接: http://arxiv.org/abs/2605.02900v1
