本文研究了专业工作流下的基于指令的图像编辑,并识别出三个持续存在的挑战:(i) 过度编辑,即编辑器修改了超出用户意图的内容;(ii) 单轮限制,现有模型大多为单轮对话,而多轮编辑往往会破坏对象的忠实度;(iii) 分辨率失配,约 1K 分辨率的评估与实际操作超高清图像(如 4K)的真实工作流不匹配。 为此,我们提出了 Agent Banana,这是一个用于高保真、对象感知、具备“编辑中思考(Thinking with editing)”能力的层级化智能体规划器-执行器框架。Agent Banana 引入了两个核心机制:❶ 上下文折叠(Context Folding),将长程交互历史压缩为结构化记忆,以实现稳定的长程控制;❷ 图像图层分解(Image Layer Decomposition),执行基于图层的局部编辑,在生成原生分辨率输出的同时保护非目标区域。 为了支持严谨的评估,我们构建了 HDD-Bench,这是一个高定义、基于对话的基准测试,具有可验证的分步目标和原生 4K 图像(1180 万像素),用于诊断长程任务中的失效情况。在 HDD-Bench 上,Agent Banana 实现了最佳的多轮一致性和背景忠实度(例如:IC 0.871, $SSIM_{OM}$ 0.84, $LPIPS_{OM}$ 0.12),同时在指令遵循方面保持了极具竞争力的表现,且在标准单轮编辑基准上也取得了强劲性能。我们希望这项工作能推动可靠的专业级智能体图像编辑的发展,并促进其集成到真实工作流中。

1 引言 (Introduction)
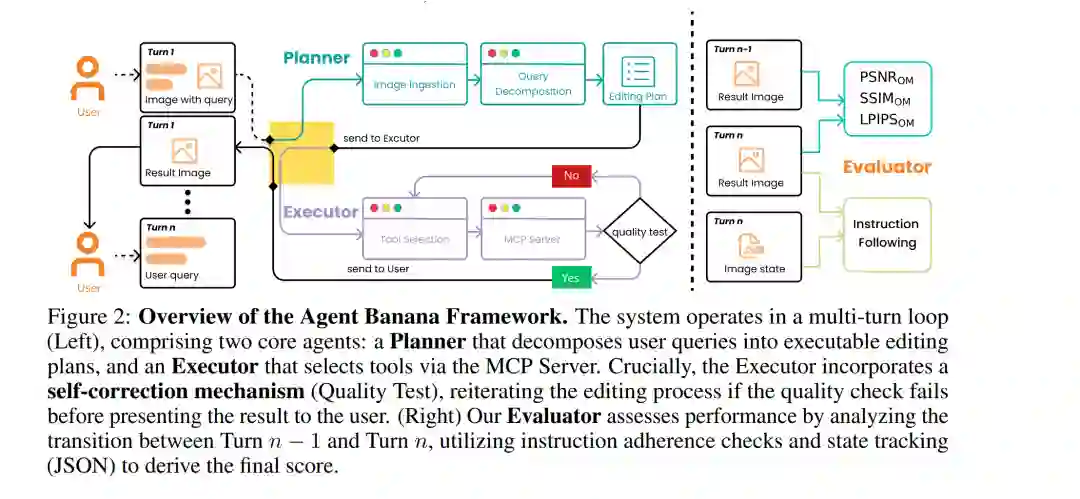
基于指令的图像编辑 [3, 54, 40, 10, 18, 4, 33, 45, 27] 使客户能够通过自然语言命令修改图像,并已成为现代生成式视觉系统的核心能力。基础模型(特别是扩散模型 [14, 26] 和自回归 Transformer [42])的近期进展,显著提升了图像的逼真度(Photorealism)和指令遵循能力,为商业系统(如 GPT-4o [33], Gemini 2.5 Flash Image [8])和强力开源模型(如 Flux-1 [20], Qwen-Image-Edit [44])中的实用编辑体验提供了动力。 尽管进展迅速,但目前的生成式编辑器 [44, 27, 17] 与专业工作流的需求之间仍存在巨大差距。在摄影 [16]、平面设计 [28]、视觉特效(VFX)及电影制作 [56] 等高要求场景中,用户通常处理原生高分辨率资产(通常为 4K 或更高),并要求精确的局部修改,且须完整保留所有非目标内容 [17]。相比之下,当今的模型往往在降低的分辨率下运行或依赖下采样,导致难以维持精细的纹理和清晰的边界。此外,它们频繁表现出过度编辑(Over-editing)效应,无意中改变了用户意图之外的区域,或降低了全局语义连贯性。最后,它们在处理多目标或顺序性 [59] 的复杂请求时显得力不从心;在这类场景下,成功取决于能否对指令进行分解、验证中间结果并在多轮交互中修正先前的决策。 我们认为,为了弥合这一差距,下一代编辑工具必须具备四项核心能力:① 意图理解与分解,将复杂请求拆解为原子级的子编辑任务;② 精确局部编辑,确保编辑被精准应用,同时在原生分辨率下保持其余内容不变;③ 状态跟踪与回滚,保留多轮交互中的中间步骤,以便用户(或智能体)能够轻松返回上一步并重新规划后续步骤;④ 高分辨率原生编辑,直接在原生 4K 图像上操作,避免下采样以保留细粒度纹理和锐利边界。 为此,我们推出了 Agent Banana。这是一个具备智能体属性、图层感知(Layer-aware)的图像编辑框架,它将高层级推理与规划能力与工具调用能力相结合,受益于愿景语言模型(VLMs)在图像理解、推理和工具调用方面的飞速进步 [15, 36, 46, 47, 34, 1]。Agent Banana 将“氛围感(Vibe)”类型的提示词分解为离散的单目标步骤,并利用“Photoshop 式”的图层隔离、掩模(Masking)和局部编辑来执行这些步骤。Agent Banana 还包含一种自我反思机制(Self-reflection mechanism) [50, 38],允许其在推理阶段进行重试、回滚和重新规划。至关重要的是,Agent Banana 围绕两种专为长程、高分辨率编辑量身定制的机制构建:上下文折叠(Context Folding),将长对话历史压缩为结构化记忆,以实现跨轮次的稳定状态跟踪;以及图像图层分解(Image Layer Decomposition),在隔离的高分辨率图层上执行编辑,从而保留非目标内容并防止迭代过程中的漂移。 为了评估在现实步进依赖(Stepwise dependencies)下的多轮高定义编辑,我们构建了 HDD-Bench。这是一个专为模拟专业编辑工作流而设计的高定义、基于对话的基准测试。与以往主要采用单轮或轮次间弱依赖的基准测试 [10, 18, 4, 45, 27, 51] 不同,HDD-Bench 具有逻辑相关的指令链,其中每一轮都会诱发一个定义明确的状态转换,并可进行逐步验证。HDD-Bench 在原生分辨率下对指令遵循、编辑局部性、多轮一致性和整体视觉保真度进行基准测试。为了减少评估的歧义性,我们进一步引入了一种基于图(Graph-based)的评估协议,用于跟踪跨轮次的对象状态转换,通过对目标编辑是否应用以及非目标区域是否保留进行局部、轮次级的检查,来补充全局感知指标。