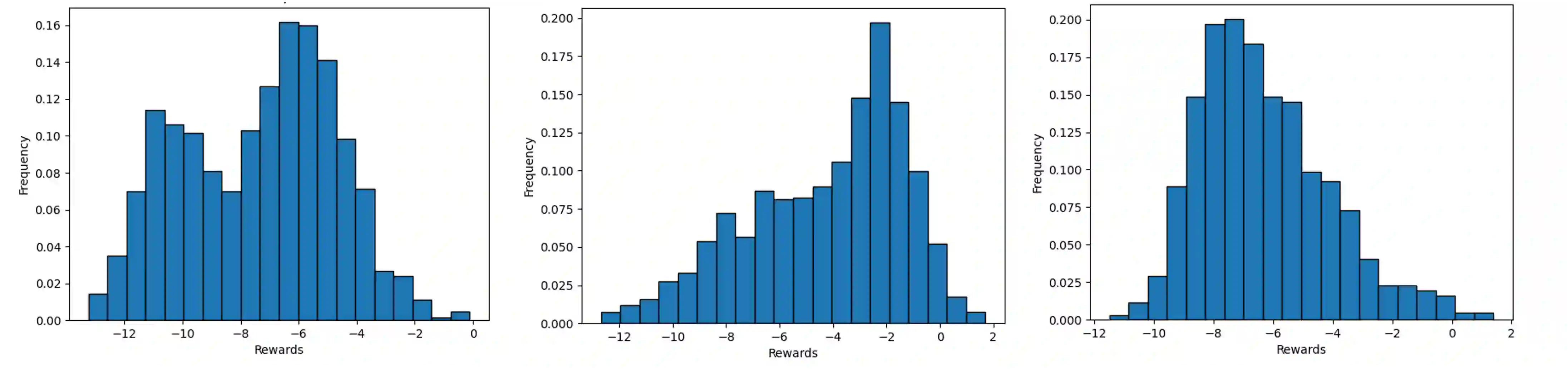
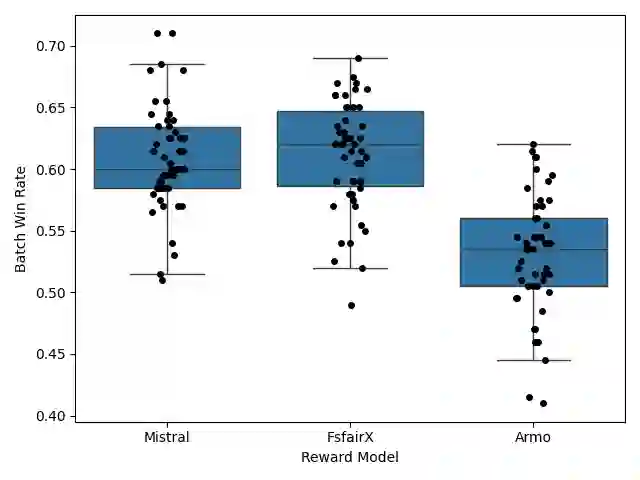
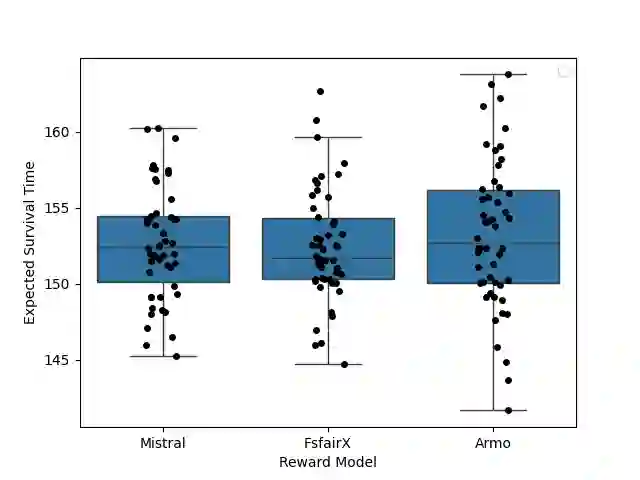
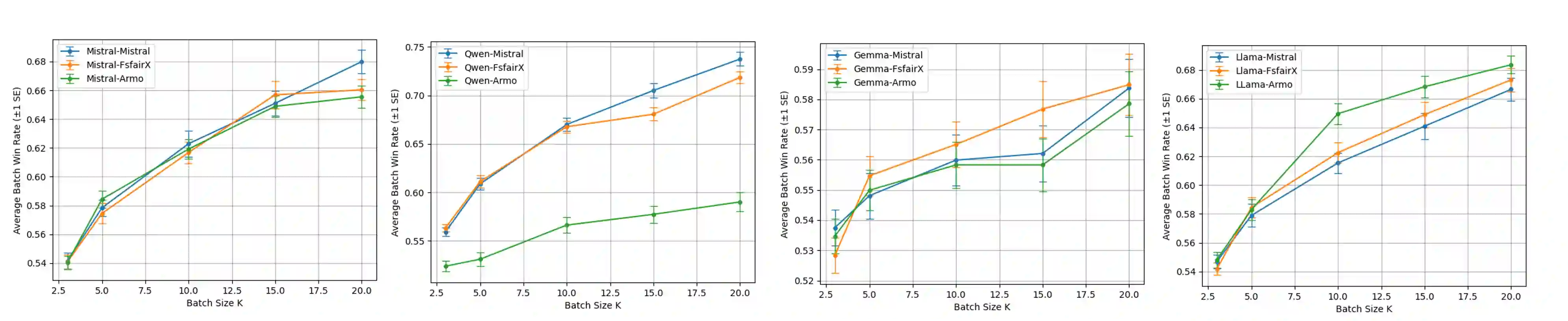
Recent advances in test-time alignment methods, such as Best-of-N sampling, offer a simple and effective way to steer language models (LMs) toward preferred behaviors using reward models (RM). However, these approaches can be computationally expensive, especially when applied uniformly across prompts without accounting for differences in alignment difficulty. In this work, we propose a prompt-adaptive strategy for Best-of-N alignment that allocates inference-time compute more efficiently. Motivated by latency concerns, we develop a two-stage algorithm: an initial exploratory phase estimates the reward distribution for each prompt using a small exploration budget, and a second stage adaptively allocates the remaining budget using these estimates. Our method is simple, practical, and compatible with any LM-RM combination. Empirical results on prompts from the AlpacaEval, HH-RLHF, and PKU-SafeRLHF datasets for 12 LM/RM pairs and 50 different batches of prompts show that our adaptive strategy outperforms the uniform allocation with the same inference budget. Moreover, we show that our adaptive strategy remains competitive against uniform allocations with 20 percent larger inference budgets and improves in performance as the batch size grows.
翻译:近年来,测试时对齐方法(如最佳N选择采样)的进展提供了一种简单有效的方式,利用奖励模型引导语言模型朝向期望行为。然而,这些方法计算成本较高,特别是在跨提示词均匀应用而未考虑对齐难度差异时。本研究提出一种面向最佳N选择对齐的提示词自适应策略,以更高效地分配推理时计算资源。基于延迟考量,我们开发了一种两阶段算法:初始探索阶段使用少量探索预算估计每个提示词的奖励分布;第二阶段则基于这些估计自适应分配剩余预算。该方法简洁实用,兼容任意语言模型-奖励模型组合。在AlpacaEval、HH-RLHF和PKU-SafeRLHF数据集提示词上的实证结果表明,针对12组语言模型/奖励模型配对及50组不同提示词批次,我们的自适应策略在相同推理预算下均优于均匀分配方案。此外,实验证明该策略在推理预算增加20%的情况下仍能保持与均匀分配的竞争力,且其性能随批次规模扩大而持续提升。