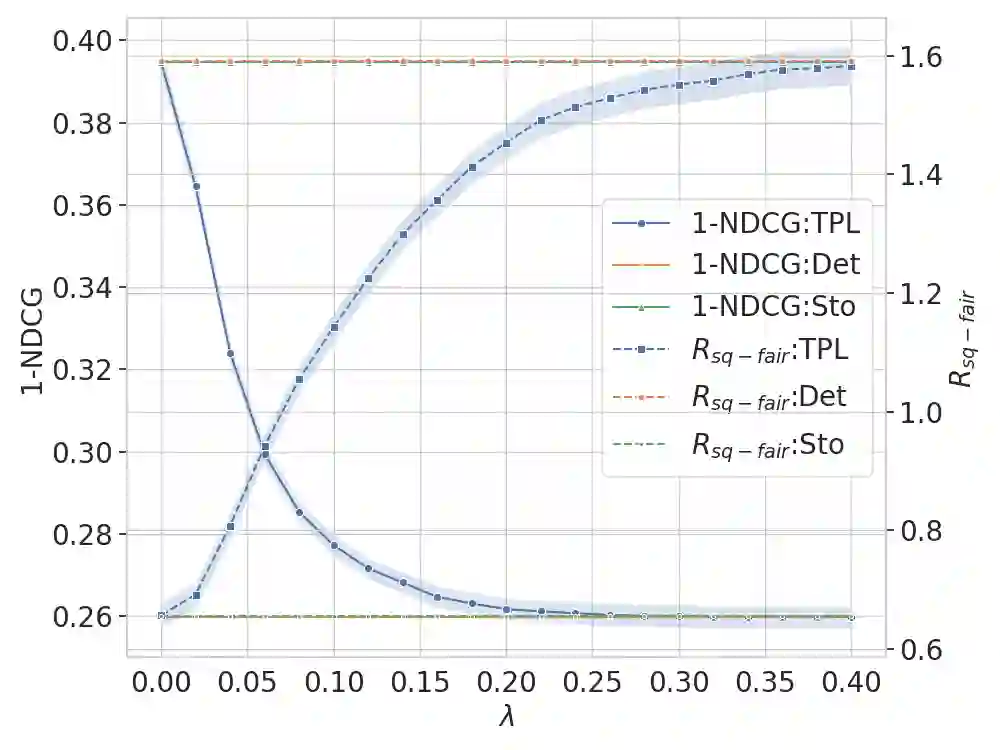
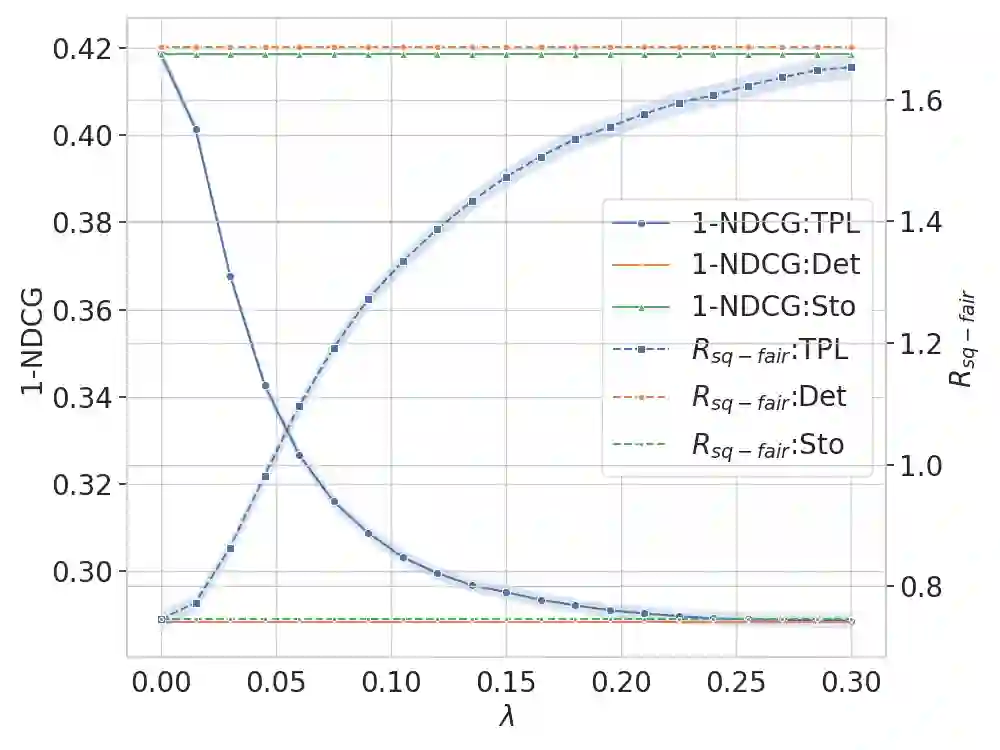
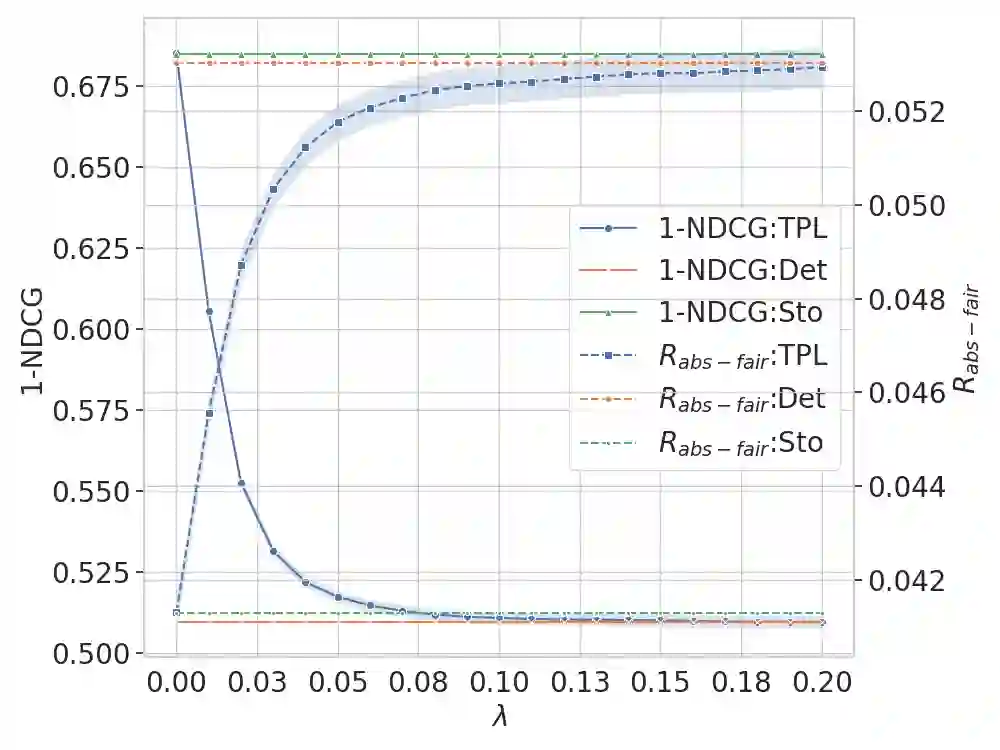
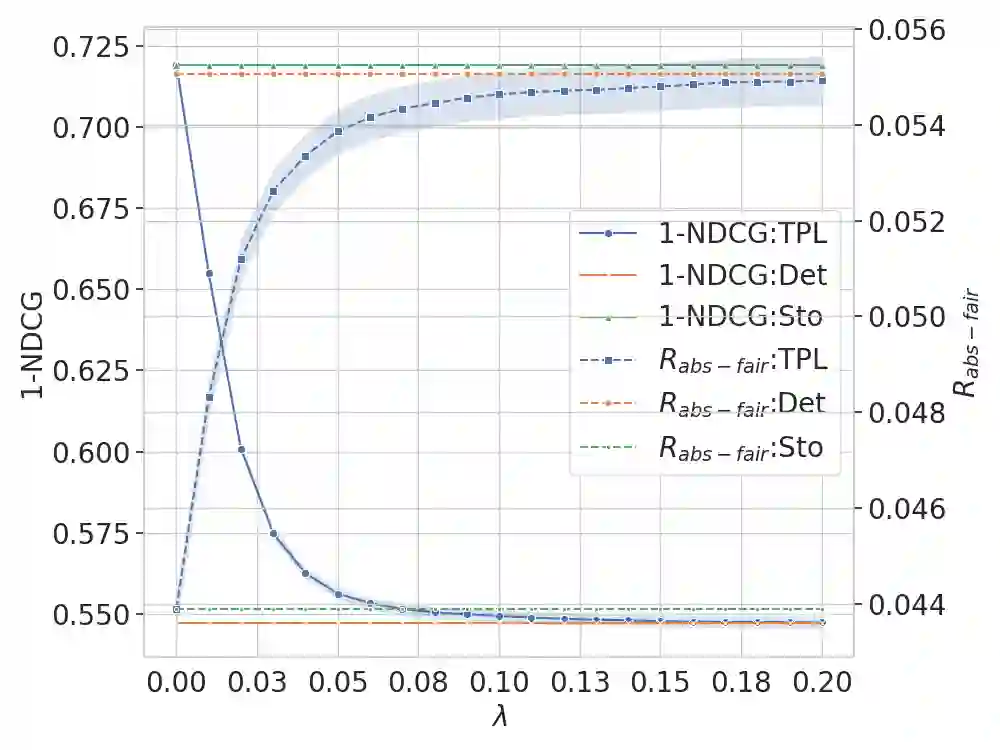
Learning to Rank (LTR) methods are vital in online economies, affecting users and item providers. Fairness in LTR models is crucial to allocate exposure proportionally to item relevance. The deterministic ranking model can lead to unfair exposure distribution when items with the same relevance receive slightly different scores. Stochastic LTR models, incorporating the Plackett-Luce (PL) model, address fairness issues but have limitations in computational cost and performance guarantees. To overcome these limitations, we propose FairLTR-RC, a novel post-hoc model-agnostic method. FairLTR-RC leverages a pretrained scoring function to create a stochastic LTR model, eliminating the need for expensive training. Furthermore, FairLTR-RC provides finite-sample guarantees on a user-specified utility using distribution-free risk control framework. By additionally incorporating the Thresholded PL (TPL) model, we are able to achieve an effective trade-off between utility and fairness. Experimental results on several benchmark datasets demonstrate that FairLTR-RC significantly improves fairness in widely-used deterministic LTR models while guaranteeing a specified level of utility.
翻译:排序学习方法在在线经济中至关重要,影响着用户和物品提供者。排序模型的公平性对于按物品相关性比例分配曝光度至关重要。当具有相同相关性的物品获得略微不同的评分时,确定性排序模型可能导致不公平的曝光分布。采用Plackett-Luce模型的随机排序模型解决了公平性问题,但在计算成本和性能保证方面存在局限性。为克服这些局限性,我们提出FairLTR-RC,一种新颖的事后模型无关方法。FairLTR-RC利用预训练评分函数构建随机排序模型,无需昂贵的训练。此外,FairLTR-RC通过分布自由风险控制框架,在用户指定效用上提供有限样本保证。通过额外引入阈值Plackett-Luce模型,我们能够实现效用与公平性之间的有效权衡。在多个基准数据集上的实验结果表明,FairLTR-RC在保证指定效用水平的同时,显著提升了广泛使用的确定性排序模型的公平性。