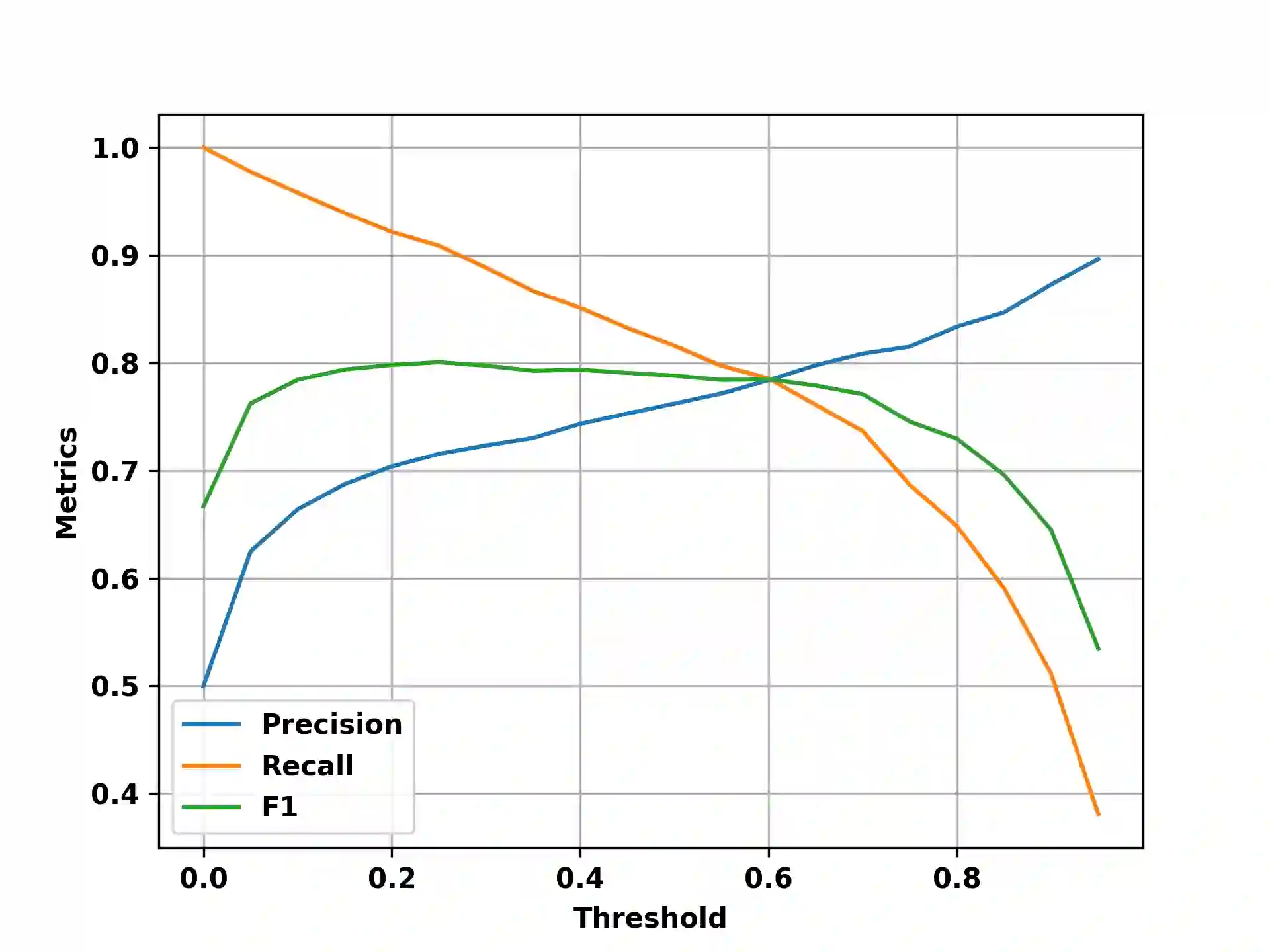
Matching binary to source code and vice versa has various applications in different fields, such as computer security, software engineering, and reverse engineering. Even though there exist methods that try to match source code with binary code to accelerate the reverse engineering process, most of them are designed to focus on one programming language. However, in real life, programs are developed using different programming languages depending on their requirements. Thus, cross-language binary-to-source code matching has recently gained more attention. Nonetheless, the existing approaches still struggle to have precise predictions due to the inherent difficulties when the problem of matching binary code and source code needs to be addressed across programming languages. In this paper, we address the problem of cross-language binary source code matching. We propose GraphBinMatch, an approach based on a graph neural network that learns the similarity between binary and source codes. We evaluate GraphBinMatch on several tasks, such as cross-language binary-to-source code matching and cross-language source-to-source matching. We also evaluate our approach performance on single-language binary-to-source code matching. Experimental results show that GraphBinMatch outperforms state-of-the-art significantly, with improvements as high as 15% over the F1 score.
翻译:摘要:将二进制代码与源代码进行匹配,反之亦然,在计算机安全、软件工程和逆向工程等多个领域具有广泛应用。尽管已有方法尝试将源代码与二进制代码匹配以加速逆向工程过程,但多数方法仅针对单一编程语言设计。然而,在实际应用中,程序会根据需求采用不同的编程语言开发,因此跨语言的二进制与源代码匹配问题近年来受到更多关注。尽管如此,现有方法在面对跨编程语言的二进制代码与源代码匹配时,仍因固有困难而难以实现精确预测。本文聚焦于跨语言二进制源代码匹配问题,提出GraphBinMatch方法——一种基于图神经网络的技术,用于学习二进制代码与源代码之间的相似性。我们在多个任务上评估了GraphBinMatch,包括跨语言二进制-源代码匹配和跨语言源代码-源代码匹配,同时验证了其在单语言二进制-源代码匹配中的性能。实验结果表明,GraphBinMatch显著优于现有最先进方法,F1分数提升高达15%。