
ACL 2026综述 | 大规模手语数据集:资源、基准与标注标准
论文标题:Sign-Language Datasets at Scale: A Comprehensive Survey on Resources, Benchmarks, and Annotation Standards 论文链接:https://arxiv.org/abs/2606.19352 项目链接:https://github.com/Ginqwerty/Open-Sign-Language 作者:Yiming Ni, Zhi-Qi Cheng, Jiayu Li, Wei Cheng

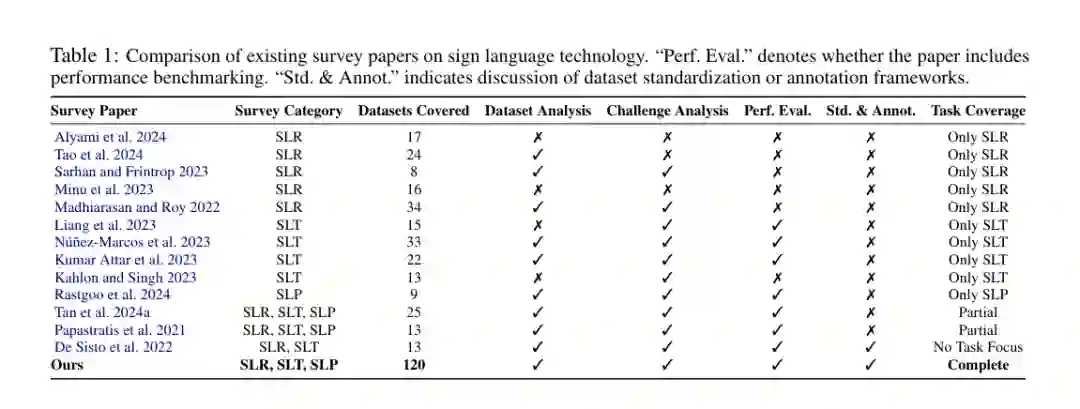
手语是聋人和听障群体使用的完整视觉-手势语言。近年来,手语识别、手语翻译和手语生成快速发展,但真正制约模型进步的,往往不是单个网络结构,而是数据资源:数据集碎片化、标注层级不一致、语言覆盖不均衡、评测基准偏窄,导致模型很难从实验室场景走向真实交流场景。 这篇 ACL 2026 Main 综述从数据集视角系统梳理手语技术,覆盖 120 个公开记录的数据集、35 种手语语言,以及识别、翻译、生成三类核心任务。论文不仅整理资源,还汇总 benchmark 结果、分析地理和语言偏差、讨论标注工具与元数据完整性,并提出 24 字段 Sign-Language Datasheet,希望为可复现、可比较、可扩展的手语 AI 研究提供标准化基础。 导读
这篇综述的主线很明确:手语 AI 的瓶颈已经从“有没有模型”转向“有没有足够可靠、覆盖充分、标注一致的数据”。 第一,手语任务不是单一识别问题。论文把任务划分为手语识别 SLR、手语翻译 SLT、手语生成 SLP,并进一步区分孤立识别、连续识别、gloss-based 翻译、gloss-free 翻译、检索式生成、全帧合成、骨架关键点和 3D mesh 等设置。 第二,数据集生态高度不均衡。公开资源集中在 ASL、DGS、CSL、BSL 等高资源手语,许多非洲、原住民和村落手语几乎没有公开数据;同时,很多数据集缺少 signer demographics、hand dominance、采集条件、标注指南和一致性指标。 第三,当前排行榜不能直接代表真实应用能力。PHOENIX14T 等数据集标注规范、可复现性好,但领域窄;CSL-Daily、How2Sign、YouTube-ASL 等更贴近日常或开放域,却存在规模、标注和访问成本上的取舍。论文因此主张用统一 datasheet 和更细粒度评测来连接资源、基准与真实部署需求。
1 Introduction | 引言
论文开篇强调,全球有超过 7000 万聋人和听障用户使用手语。手语并不是口语的简单手势化版本,而是通过手形、位置、运动、方向,以及面部表情、口型、凝视、身体姿态等多通道信号共同表达意义。 自动手语技术主要有三个方向:识别、翻译和生成。识别关注从视频到 gloss 或类别标签;翻译关注从手语视频到口语文本;生成则反向从文本或 gloss 合成手语动作、关键点或视频。

作者指出,已有综述多聚焦单一任务,如只讨论 SLR 或 SLT;本文则覆盖 SLR、SLT、SLP 三类任务,整理 120 个数据集,并同时讨论数据集分析、挑战、性能评测和标准化标注框架。
2 Background | 背景
手语数据集的难点首先来自语言本身。手语包含 manual channel 和 non-manual channel:前者包括手形、位置、运动和方向,后者包括面部表情、口型、视线和姿态。二者并非严格同步,很多语法信息可能由面部或身体信号承担,这使得传统单序列建模很难完整表达。 由于多数手语缺乏标准书写系统,研究通常依赖 gloss 作为中间表示。Gloss 将手语符号近似映射到口语词,但它并不等价于自然语言翻译,也无法完全表示空间语法、非手部信号和语义细节。另一类表示如 HAMNOSYS 更细粒度,但标注成本更高。 论文将手语处理任务分为三类:
- 手语识别:包括单个词或字母的孤立识别,也包括连续视频中的 gloss 序列识别。
- 手语翻译:从手语视频生成口语文本,可分为 gloss-based 与 gloss-free。
- 手语生成:从文本或 gloss 合成手语视频、骨架关键点、pose 或 3D 表达。
这一路线也对应研究演化:早期集中在 fingerspelling 和孤立词识别,随后转向连续识别、句子级翻译和视频生成。但论文提醒,研究进步高度集中在少数高资源语言和少数 benchmark 上。
3 Dataset Compendium | 数据集汇编
论文将数据集分为三类:fingerspelling 数据集、isolated sign language 数据集和 continuous sign language 数据集。前者通常包含字母或数字的静态图像/短视频,适合入门识别;孤立手语数据集包含单个手语词或短片段;连续手语数据集则包含更长句子或自然表达,是 CSLR、SLT 和 SLP 的关键资源。
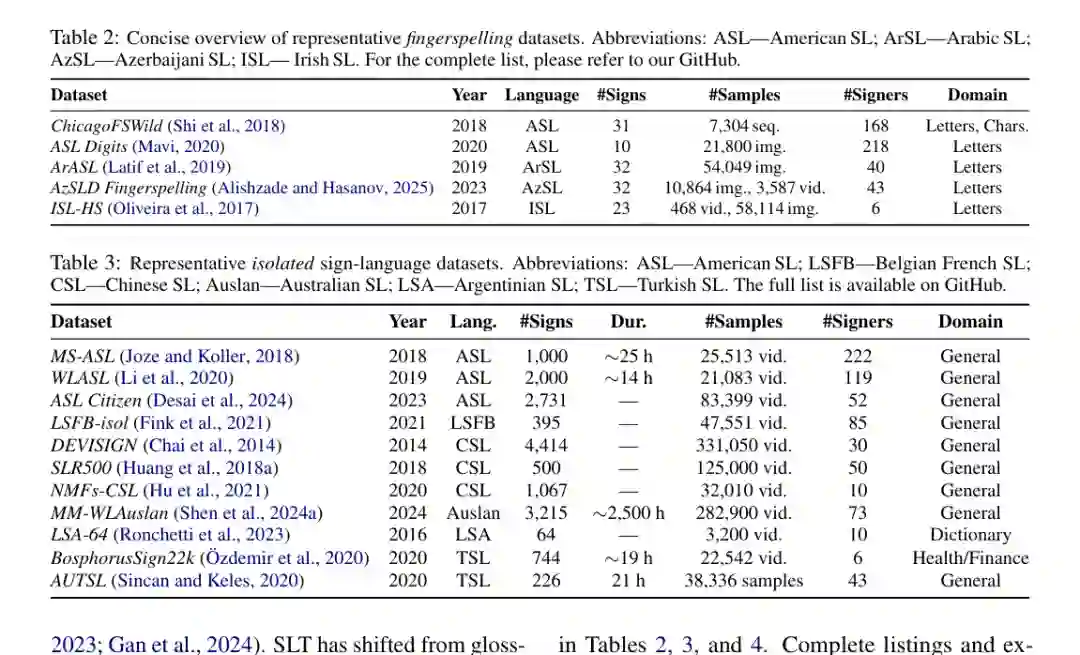
连续手语数据集更接近真实交流,但也更难收集和标注。论文比较了 PHOENIX14T、CSL-Daily、How2Sign、YouTube-ASL、OpenASL 等旗舰语料。它们的差异不只是规模,还包括语言、时长、词表、signer 数量、领域、可访问性、标注层级和文件格式。
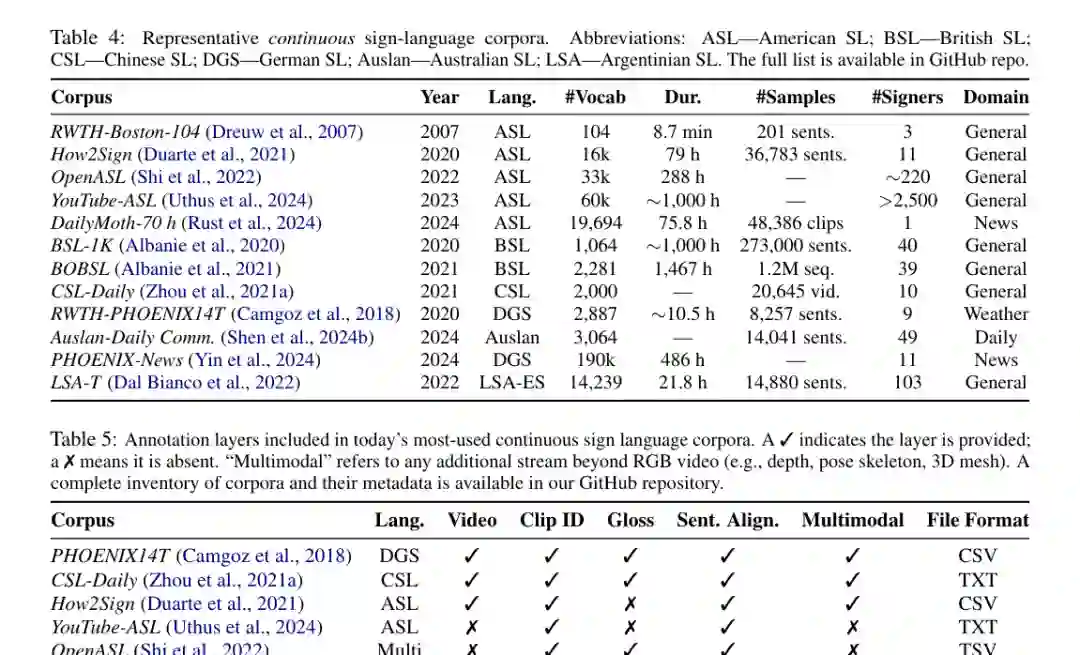
一个关键观察是,数据规模大不等于适合所有任务。YouTube-ASL、OpenASL 规模大、开放域强,但可能缺少 pose/depth 或同步标注;PHOENIX14T 标注整洁、易复现,却领域窄、训练样本少;CSL-Daily 更贴近日常表达,但存在访问和录制场景上的限制。这些差异决定了模型能力的边界。
4 Benchmarks & Leaderboards | 基准与排行榜
论文对五个广泛使用的 benchmark 做了系统汇总,包括 PHOENIX14T、CSL-Daily、How2Sign、YouTube-ASL 和 OpenASL,并按 SLR、SLT、SLP 任务汇总代表模型结果。 在连续手语识别中,PHOENIX14T 的最佳 WER 可以低至 17.9%,CSL-Daily 则更高,最低约 24.1%。论文认为,这并不简单意味着某个模型更强,而是反映了数据集差异:PHOENIX14T 领域更窄、标注更一致;CSL-Daily 更贴近日常表达,signer、主题和录制条件更多样,因此更能考验泛化。

手语翻译方面,论文比较了 gloss-based 和 gloss-free 两类方法。Gloss-based 方法通常在 PHOENIX14T 上取得较高 BLEU,因为中间 gloss 提供了结构化监督;但 gloss 标注昂贵、跨语料标准不统一。Gloss-free 方法减少标注依赖,更容易扩展到低资源语言和开放域,但当前性能仍受数据规模、视频质量和语义对齐影响。

手语生成方面,论文汇总了 Gloss-to-Pose 和 Text-to-Pose 模型。作者特别强调,SLP 评测不能只依赖 BLEU,因为生成结果还涉及动作自然性、时间一致性、手部与面部细节、感知质量和人工可理解性。未来评测应结合 MPJPE、Hand-MJE、timing F1、视频质量指标和 DHH 社群参与的人类评价。

5 Dataset Challenges | 数据集挑战
论文将数据集问题概括为几个结构性挑战。 首先是访问与可持续性。虽然已有 100 多个手语数据集,但并非都能稳定访问。一些早期数据集链接失效,部分数据需要 NDA 或机构审批,另一些只提供视频 ID,长期可复现性依赖外部平台。 其次是语言与地理不均衡。公开数据集中 ASL、DGS、CSL、BSL 等高资源手语占主导,许多非洲、原住民和村落手语缺乏代表性数据。即便在同一语言内部,地区、方言、年龄、性别、hand dominance 等 signer-level 属性也常常缺失。

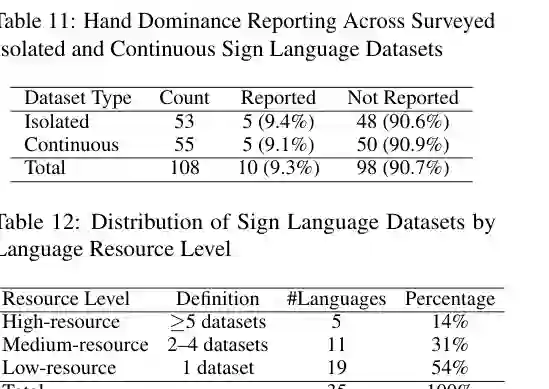
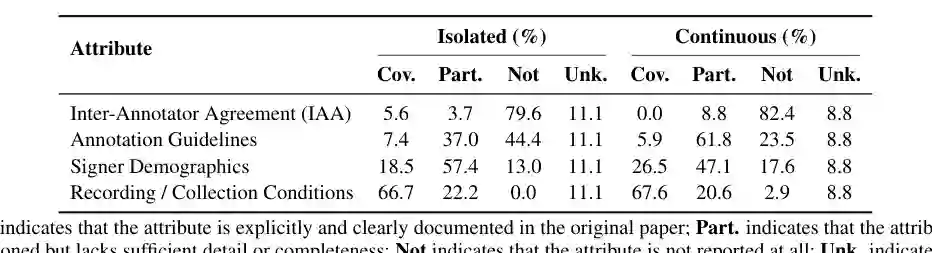
第三是模态与标注不一致。不同数据集可能提供 RGB、depth、pose、flow、skeleton、sentence alignment、gloss 或 3D mesh 等不同层级;即使都提供 gloss,不同语料的字段命名、粒度和对齐方式也可能不一致。这会显著增加预处理成本,并削弱跨数据集训练。 第四是元数据完整性不足。论文特别指出,hand dominance 是手语建模中的重要属性,但在 108 个被统计的数据集中,只有 10 个明确报告左右手优势信息,约 90.7% 未报告。这类缺失会影响 signer bias、模型泛化和公平性评估。
6 Future Dataset Curation | 未来数据集构建
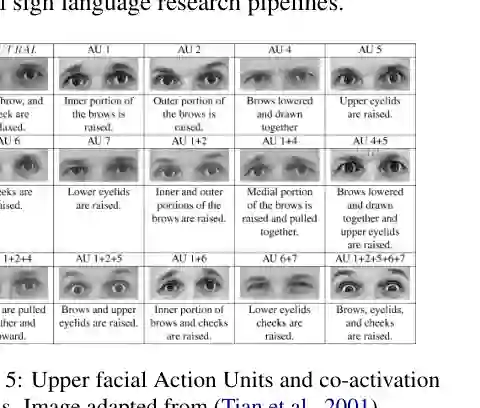
论文第 6 节提出面向未来手语数据集的构建建议,核心是让数据更真实、更可比、更可复现。 视频选择应覆盖问候、医疗、教育、紧急情况、日常生活、新闻等真实场景。来自 YouTube 等开放平台的视频有助于增加主题多样性,但必须过滤低清、噪声和无效片段,因为手部细节和面部信号对手语理解至关重要。长视频应按语义边界切分,减少空闲帧。 数据集也需要主动平衡 signer 属性,包括年龄、性别、地区、方言和手部优势。论文特别建议在划分评测集时考虑 hand dominance,以避免模型过度适配右手优势签名模式。 标注策略上,作者建议采用模块化层级:最低层应包含唯一 ID 和清洗后的句子级翻译;之后可逐步加入 gloss、时间边界、pose/skeleton、非手部信号和 Facial Action Units。这样可以先发布可用数据,再逐步丰富细粒度语言标注。
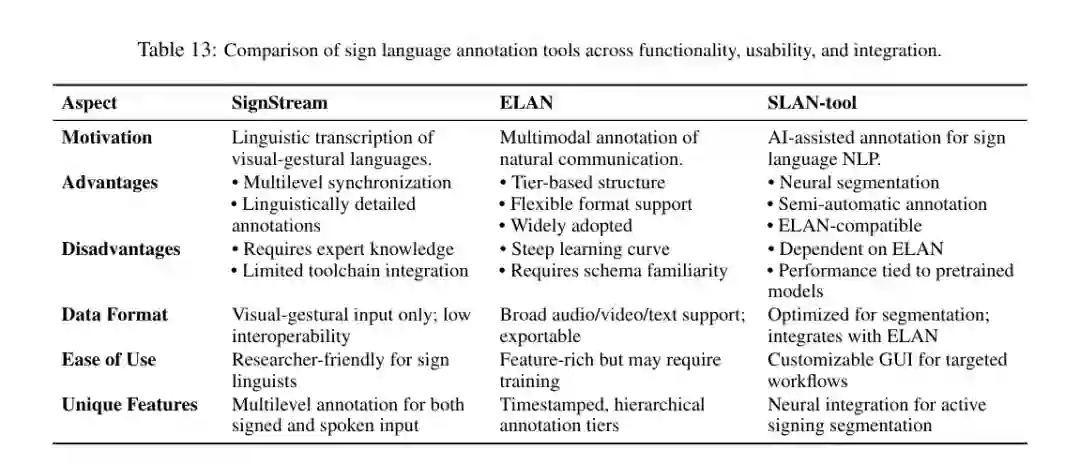
标注工具方面,ELAN 仍是最广泛使用的平台,支持层级式、多模态、可导出的标注结构;SignStream 更面向语言学细粒度转写;SLAN-tool 则提供 AI 辅助分割和半自动标注能力。论文认为,不同工具的选择应服务于长期可读性、可互操作性和维护成本。
论文提出的 24 字段 Sign-Language Datasheet 正是为了解决这些问题:让每个数据集系统记录语言、采集方式、模态、signer 信息、标注层级、任务适配、许可、可访问性和评测设置。它不是最终合规标准,而是一个可演化的文档框架。
7 Conclusion | 结论
这篇综述用数据集视角重新审视手语 AI:如果训练数据覆盖不足、标注不一致、元数据缺失、基准过窄,那么模型即使在排行榜上进步,也很难保证真实世界泛化。 论文的贡献可以概括为四点:整理 120 个数据集和 35 种手语;系统分析 modality imbalance、signer bias、annotation inconsistency 和 benchmark fragmentation;汇总 SLR、SLT、SLP 的代表性排行榜;提出 24 字段 datasheet 和公开 GitHub 仓库,推动标准化文档与可复现评测。 从研究启发看,下一阶段手语技术不应只追求更高 BLEU、更低 WER 或更大模型,而应把数据设计、社群参与、标注标准、伦理治理和真实可用性放在同等重要的位置。真正可用的手语 AI,必须服务于 DHH 社群的沟通需求,而不是只在少数高资源 benchmark 上取得漂亮数字。
8 Limitations | 局限
作者也明确列出本文局限:公开语料仍集中在 ASL、DGS、CSL、BSL 等高资源手语;元数据直接来自原论文和仓库,可能存在缺失;定量排行榜只覆盖五个旗舰通用数据集;UMAP 可视化依赖单一随机种子;24 字段 datasheet 尚未经过 DHH 社群充分验证。
Broader Impact & Ethical Considerations | 更广泛影响与伦理考虑
伦理层面,手语数据包含可识别面孔和身体动作,必须重视 signer privacy、许可条款和访问控制。另一方面,如果 benchmark 主要由白人、西方或高资源语言 signer 构成,模型可能对少数群体表现更差,放大已有不平等。论文因此强调,未来数据集建设需要 community-led collection,让聋人社群参与设计、审核和反馈,而不仅仅把手语数据当作视觉识别素材。