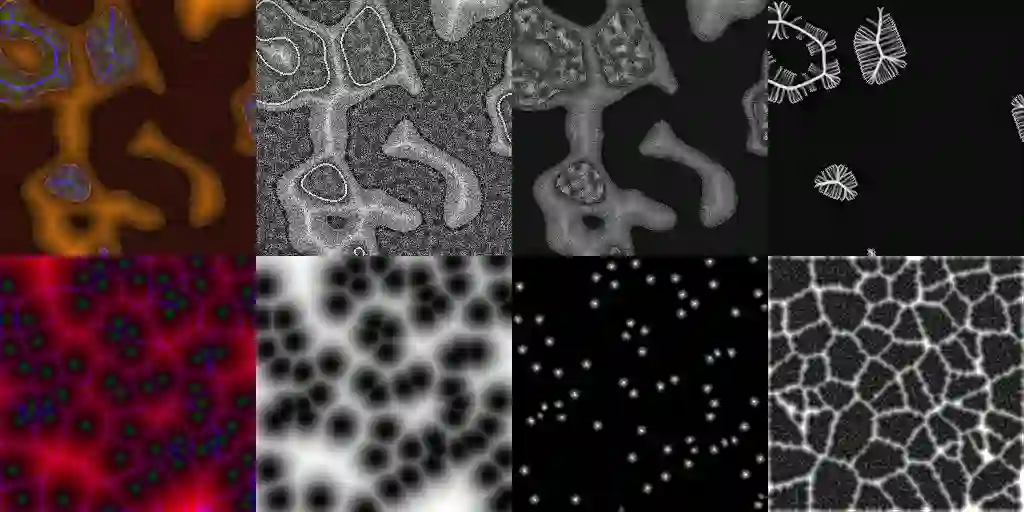
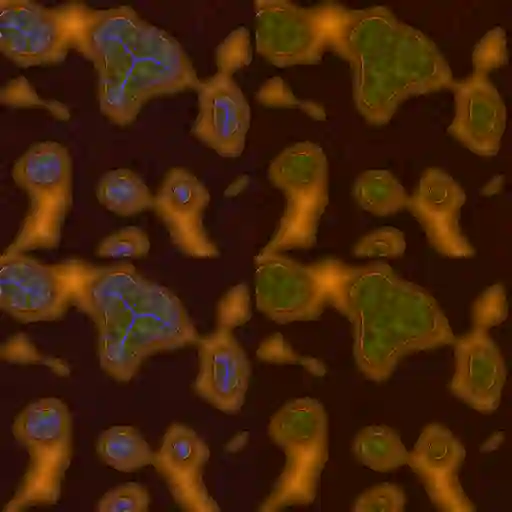
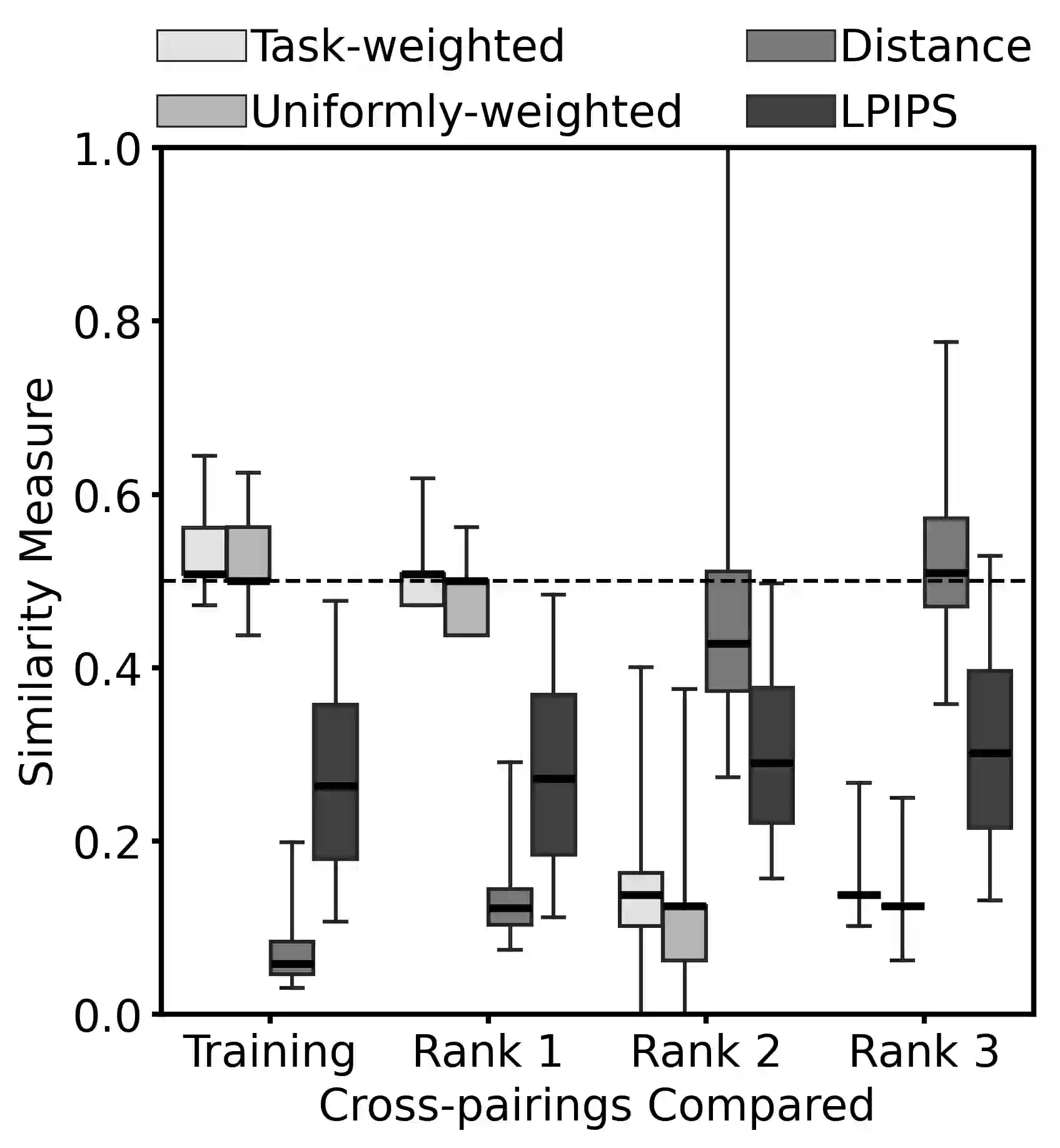
Super-resolution, in-painting, whole-image generation, unpaired style-transfer, and network-constrained image reconstruction each include an aspect of machine-learned image synthesis where the actual ground truth is not known at time of use. It is generally difficult to quantitatively and authoritatively evaluate the quality of synthetic images; however, in mission-critical biomedical scenarios robust evaluation is paramount. In this work, all practical image-to-image comparisons really are relative qualifications, not absolute difference quantifications; and, therefore, meaningful evaluation of generated image quality can be accomplished using the Tversky Index, which is a well-established measure for assessing perceptual similarity. This evaluation procedure is developed and then demonstrated using multiple image data sets, both real and simulated. The main result is that when the subjectivity and intrinsic deficiencies of any feature-encoding choice are put upfront, Tversky's method leads to intuitive results, whereas traditional methods based on summarizing distances in deep feature spaces do not.
翻译:超分辨率、图像修复、全图像生成、非配对风格迁移以及网络约束图像重建均涉及机器学习图像合成的某个方面,其中实际真值在使用时未知。通常难以对合成图像质量进行定量且权威的评估;然而,在任务关键的生物医学场景中,稳健的评估至关重要。本工作中,所有实际的图像间比较本质上都是相对定性评估,而非绝对差异量化;因此,生成图像质量的实质性评估可通过Tversky指数实现,该指数是评估感知相似性的成熟度量方法。该评估流程经开发后,通过使用真实与模拟的多组图像数据集进行验证。主要结论表明:当任何特征编码选择的主观性与固有缺陷被明确前置时,Tversky方法能产生直观结果,而基于深度特征空间距离汇总的传统方法则无法实现。