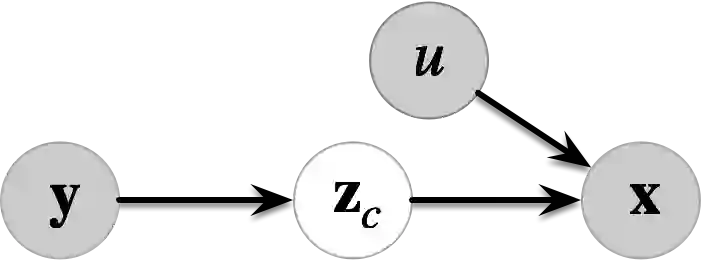
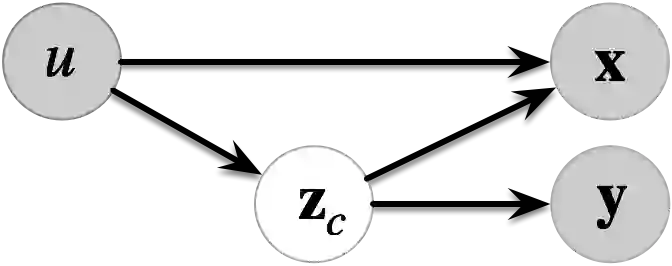
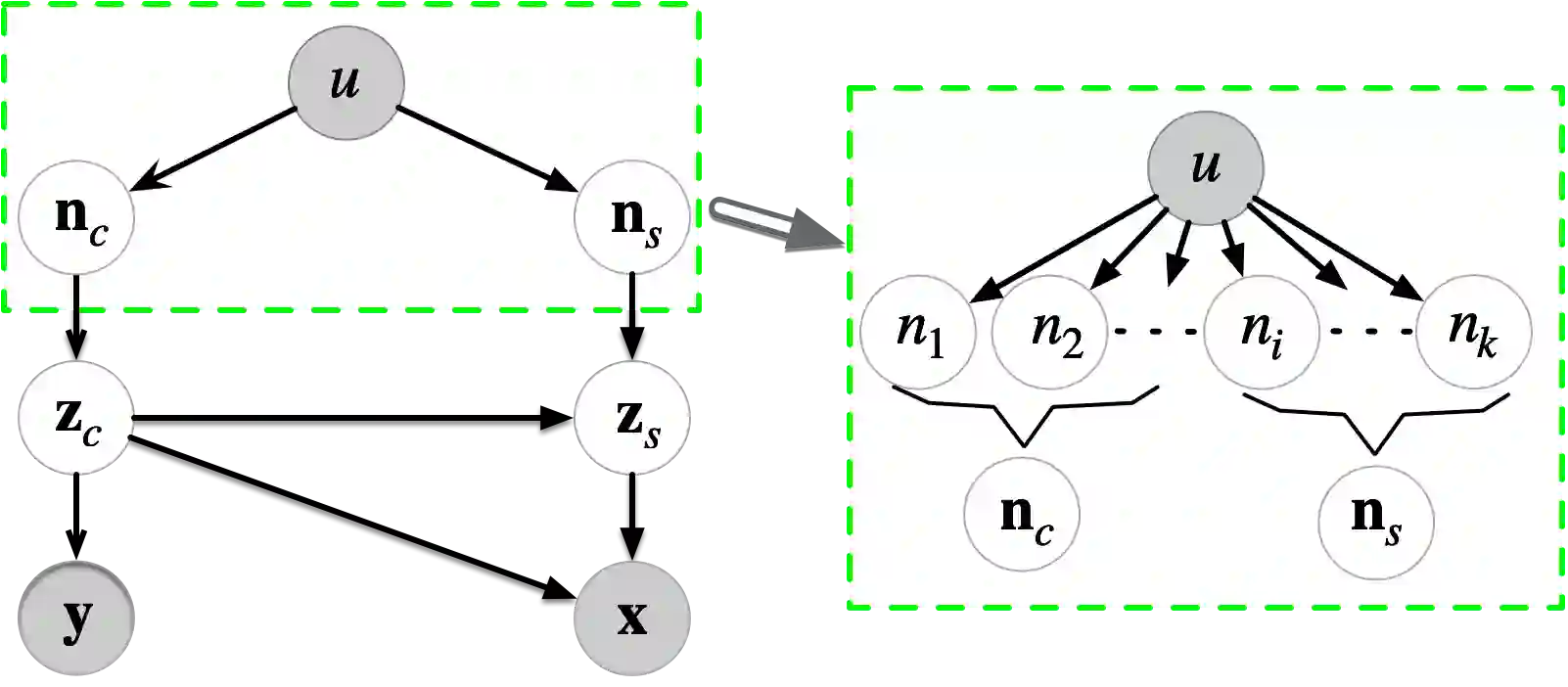
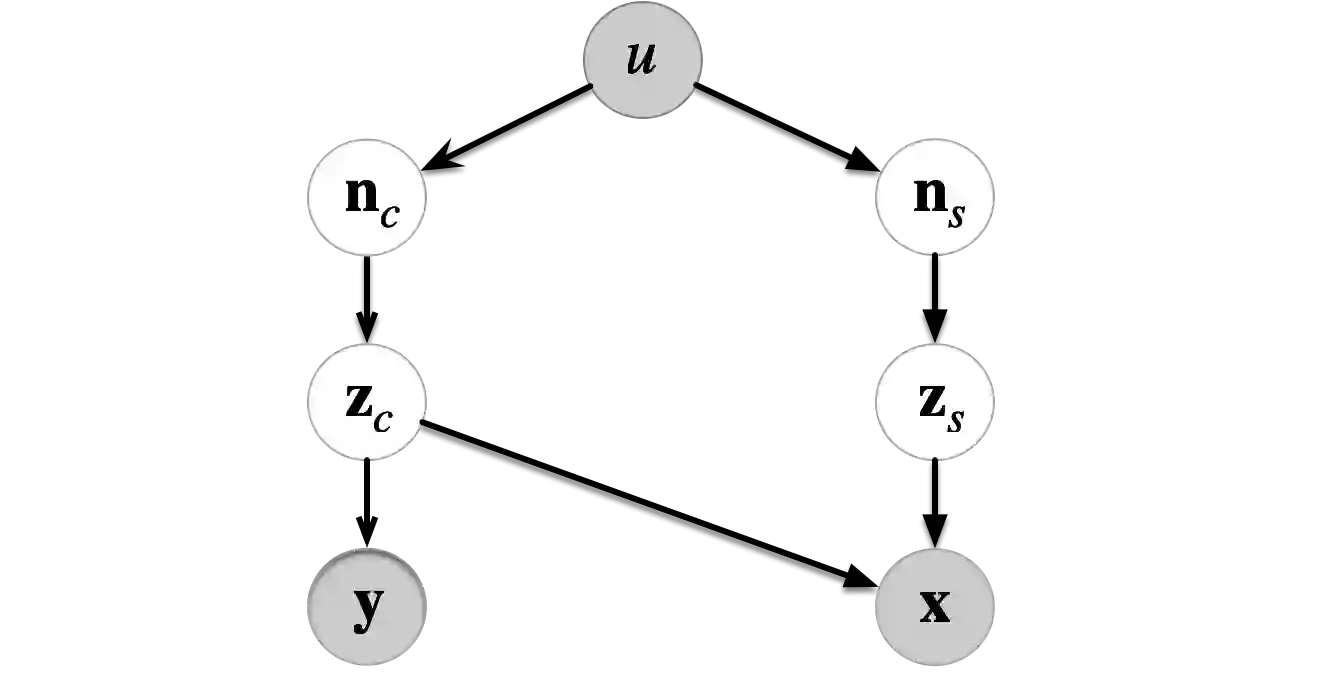
Multi-source domain adaptation (MSDA) addresses the challenge of learning a label prediction function for an unlabeled target domain by leveraging both the labeled data from multiple source domains and the unlabeled data from the target domain. Conventional MSDA approaches often rely on covariate shift or conditional shift paradigms, which assume a consistent label distribution across domains. However, this assumption proves limiting in practical scenarios where label distributions do vary across domains, diminishing its applicability in real-world settings. For example, animals from different regions exhibit diverse characteristics due to varying diets and genetics. Motivated by this, we propose a novel paradigm called latent covariate shift (LCS), which introduces significantly greater variability and adaptability across domains. Notably, it provides a theoretical assurance for recovering the latent cause of the label variable, which we refer to as the latent content variable. Within this new paradigm, we present an intricate causal generative model by introducing latent noises across domains, along with a latent content variable and a latent style variable to achieve more nuanced rendering of observational data. We demonstrate that the latent content variable can be identified up to block identifiability due to its versatile yet distinct causal structure. We anchor our theoretical insights into a novel MSDA method, which learns the label distribution conditioned on the identifiable latent content variable, thereby accommodating more substantial distribution shifts. The proposed approach showcases exceptional performance and efficacy on both simulated and real-world datasets.
翻译:多源域适应(MSDA)旨在通过利用来自多个源域的标记数据以及目标域的无标记数据,学习针对无标记目标域的标签预测函数。传统的MSDA方法通常依赖于协变量偏移或条件偏移范式,这些范式假设跨域的标签分布保持一致。然而,在实际场景中,标签分布确实会随域而变化,这一假设限制了其适用性。例如,由于饮食和遗传的差异,来自不同地区的动物表现出多样化的特征。受此启发,我们提出了一种称为潜在协变量偏移(LCS)的新范式,该范式引入了显著更大的跨域变异性和适应性。值得注意的是,它为恢复标签变量的潜在原因(我们称之为潜在内容变量)提供了理论保证。在这一新范式中,我们通过引入跨域的潜在噪声,以及一个潜在内容变量和一个潜在风格变量,提出了一个精细的因果生成模型,以实现对观测数据更细致的渲染。我们证明,由于其灵活而独特的因果结构,潜在内容变量可以达到块可识别性。我们将理论洞见锚定于一种新颖的MSDA方法中,该方法学习以可识别的潜在内容变量为条件的标签分布,从而适应更显著的分布偏移。所提出的方法在模拟和真实数据集上均展现出卓越的性能和有效性。