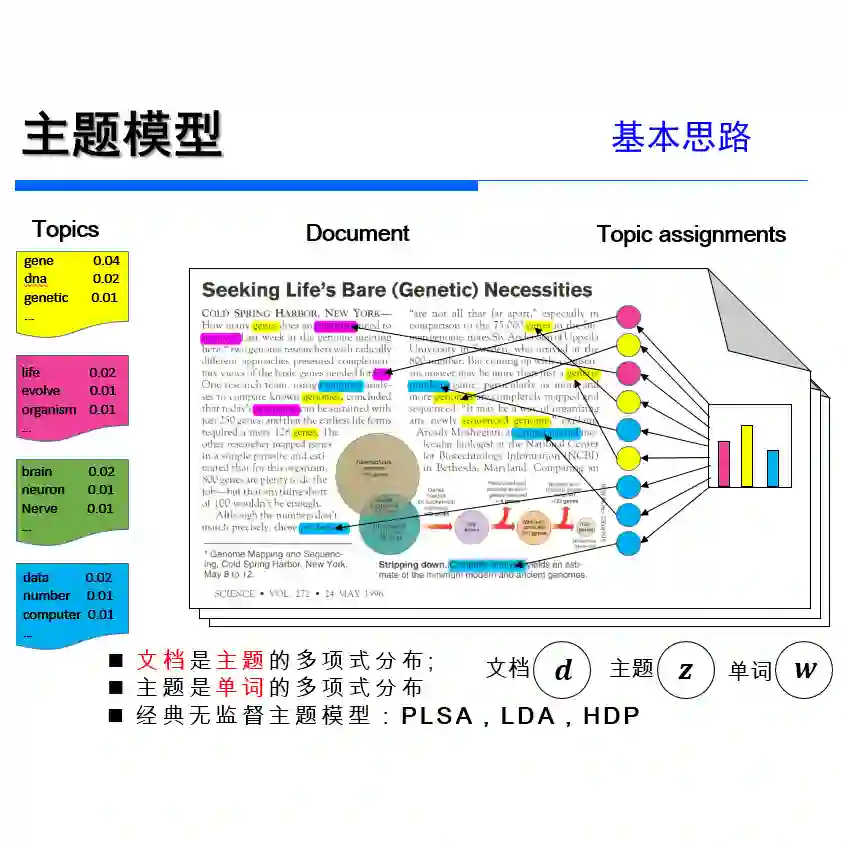
Topic modeling has emerged as a dominant method for exploring large document collections. Recent approaches to topic modeling use large contextualized language models and variational autoencoders. In this paper, we propose a negative sampling mechanism for a contextualized topic model to improve the quality of the generated topics. In particular, during model training, we perturb the generated document-topic vector and use a triplet loss to encourage the document reconstructed from the correct document-topic vector to be similar to the input document and dissimilar to the document reconstructed from the perturbed vector. Experiments for different topic counts on three publicly available benchmark datasets show that in most cases, our approach leads to an increase in topic coherence over that of the baselines. Our model also achieves very high topic diversity.
翻译:主题建模已成为探索大规模文档集合的主流方法。近年来的主题建模方法采用大规模上下文语言模型和变分自编码器。本文针对上下文主题模型提出一种负采样机制,以提升生成主题的质量。具体而言,在模型训练过程中,我们对生成的文档-主题向量进行扰动,并利用三元组损失函数促使从正确文档-主题向量重建的文档与输入文档相似,而与从扰动向量重建的文档相异。在三个公开基准数据集上针对不同主题数量的实验表明,本文方法在大多数情况下较基线模型显著提升了主题一致性。同时,我们的模型还实现了极高的主题多样性。