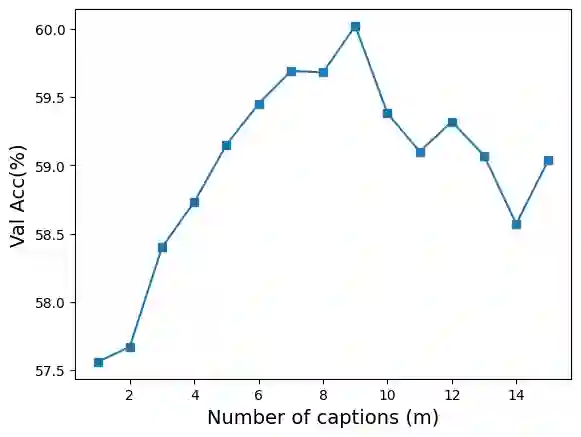
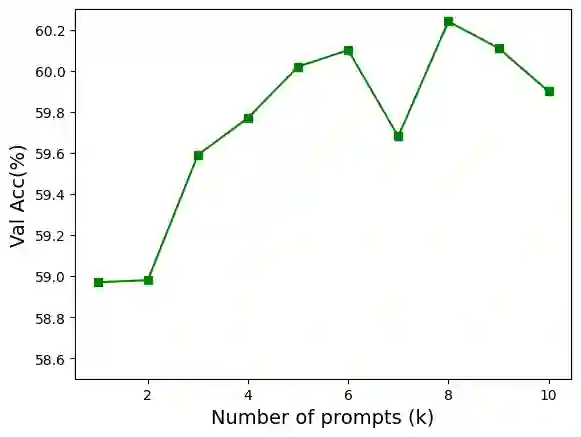
This paper is on the problem of Knowledge-Based Visual Question Answering (KB-VQA). Recent works have emphasized the significance of incorporating both explicit (through external databases) and implicit (through LLMs) knowledge to answer questions requiring external knowledge effectively. A common limitation of such approaches is that they consist of relatively complicated pipelines and often heavily rely on accessing GPT-3 API. Our main contribution in this paper is to propose a much simpler and readily reproducible pipeline which, in a nutshell, is based on efficient in-context learning by prompting LLaMA (1 and 2) using question-informative captions as contextual information. Contrary to recent approaches, our method is training-free, does not require access to external databases or APIs, and yet achieves state-of-the-art accuracy on the OK-VQA and A-OK-VQA datasets. Finally, we perform several ablation studies to understand important aspects of our method. Our code is publicly available at https://github.com/alexandrosXe/ASimple-Baseline-For-Knowledge-Based-VQA
翻译:本文研究知识基础视觉问答(KB-VQA)问题。近期研究表明,有效融合显性知识(通过外部数据库)和隐性知识(通过大语言模型)对回答需要外部知识的问题至关重要。这类方法的一个共同局限在于其流程相对复杂,且通常严重依赖GPT-3 API的访问。本文的主要贡献在于提出了一种更简单且易于复现的流程——简而言之,该方法基于高效的上下文学习,通过将包含问题信息的图像描述作为上下文信息来提示LLaMA(1和2)模型。与近期方法不同,我们的方法无需训练、无需访问外部数据库或API,同时在OK-VQA和A-OK-VQA数据集上达到了最先进的准确率。最后,我们通过多项消融实验深入分析了该方法的关键要素。我们的代码已开源,地址为https://github.com/alexandrosXe/ASimple-Baseline-For-Knowledge-Based-VQA