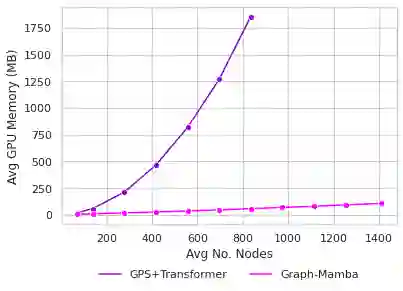
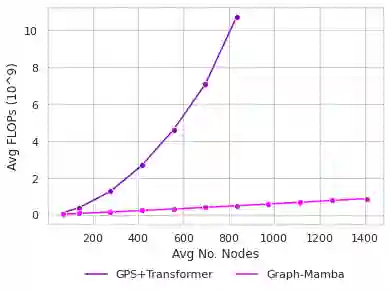
Attention mechanisms have been widely used to capture long-range dependencies among nodes in Graph Transformers. Bottlenecked by the quadratic computational cost, attention mechanisms fail to scale in large graphs. Recent improvements in computational efficiency are mainly achieved by attention sparsification with random or heuristic-based graph subsampling, which falls short in data-dependent context reasoning. State space models (SSMs), such as Mamba, have gained prominence for their effectiveness and efficiency in modeling long-range dependencies in sequential data. However, adapting SSMs to non-sequential graph data presents a notable challenge. In this work, we introduce Graph-Mamba, the first attempt to enhance long-range context modeling in graph networks by integrating a Mamba block with the input-dependent node selection mechanism. Specifically, we formulate graph-centric node prioritization and permutation strategies to enhance context-aware reasoning, leading to a substantial improvement in predictive performance. Extensive experiments on ten benchmark datasets demonstrate that Graph-Mamba outperforms state-of-the-art methods in long-range graph prediction tasks, with a fraction of the computational cost in both FLOPs and GPU memory consumption. The code and models are publicly available at https://github.com/bowang-lab/Graph-Mamba.
翻译:注意力机制已被广泛用于图Transformer中捕捉节点间的长程依赖关系。受限于二次计算复杂度,注意力机制难以在大规模图上进行扩展。近期计算效率的提升主要通过随机或基于启发式的图子采样实现注意力稀疏化,但这种方法在数据依赖的上下文推理中表现不足。状态空间模型(如Mamba)因其在序列数据中建模长程依赖的有效性和高效性而备受关注。然而,将SSM适配至非序列图数据仍面临显著挑战。本文提出Graph-Mamba,首次尝试通过将Mamba模块与输入依赖的节点选择机制相结合,增强图网络中的长程上下文建模能力。具体而言,我们设计了面向图的节点优先级排序与排列策略以提升上下文感知推理能力,从而显著改善预测性能。在十个基准数据集上的大量实验表明,Graph-Mamba在长程图预测任务中以更低的FLOPs和GPU内存消耗超越了现有最优方法,计算成本仅为其一小部分。代码与模型已公开于https://github.com/bowang-lab/Graph-Mamba。