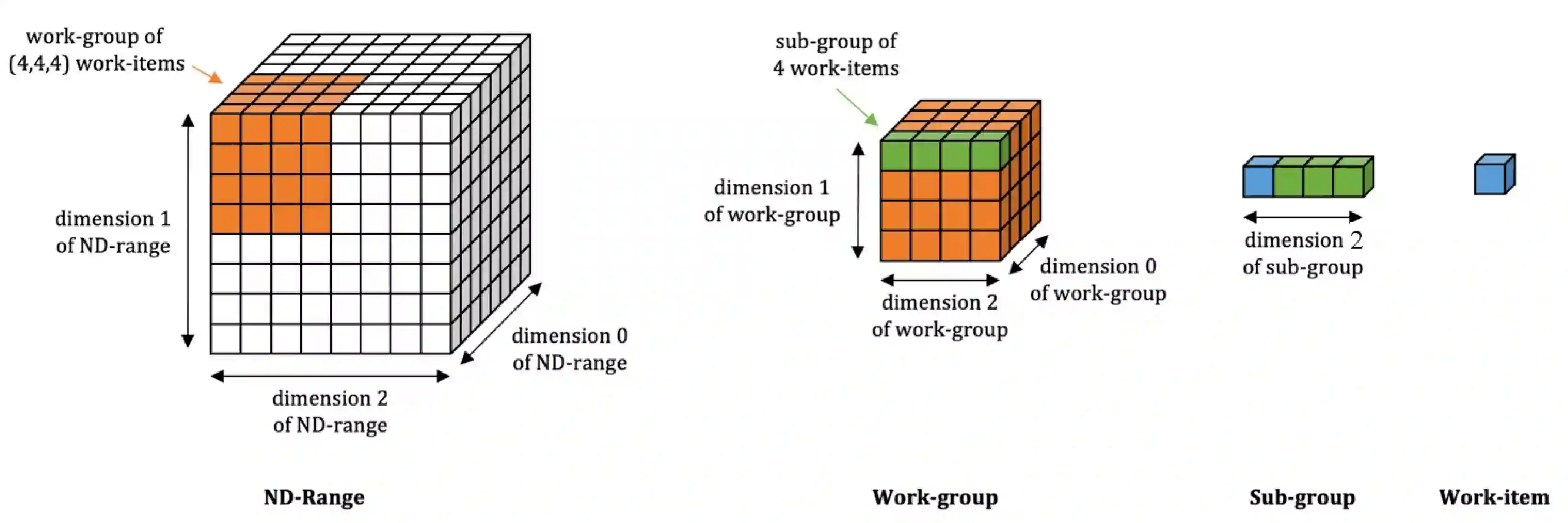
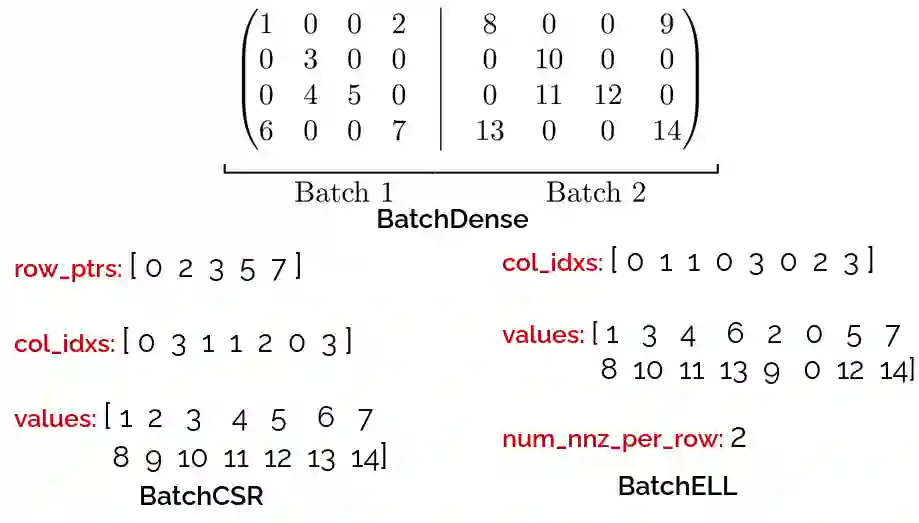
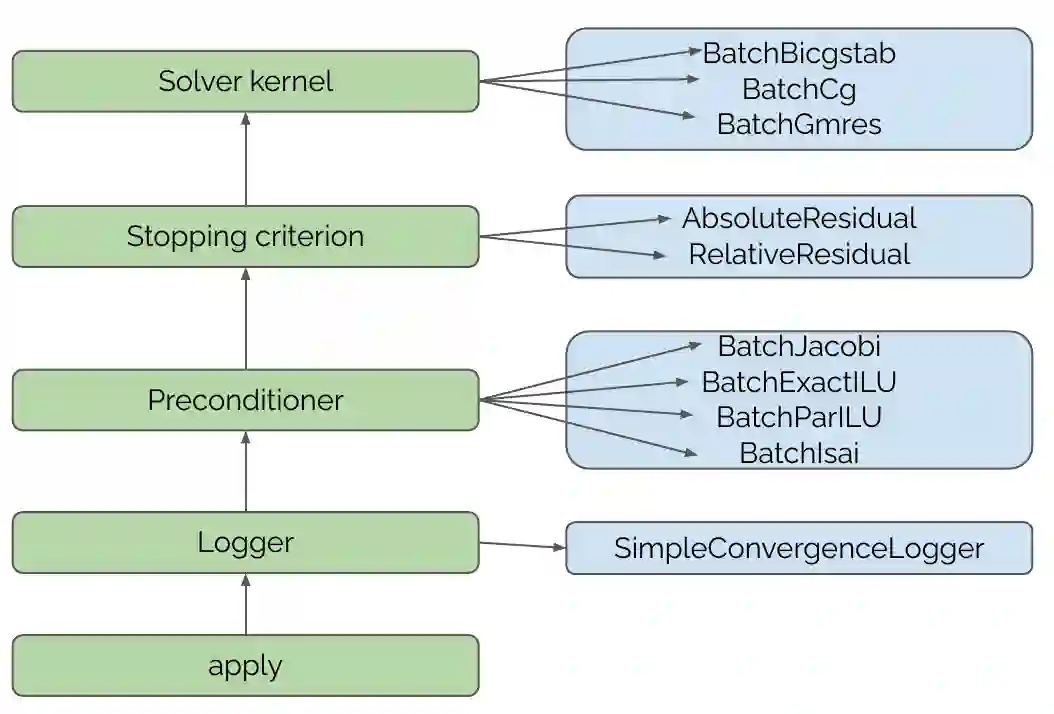
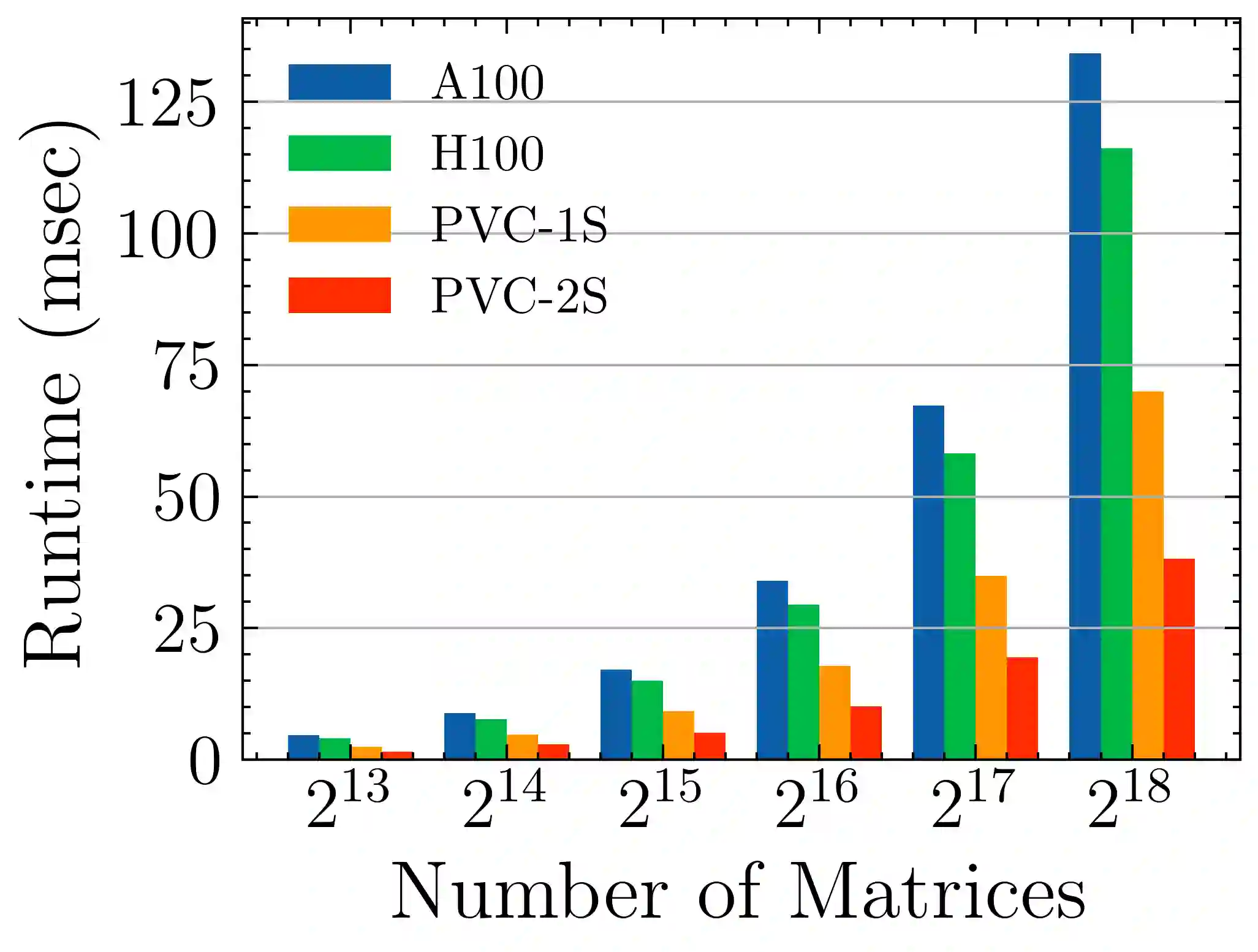
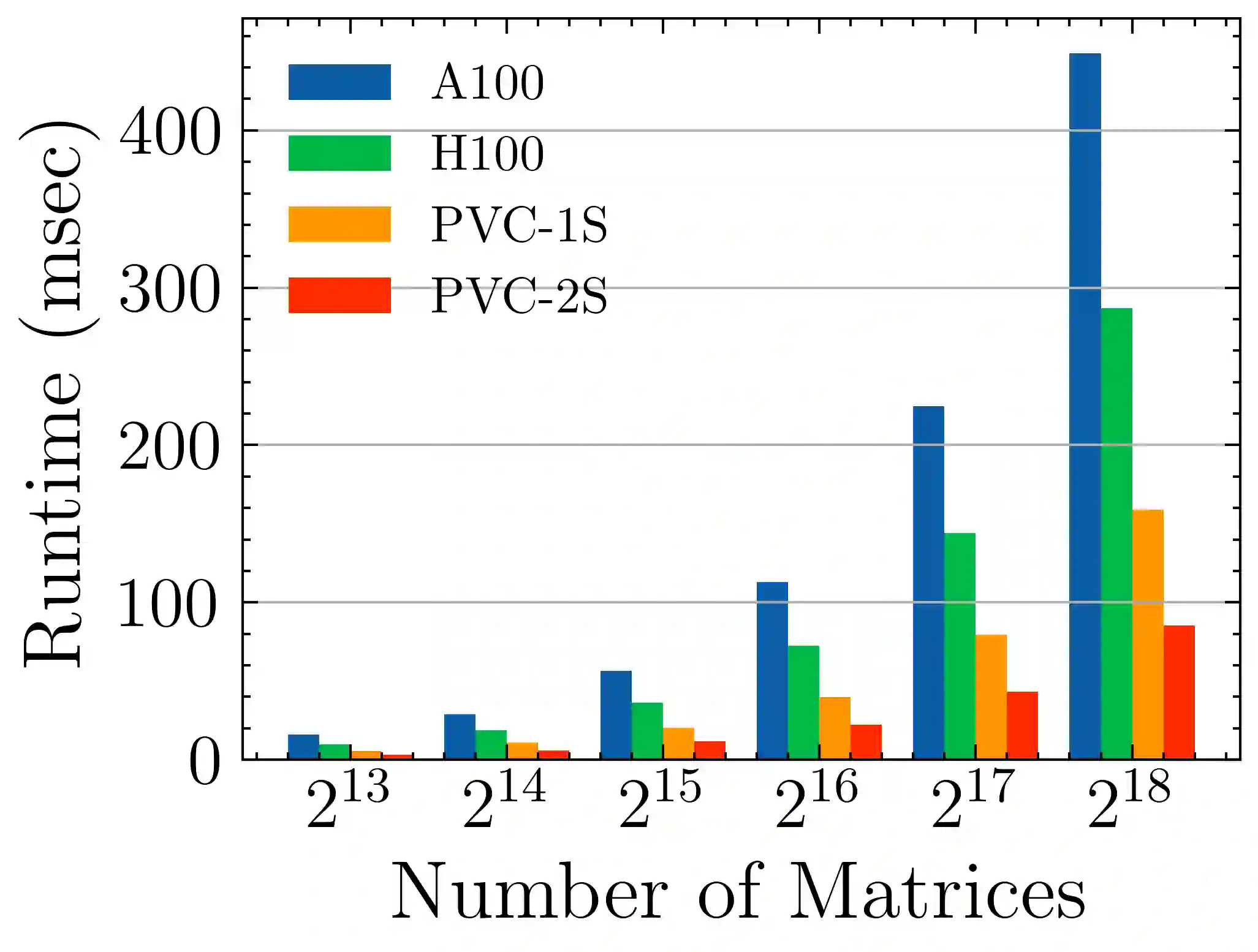
Batched linear solvers play a vital role in computational sciences, especially in the fields of plasma physics and combustion simulations. With the imminent deployment of the Aurora Supercomputer and other upcoming systems equipped with Intel GPUs, there is a compelling demand to expand the capabilities of these solvers for Intel GPU architectures. In this paper, we present our efforts in porting and optimizing the batched iterative solvers on Intel GPUs using the SYCL programming model. The SYCL-based implementation exhibits impressive performance and scalability on the Intel GPU Max 1550s (Ponte Vecchio GPUs). The solvers outperform our previous CUDA implementation on NVIDIA H100 GPUs by an average of 2.4x for the PeleLM application inputs. The batched solvers are ready for production use in real-world scientific applications through the Ginkgo library.
翻译:成批线性求解器在计算科学中扮演着关键角色,尤其是在等离子体物理和燃烧模拟领域。随着Aurora超级计算机及其他配备Intel GPU的即将问世系统的部署,扩展这些求解器在Intel GPU架构上的能力成为迫切需求。本文介绍了我们使用SYCL编程模型将成批迭代求解器移植并优化至Intel GPU上的工作。基于SYCL的实现方案在Intel GPU Max 1550s(Ponte Vecchio GPU)上展现出卓越的性能和可扩展性。针对PeleLM应用输入,该求解器性能较我们此前在NVIDIA H100 GPU上基于CUDA的实现方案平均提升2.4倍。这些成批求解器已通过Ginkgo库准备好投入实际科学应用的生产环境中使用。