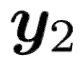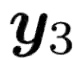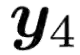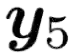Recent TTS models with decoder-only Transformer architecture, such as SPEAR-TTS and VALL-E, achieve impressive naturalness and demonstrate the ability for zero-shot adaptation given a speech prompt. However, such decoder-only TTS models lack monotonic alignment constraints, sometimes leading to hallucination issues such as mispronunciation, word skipping and repeating. To address this limitation, we propose VALL-T, a generative Transducer model that introduces shifting relative position embeddings for input phoneme sequence, explicitly indicating the monotonic generation process while maintaining the architecture of decoder-only Transformer. Consequently, VALL-T retains the capability of prompt-based zero-shot adaptation and demonstrates better robustness against hallucinations with a relative reduction of 28.3% in the word error rate. Furthermore, the controllability of alignment in VALL-T during decoding facilitates the use of untranscribed speech prompts, even in unknown languages. It also enables the synthesis of lengthy speech by utilizing an aligned context window.
翻译:近期采用仅解码器Transformer架构的文语合成模型(如SPEAR-TTS和VALL-E)展现出了出色的自然度,并具备基于语音提示进行零样本适配的能力。然而,此类仅解码器文语合成模型因缺乏单调对齐约束,时常引发幻觉问题,如发音错误、词语遗漏与重复。为解决该局限,我们提出VALL-T——一种生成式换能器模型,通过为输入音素序列引入移位相对位置嵌入,在保持仅解码器Transformer架构的同时显式标注单调生成过程。由此,VALL-T既保留了基于提示的零样本适配能力,又在抗幻觉鲁棒性方面表现更优,词错误率相对降低28.3%。此外,VALL-T在解码过程中的对齐可控性使其能够利用未转录语音提示,甚至可处理未知语言。该特性还支持通过对齐上下文窗口合成超长语音。