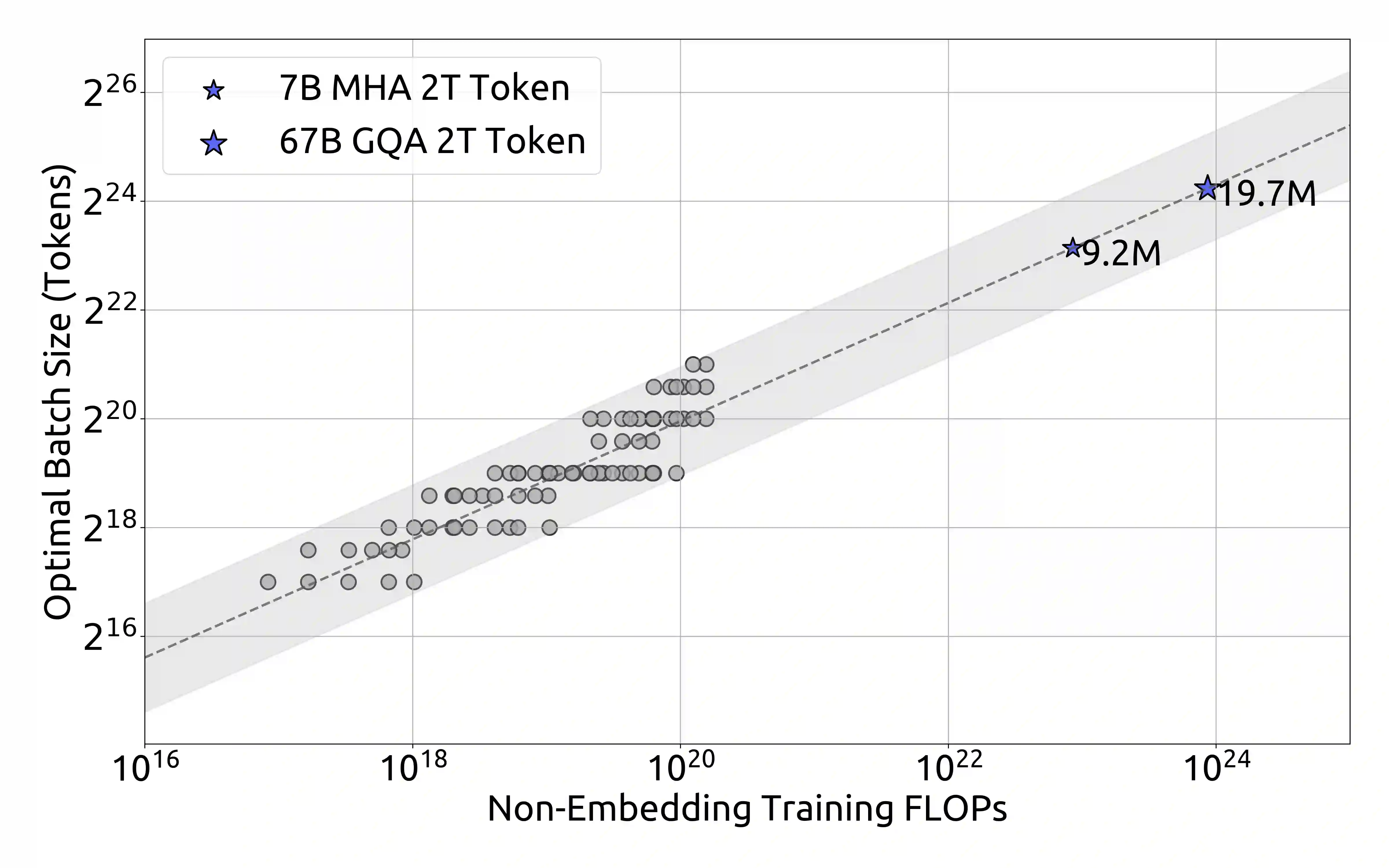
The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
翻译:开源大语言模型的快速发展令人瞩目。然而,既有文献中描述的比例缩放定律呈现出不同结论,这给大语言模型的扩展蒙上了阴影。我们深入研究了比例缩放定律,并提出了具有独特见解的发现,这些发现有助于在7B和67B两种常用开源配置下实现大规模模型的扩展。在比例缩放定律的指导下,我们推出了DeepSeek LLM项目,该项目致力于以长期视角推动开源语言模型的发展。为支持预训练阶段,我们构建了一个当前包含2万亿个词元且持续扩展的数据集。我们进一步对DeepSeek LLM基座模型进行了监督微调和直接偏好优化,从而创建了DeepSeek Chat模型。评估结果表明,DeepSeek LLM 67B在多项基准测试中超越LLaMA-2 70B,尤其在代码、数学和推理领域表现突出。此外,开放式评估显示,DeepSeek LLM 67B Chat展现出优于GPT-3.5的性能。