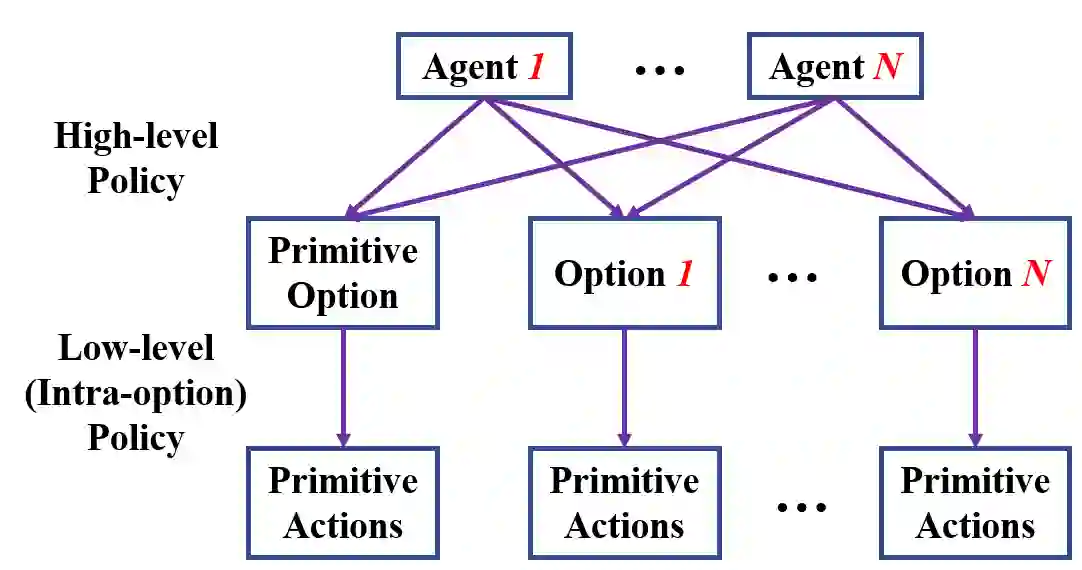
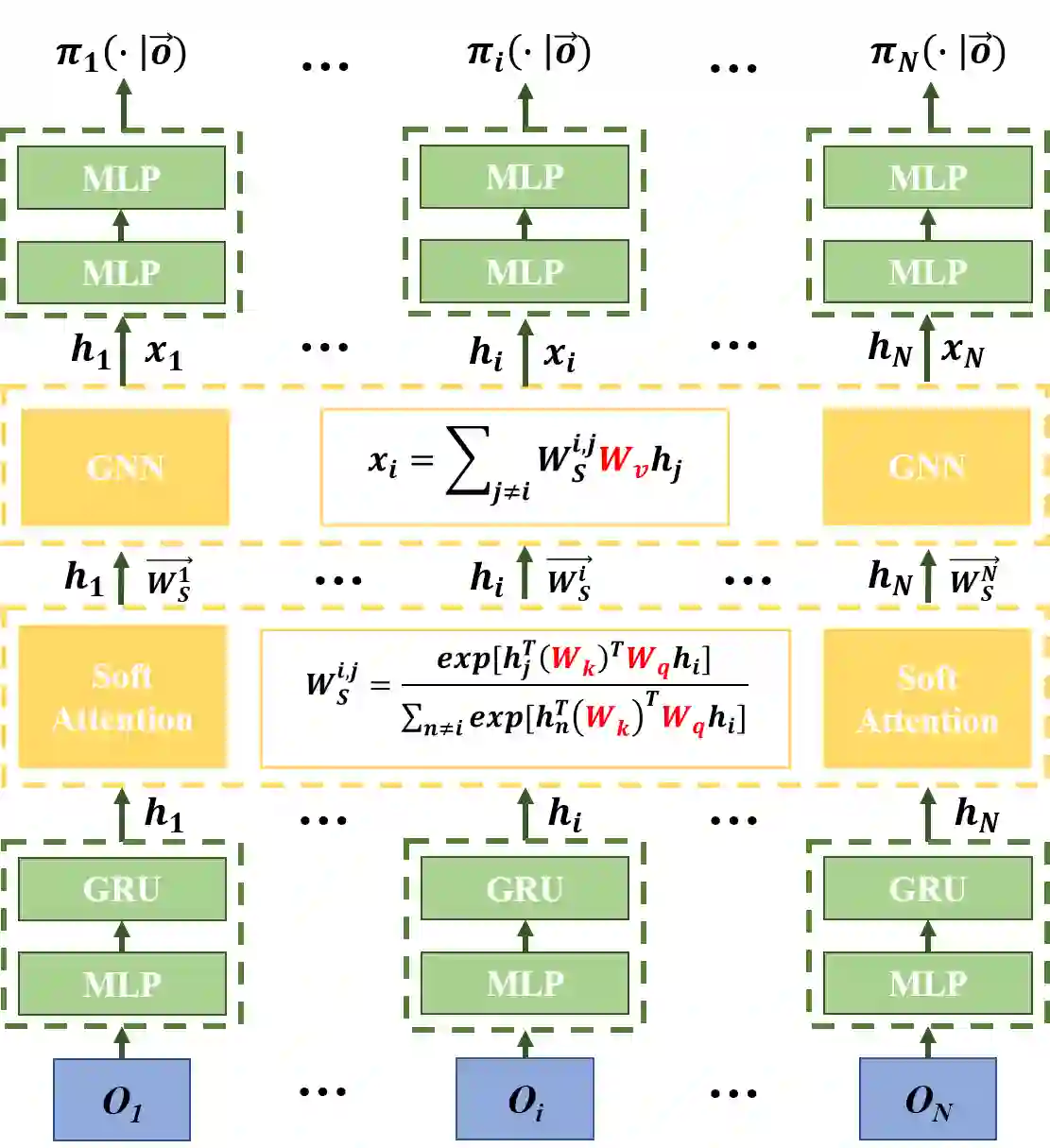
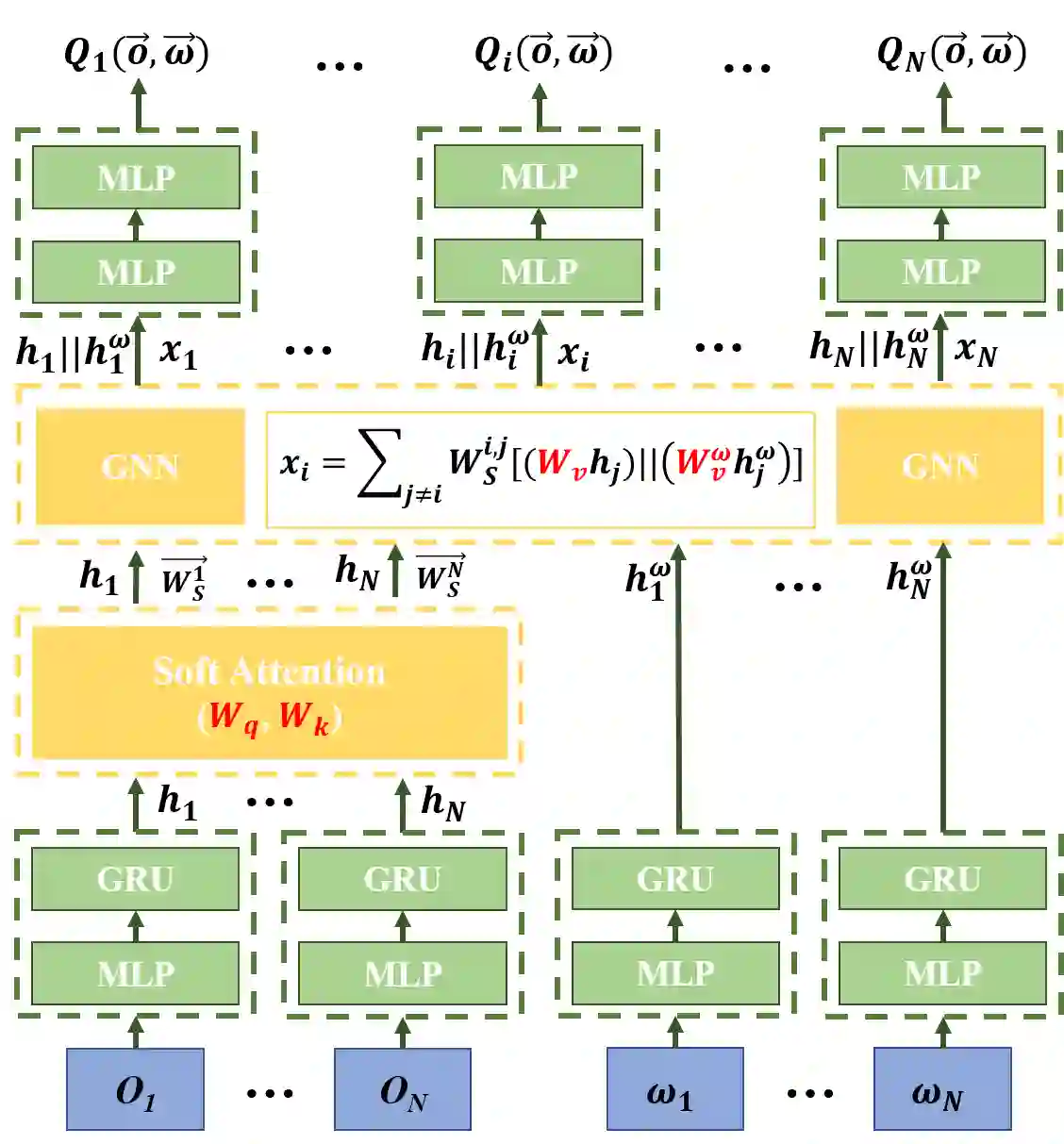
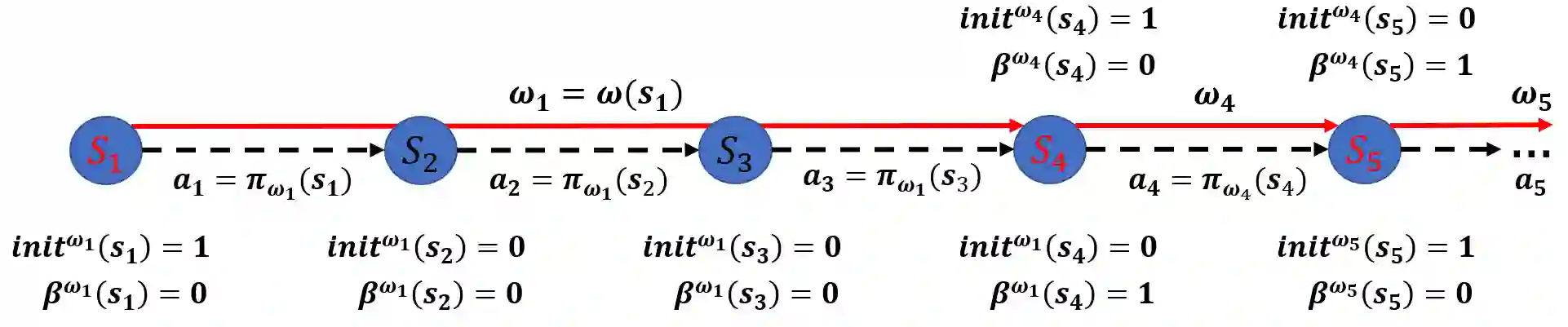
The use of skills (a.k.a., options) can greatly accelerate exploration in reinforcement learning, especially when only sparse reward signals are available. While option discovery methods have been proposed for individual agents, in multi-agent reinforcement learning settings, discovering collaborative options that can coordinate the behavior of multiple agents and encourage them to visit the under-explored regions of their joint state space has not been considered. In this case, we propose Multi-agent Deep Covering Option Discovery, which constructs the multi-agent options through minimizing the expected cover time of the multiple agents' joint state space. Also, we propose a novel framework to adopt the multi-agent options in the MARL process. In practice, a multi-agent task can usually be divided into some sub-tasks, each of which can be completed by a sub-group of the agents. Therefore, our algorithm framework first leverages an attention mechanism to find collaborative agent sub-groups that would benefit most from coordinated actions. Then, a hierarchical algorithm, namely HA-MSAC, is developed to learn the multi-agent options for each sub-group to complete their sub-tasks first, and then to integrate them through a high-level policy as the solution of the whole task. This hierarchical option construction allows our framework to strike a balance between scalability and effective collaboration among the agents. The evaluation based on multi-agent collaborative tasks shows that the proposed algorithm can effectively capture the agent interactions with the attention mechanism, successfully identify multi-agent options, and significantly outperforms prior works using single-agent options or no options, in terms of both faster exploration and higher task rewards.
翻译:使用技能(即选项)可以极大地加速强化学习中的探索过程,尤其是在仅能获得稀疏奖励信号的情况下。虽然已有针对单个智能体的选项发现方法,但在多智能体强化学习环境中,如何发现能够协调多个智能体行为、并鼓励它们共同探索联合状态空间中未充分访问区域的协作性选项,尚未得到充分研究。为此,本文提出多智能体深度覆盖选项发现方法,通过最小化多个智能体联合状态空间的期望覆盖时间来构建多智能体选项。同时,我们提出了一种新颖的框架,将多智能体选项应用于多智能体强化学习过程中。实践中,多智能体任务通常可分解为若干子任务,每个子任务可由智能体子组完成。因此,我们的算法框架首先利用注意力机制发现能从协调动作中获益最大的协作智能体子组;随后,开发层次化算法HA-MSAC,为每个子组学习多智能体选项以优先完成其子任务,并通过高层策略将其整合为整体任务的解决方案。这种层次化选项构建方式使我们的框架能够在可扩展性与智能体间有效协作之间取得平衡。基于多智能体协作任务的评估表明,所提算法能通过注意力机制有效捕捉智能体交互,成功识别多智能体选项,并在探索速度和任务奖励两方面显著优于基于单智能体选项或未使用选项的先前方法。