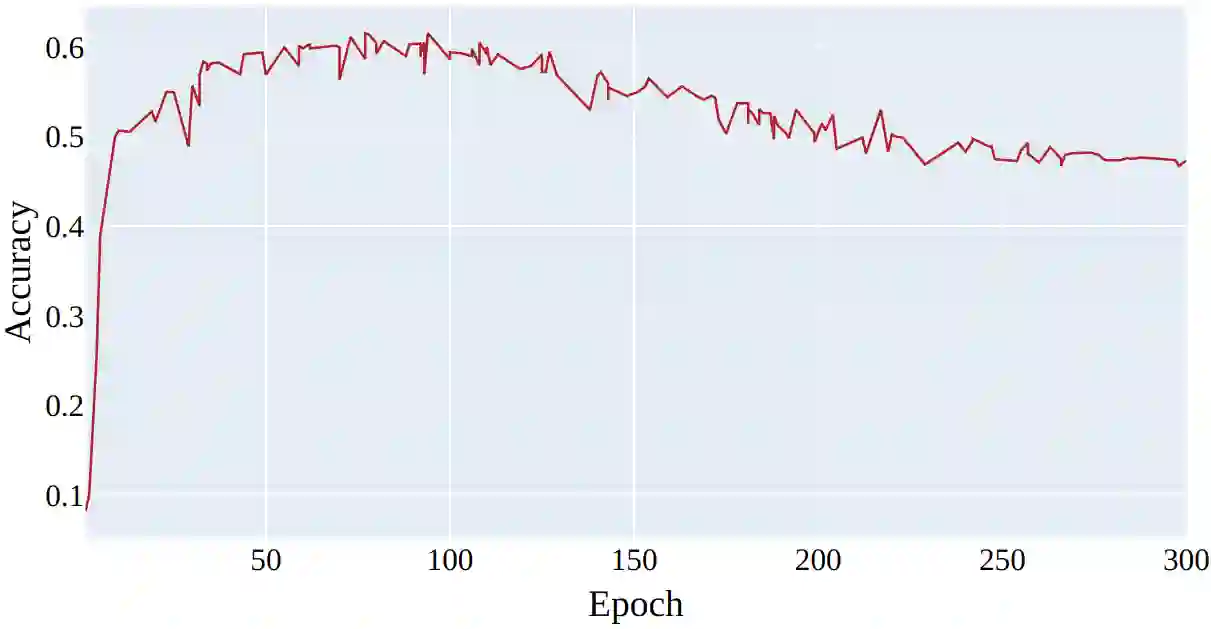
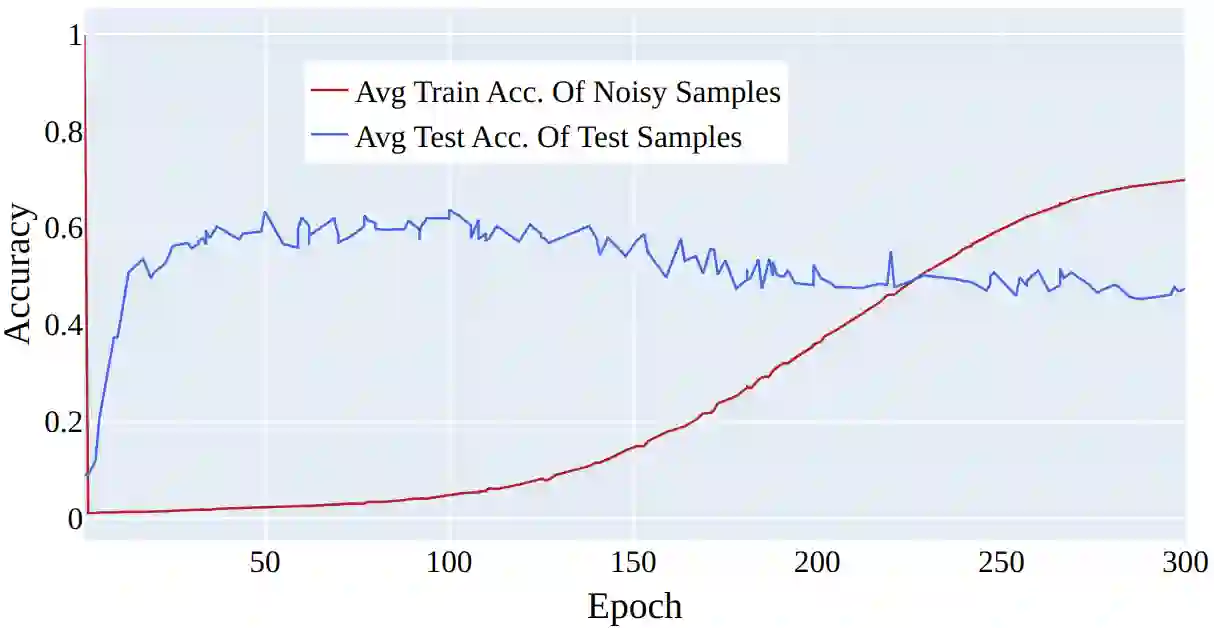
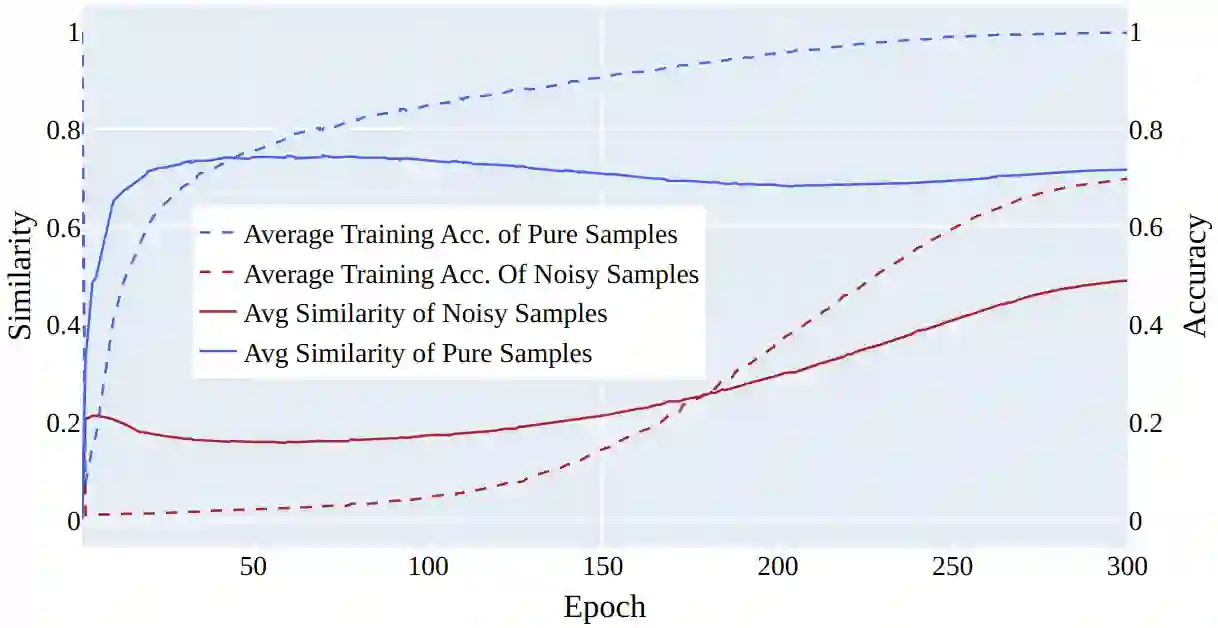
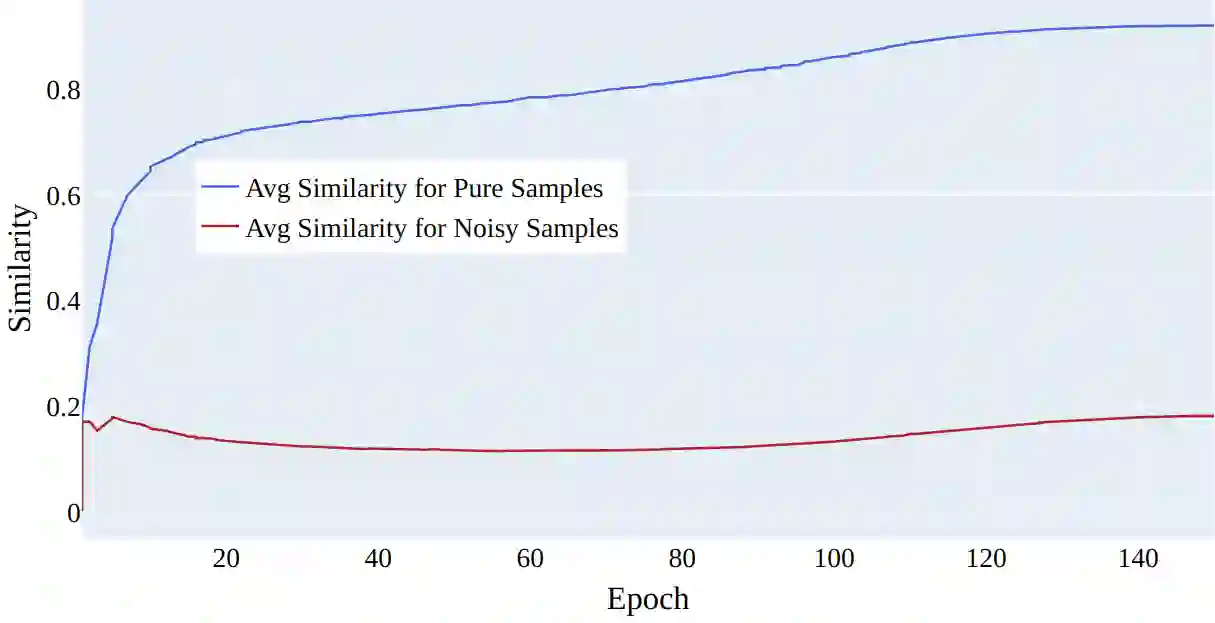
In this paper, we propose a new approach for addressing the challenge of training machine learning models in the presence of noisy labels. By combining a clever usage of distance to class centroids in the items' latent space with a discounting strategy to reduce the importance of samples far away from all the class centroids (i.e., outliers), our method effectively addresses the issue of noisy labels. Our approach is based on the idea that samples farther away from their respective class centroid in the early stages of training are more likely to be noisy. We demonstrate the effectiveness of our method through extensive experiments on several popular benchmark datasets. Our results show that our approach outperforms the state-of-the-art in this area, achieving significant improvements in classification accuracy when the dataset contains noisy labels.
翻译:本文提出了一种新方法,用于解决在噪声标签存在下训练机器学习模型的挑战。通过巧妙利用样本在潜在空间中到类别质心的距离,并结合折扣策略降低远离所有类别质心(即离群点)样本的重要性,我们的方法有效解决了噪声标签问题。该方法基于以下理念:训练初期离其对应类别质心越远的样本越可能含有噪声。通过在多个主流基准数据集上进行广泛实验,我们验证了方法的有效性。结果表明,本方法在该领域超越了现有技术,在数据集包含噪声标签时显著提升了分类准确率。