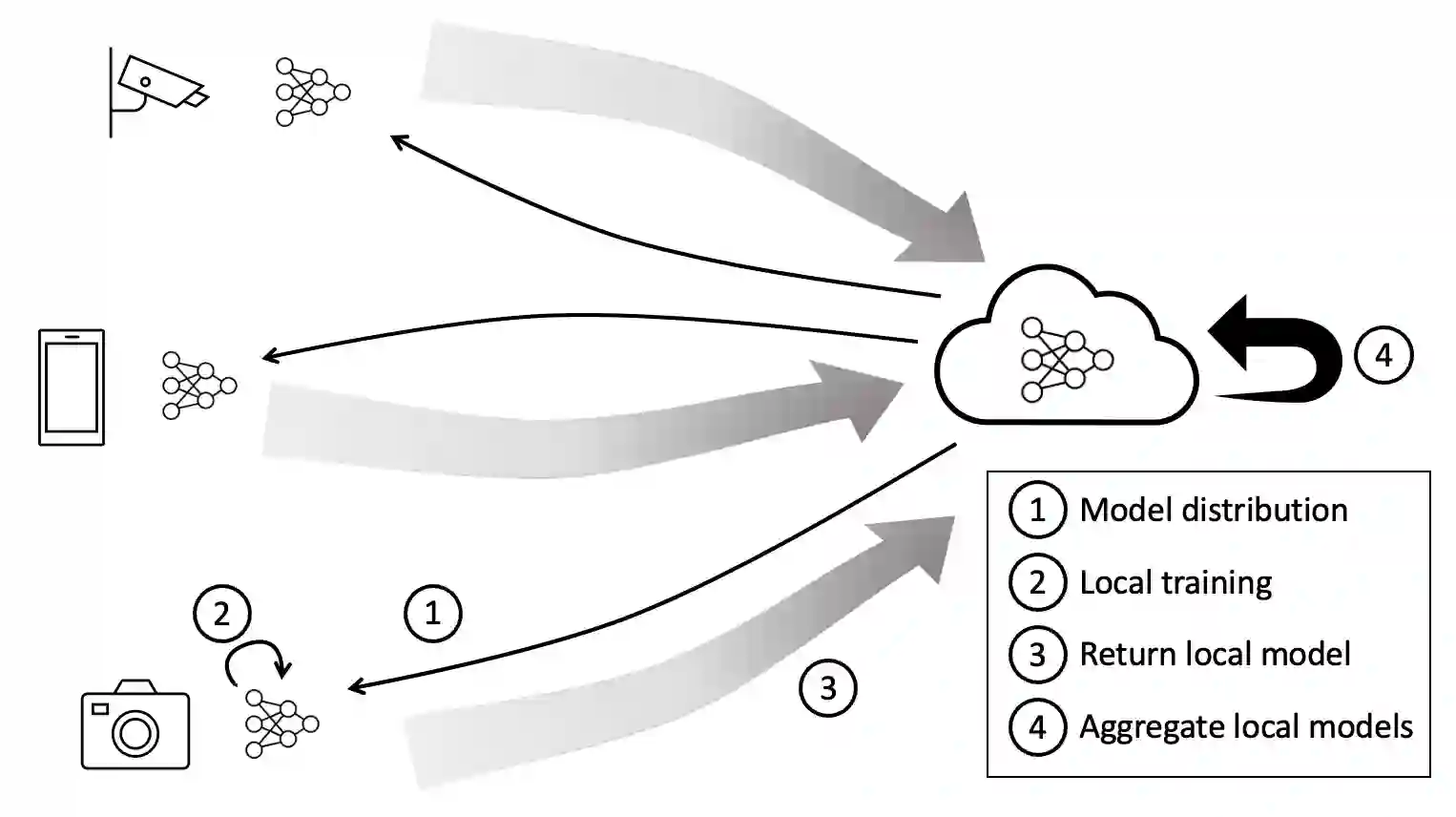
Federated Learning offers a way to train deep neural networks in a distributed fashion. While this addresses limitations related to distributed data, it incurs a communication overhead as the model parameters or gradients need to be exchanged regularly during training. This can be an issue with large scale distribution of learning asks and negate the benefit of the respective resource distribution. In this paper, we we propose to utilise parallel Adapters for Federated Learning. Using various datasets, we show that Adapters can be applied with different Federated Learning techniques. We highlight that our approach can achieve similar inference performance compared to training the full model while reducing the communication overhead drastically. We further explore the applicability of Adapters in cross-silo and cross-device settings, as well as different non-IID data distributions.
翻译:联邦学习提供了一种分布式训练深度神经网络的方法。虽然解决了分布式数据相关的局限性,但在训练过程中需要定期交换模型参数或梯度,导致了通信开销。这在大规模分布式学习任务中可能成为问题,并抵消相应资源分布的优势。本文提出利用并行适配器(Adapters)进行联邦学习。通过多种数据集,我们证明了适配器可适用于不同的联邦学习技术。我们强调,与训练完整模型相比,我们的方法在显著降低通信开销的同时,能达到相似的推理性能。我们进一步探索了适配器在跨组织(cross-silo)和跨设备(cross-device)设置下的适用性,以及针对不同非独立同分布(non-IID)数据分布的表现。