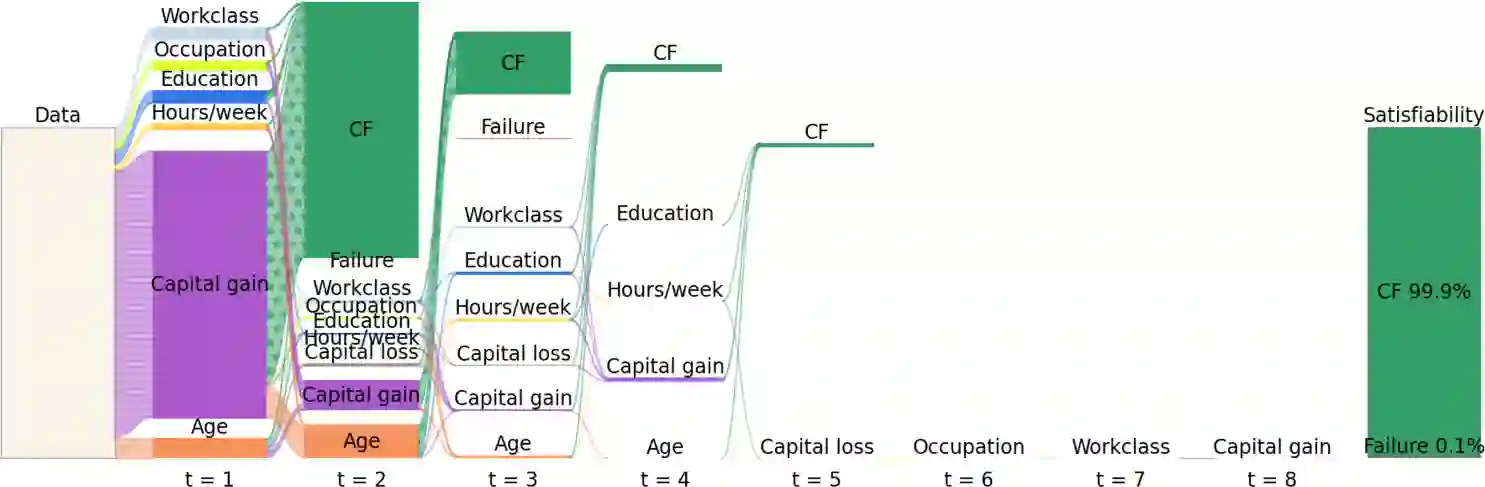
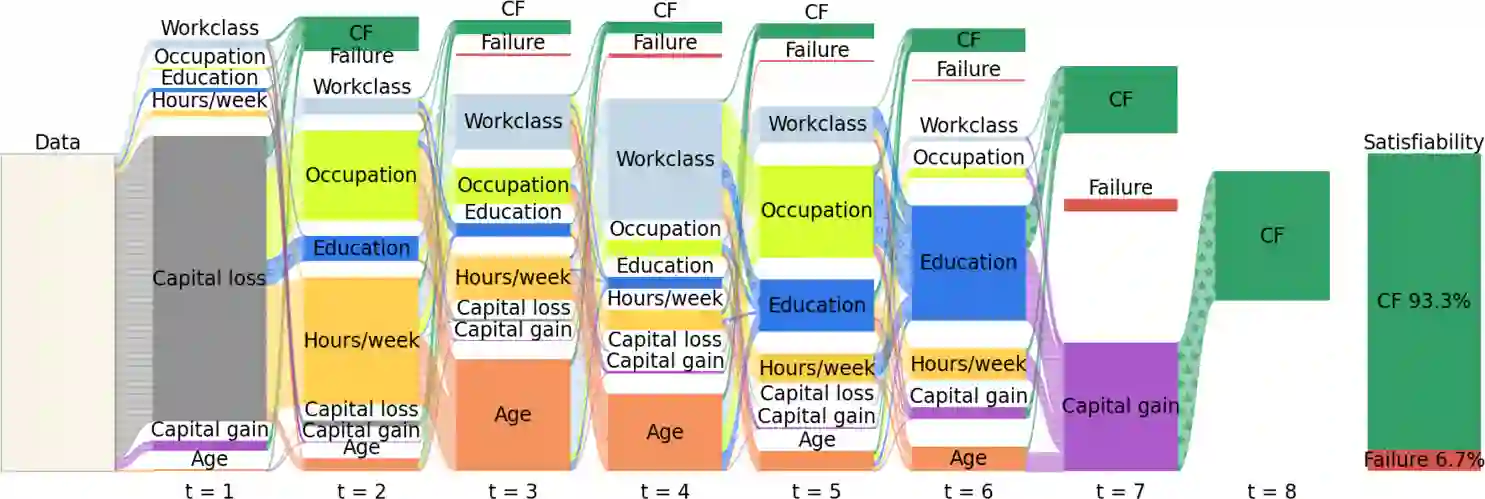
In the field of explainable Artificial Intelligence (XAI), sequential counterfactual (SCF) examples are often used to alter the decision of a trained classifier by implementing a sequence of modifications to the input instance. Although certain test-time algorithms aim to optimize for each new instance individually, recently Reinforcement Learning (RL) methods have been proposed that seek to learn policies for discovering SCFs, thereby enhancing scalability. As is typical in RL, the formulation of the RL problem, including the specification of state space, actions, and rewards, can often be ambiguous. In this work, we identify shortcomings in existing methods that can result in policies with undesired properties, such as a bias towards specific actions. We propose to use the output probabilities of the classifier to create a more informative reward, to mitigate this effect.
翻译:在可解释人工智能(XAI)领域,序列反事实(SCF)示例常通过对输入实例实施一系列修改来改变训练分类器的决策。尽管某些测试时算法旨在针对每个新实例单独优化,但近期提出的强化学习(RL)方法旨在学习发现SCF的策略,从而提升可扩展性。按照RL的典型范式,问题构建(包括状态空间、动作和奖励的设定)往往具有模糊性。本工作识别出现有方法的缺陷,这些缺陷可能导致策略产生不期望的属性(例如对特定动作的偏好)。我们提出利用分类器的输出概率构建更具信息量的奖励,以缓解这一影响。