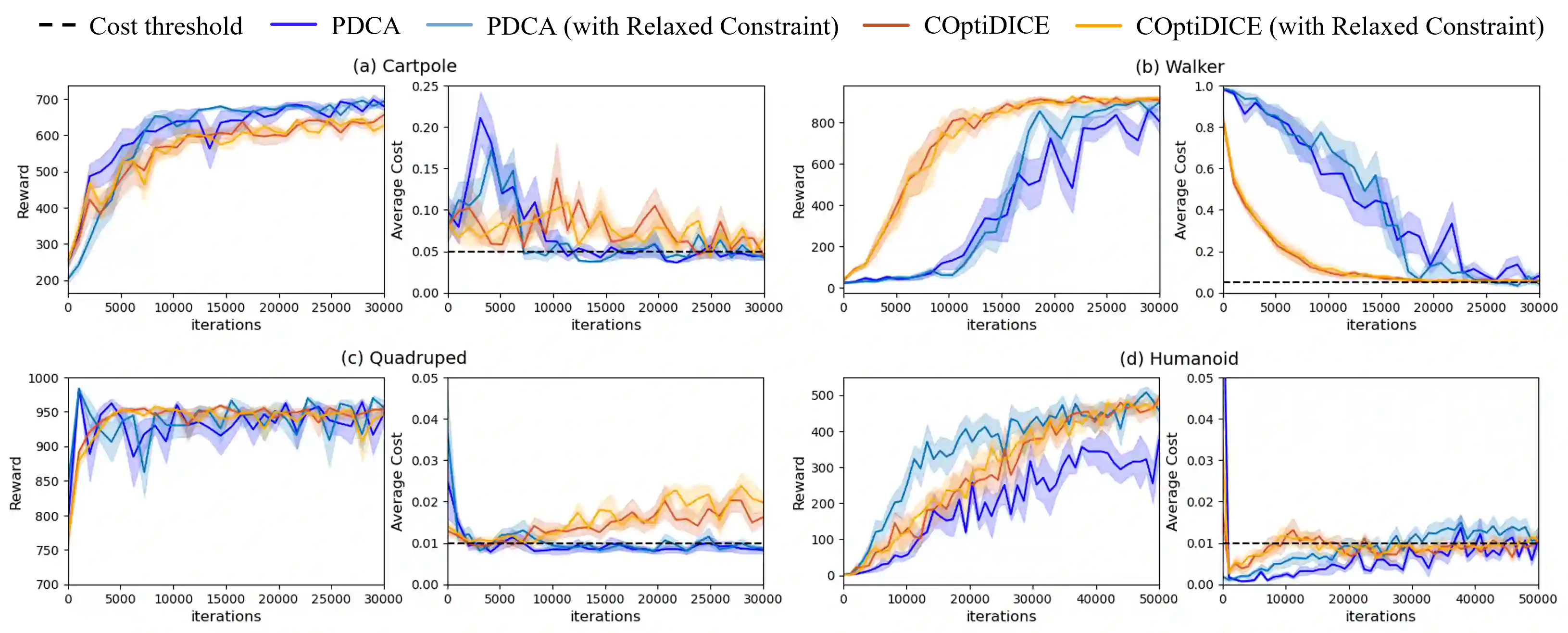
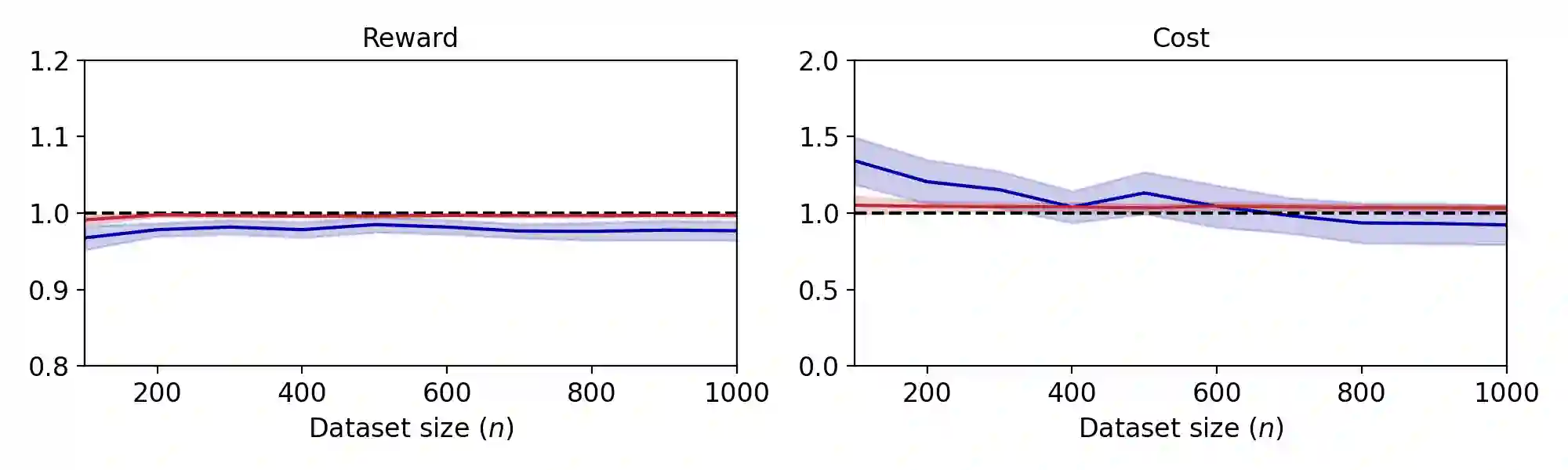
Offline constrained reinforcement learning (RL) aims to learn a policy that maximizes the expected cumulative reward subject to constraints on expected value of cost functions using an existing dataset. In this paper, we propose Primal-Dual-Critic Algorithm (PDCA), a novel algorithm for offline constrained RL with general function approximation. PDCA runs a primal-dual algorithm on the Lagrangian function estimated by critics. The primal player employs a no-regret policy optimization oracle to maximize the Lagrangian estimate given any choices of the critics and the dual player. The dual player employs a no-regret online linear optimization oracle to minimize the Lagrangian estimate given any choices of the critics and the primal player. We show that PDCA can successfully find a near saddle point of the Lagrangian, which is nearly optimal for the constrained RL problem. Unlike previous work that requires concentrability and strong Bellman completeness assumptions, PDCA only requires concentrability and value function/marginalized importance weight realizability assumptions.
翻译:离线约束强化学习旨在利用现有数据集,学习一个策略,在满足成本函数期望值约束的条件下,最大化期望累积奖励。本文提出了一种新颖的算法——原始-对偶-评论家算法(PDCA),该算法适用于通用函数逼近的离线约束强化学习。PDCA在由评论家估计的拉格朗日函数上执行原始-对偶算法。原始玩家采用无遗憾策略优化预言机,在给定评论家和对偶玩家任意选择的情况下,最大化拉格朗日估计值;对偶玩家则采用无遗憾在线线性优化预言机,在给定评论家和原始玩家任意选择的情况下,最小化拉格朗日估计值。我们证明,PDCA能成功逼近拉格朗日函数的近似鞍点,这对于约束强化学习问题而言几乎是最优的。与先前需要可集中性和强贝尔曼完备性假设的工作不同,PDCA仅需要可集中性以及价值函数/边际化重要性权重的可实现性假设。