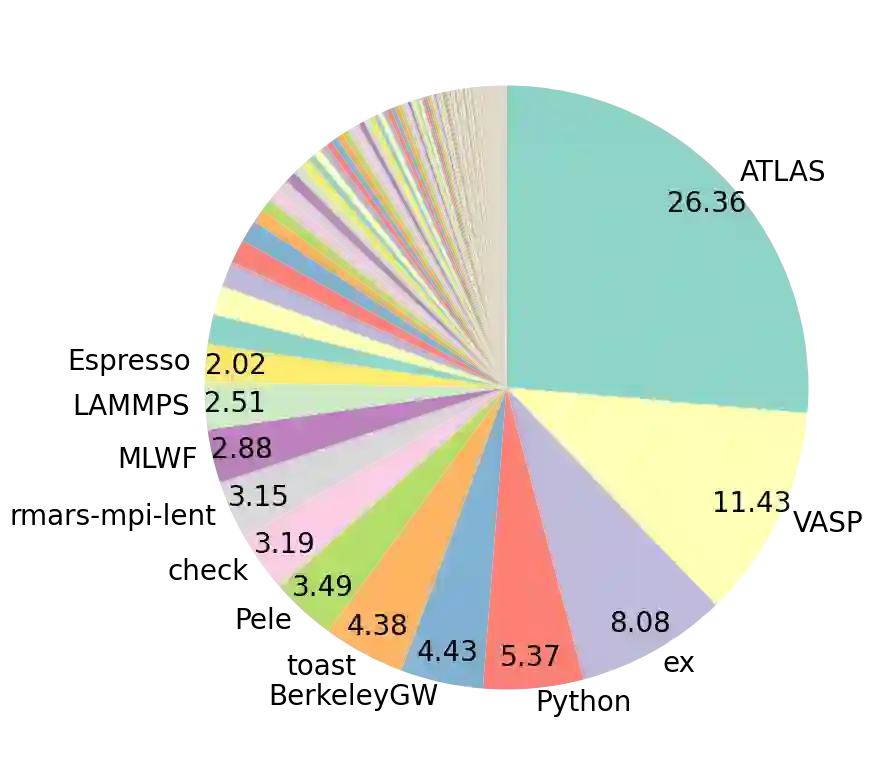
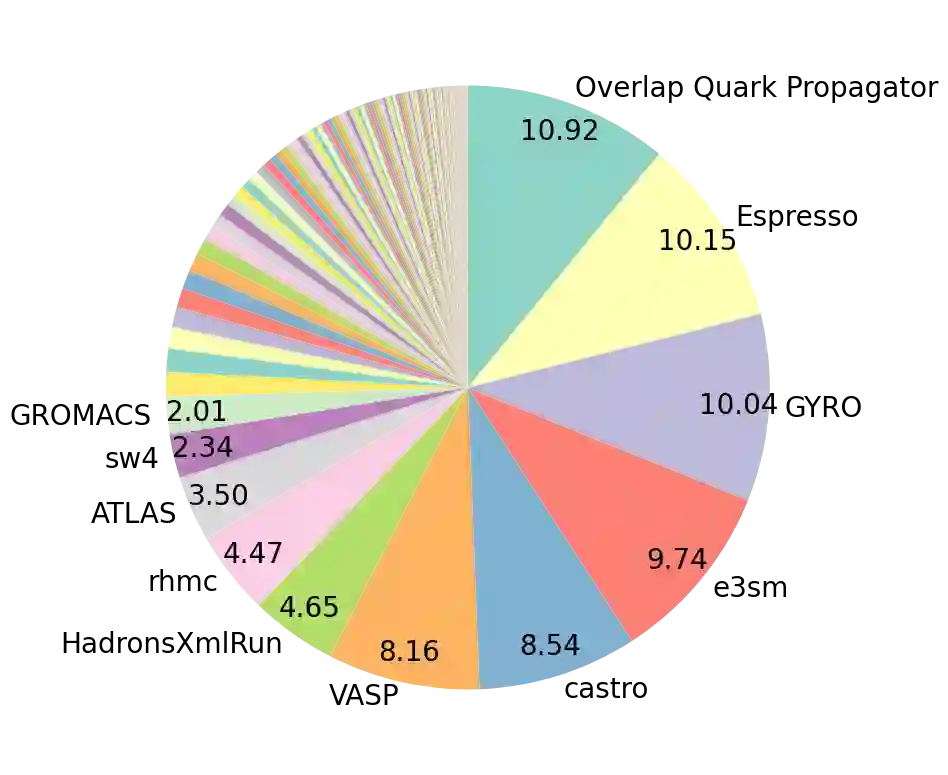
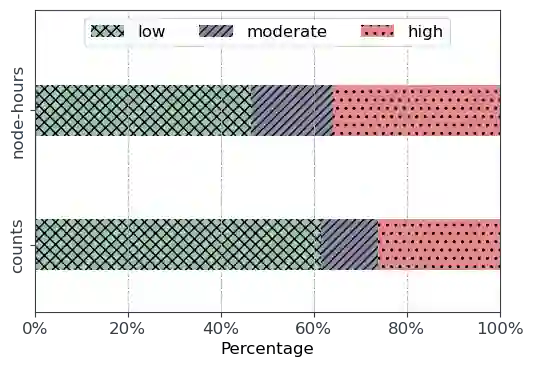
Resource demands of HPC applications vary significantly. However, it is common for HPC systems to primarily assign resources on a per-node basis to prevent interference from co-located workloads. This gap between the coarse-grained resource allocation and the varying resource demands can lead to HPC resources being not fully utilized. In this study, we analyze the resource usage and application behavior of NERSC's Perlmutter, a state-of-the-art open-science HPC system with both CPU-only and GPU-accelerated nodes. Our one-month usage analysis reveals that CPUs are commonly not fully utilized, especially for GPU-enabled jobs. Also, around 64% of both CPU and GPU-enabled jobs used 50% or less of the available host memory capacity. Additionally, about 50% of GPU-enabled jobs used up to 25% of the GPU memory, and the memory capacity was not fully utilized in some ways for all jobs. While our study comes early in Perlmutter's lifetime thus policies and application workload may change, it provides valuable insights on performance characterization, application behavior, and motivates systems with more fine-grain resource allocation.
翻译:HPC应用的资源需求差异显著。然而,HPC系统通常以节点为单位分配资源以避免共存工作负载的干扰。这种粗粒度资源分配与可变资源需求之间的差距可能导致HPC资源未被充分利用。本研究分析了NERSC Perlmutter(一个兼具纯CPU节点与GPU加速节点的先进开放科学HPC系统)的资源使用情况与应用行为。为期一个月的使用分析表明:CPU普遍未被充分利用,尤其在GPU作业中;约64%的纯CPU作业与GPU作业使用了不超过50%的可用主机内存容量;此外,约50%的GPU作业仅使用了不超过25%的GPU显存,所有作业的显存容量均未得到充分利用。尽管本研究开展于Perlmutter系统运行初期,相关策略与应用负载可能发生变化,但研究结果为性能表征与应用行为分析提供了宝贵见解,并为支持更细粒度资源分配的系统设计提供了依据。