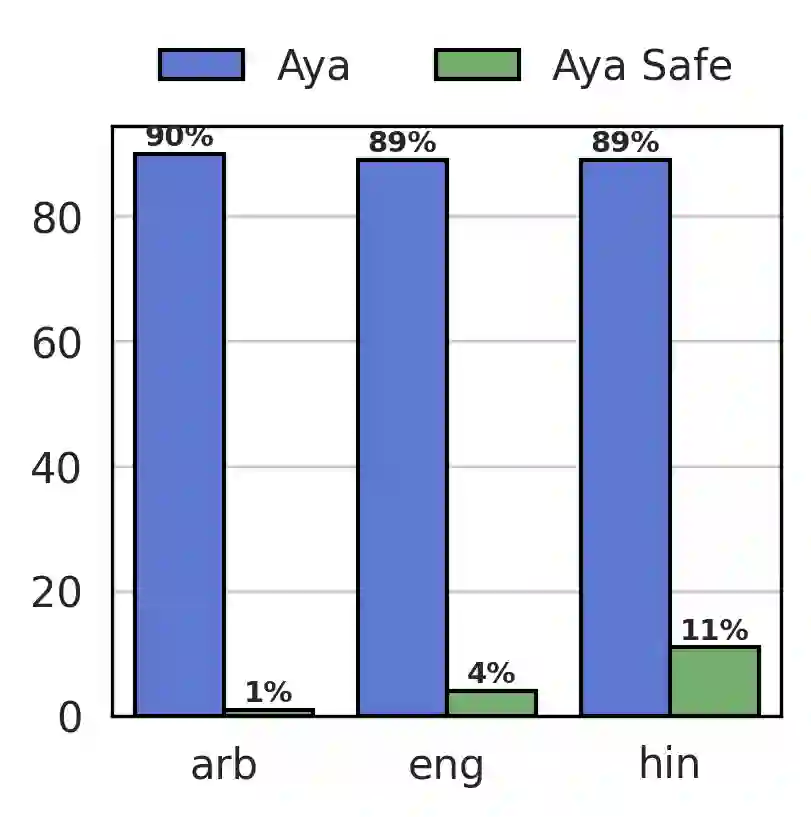
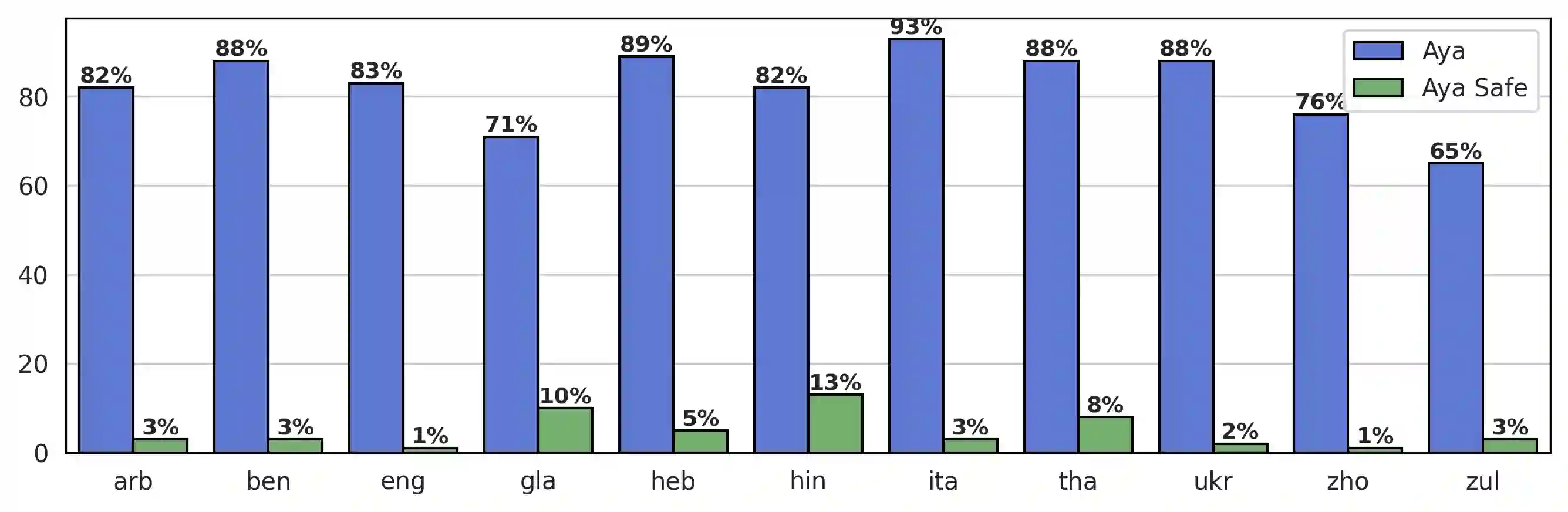
Recent breakthroughs in large language models (LLMs) have centered around a handful of data-rich languages. What does it take to broaden access to breakthroughs beyond first-class citizen languages? Our work introduces Aya, a massively multilingual generative language model that follows instructions in 101 languages of which over 50% are considered as lower-resourced. Aya outperforms mT0 and BLOOMZ on the majority of tasks while covering double the number of languages. We introduce extensive new evaluation suites that broaden the state-of-art for multilingual eval across 99 languages -- including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance. Furthermore, we conduct detailed investigations on the optimal finetuning mixture composition, data pruning, as well as the toxicity, bias, and safety of our models. We open-source our instruction datasets and our model at https://hf.co/CohereForAI/aya-101
翻译:大型语言模型(LLMs)的最新突破主要集中在少数数据丰富的语言上。如何将突破性成果扩展到非主流语言之外?我们的工作推出了Aya,一个大规模多语言生成式语言模型,能够在101种语言中执行指令,其中超过50%被视为低资源语言。Aya在大多数任务上优于mT0和BLOOMZ,同时覆盖的语言数量翻倍。我们引入了广泛的新评估套件,将多语言评估的最新技术扩展到99种语言——包括判别式与生成式任务、人工评估以及模拟胜率,这些评估涵盖了保留任务和分布内性能。此外,我们对最优微调混合组成、数据修剪以及模型的毒性、偏见和安全性进行了详细研究。我们开源了指令数据集和模型,地址为https://hf.co/CohereForAI/aya-101