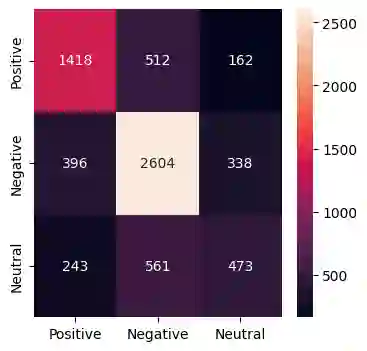
Bangla is the 7th most widely spoken language globally, with a staggering 234 million native speakers primarily hailing from India and Bangladesh. This morphologically rich language boasts a rich literary tradition, encompassing diverse dialects and language-specific challenges. Despite its linguistic richness and history, Bangla remains categorized as a low-resource language within the natural language processing (NLP) and speech community. This paper presents our submission to Task 2 (Sentiment Analysis of Bangla Social Media Posts) of the BLP Workshop. We experiment with various Transformer-based architectures to solve this task. Our quantitative results show that transfer learning really helps in better learning of the models in this low-resource language scenario. This becomes evident when we further finetune a model which has already been finetuned on twitter data for sentiment analysis task and that finetuned model performs the best among all other models. We also perform a detailed error analysis where we find some instances where ground truth labels need to be relooked at. We obtain a micro-F1 of 67.02\% on the test set and our performance in this shared task is ranked at 21 in the leaderboard.
翻译:孟加拉语是全球第七大广泛使用的语言,拥有来自印度和孟加拉国的约2.34亿母语使用者。这种形态丰富的语言拥有深厚的文学传统,包含多样的方言和特有的语言挑战。尽管其语言丰富性和历史底蕴深厚,孟加拉语在自然语言处理(NLP)和语音研究领域仍被归类为低资源语言。本文介绍了我们在BLP研讨会任务2(孟加拉语社交媒体帖子情感分析)中的研究成果。我们实验了多种基于Transformer的架构来解决该任务。定量结果表明,迁移学习在低资源语言场景中确实有助于模型更好地学习。这一点在以下过程中尤为明显:我们对已在推特数据上针对情感分析任务进行微调的模型进行进一步微调,该微调模型的性能在所有模型中表现最佳。我们还进行了详细的错误分析,发现部分案例中的真实标签需要重新审视。我们在测试集上获得了67.02%的微F1分数,并在本次共享任务的排行榜上排名第21位。