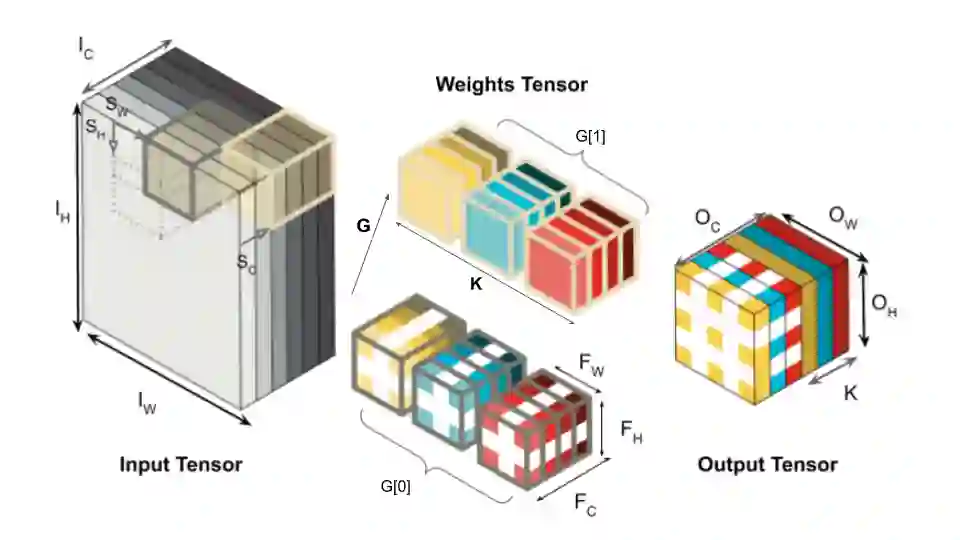
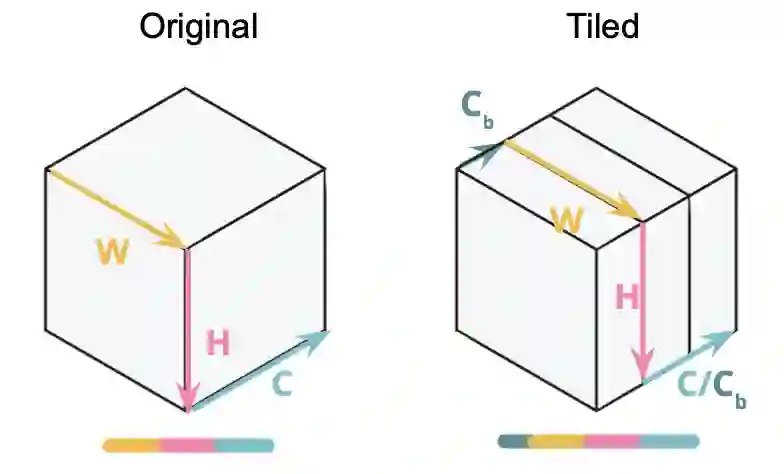
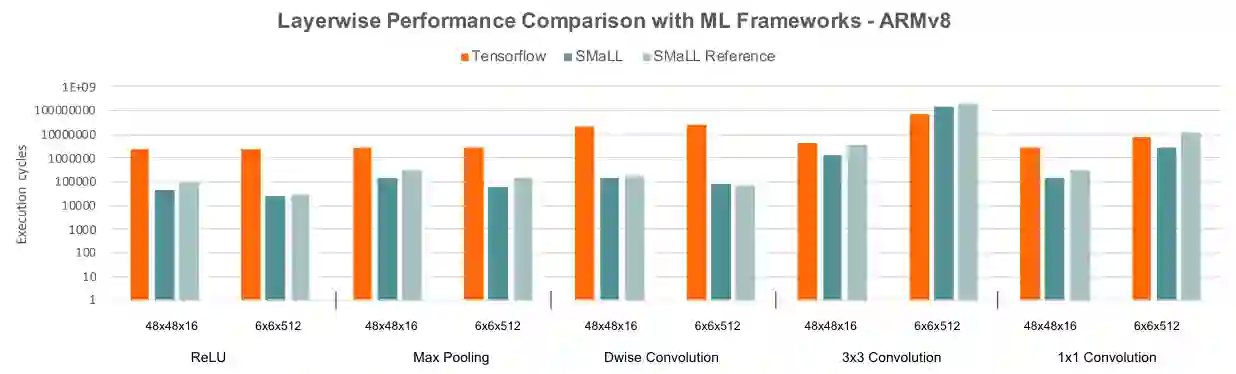
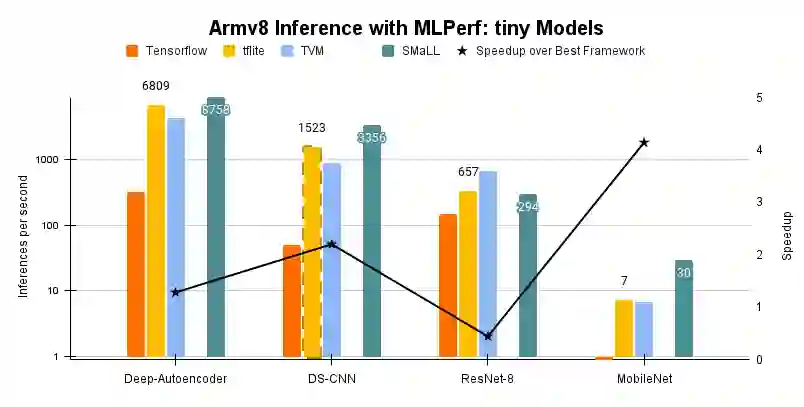
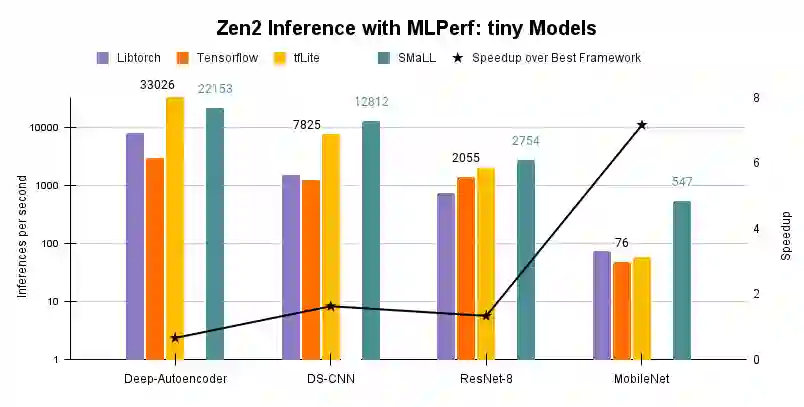
Interest in deploying Deep Neural Network (DNN) inference on edge devices has resulted in an explosion of the number and types of hardware platforms to use. While the high-level programming interface, such as TensorFlow, can be readily ported across different devices, high-performance inference implementations rely on a good mapping of the high-level interface to the target hardware platform. Commonly, this mapping may use optimizing compilers to generate code at compile time or high-performance vendor libraries that have been specialized to the target platform. Both approaches rely on expert knowledge to produce the mapping, which may be time-consuming and difficult to extend to new architectures. In this work, we present a DNN library framework, SMaLL, that is easily extensible to new architectures. The framework uses a unified loop structure and shared, cache-friendly data format across all intermediate layers, eliminating the time and memory overheads incurred by data transformation between layers. Layers are implemented by simply specifying the layer's dimensions and a kernel -- the key computing operations of each layer. The unified loop structure and kernel abstraction allows us to reuse code across layers and computing platforms. New architectures only require the 100s of lines in the kernel to be redesigned. To show the benefits of our approach, we have developed software that supports a range of layer types and computing platforms, which is easily extensible for rapidly instantiating high performance DNN libraries. We evaluate our software by instantiating networks from the TinyMLPerf benchmark suite on 5 ARM platforms and 1 x86 platform ( an AMD Zen 2). Our framework shows end-to-end performance that is comparable to or better than ML Frameworks such as TensorFlow, TVM and LibTorch.
翻译:摘要:在边缘设备上部署深度神经网络推理的需求,导致可使用的硬件平台数量和类型激增。尽管TensorFlow等高级编程接口可便捷地移植到不同设备,但高性能推理实现仍需依赖高级接口与目标硬件平台间的良好映射。通常,这种映射会采用优化编译器在编译时生成代码,或针对目标平台进行特化的高性能供应商库。两种方法均需专家知识来构建映射,这可能耗时且难以扩展至新架构。本文提出一种易扩展至新架构的DNN库框架SMaLL。该框架在所有中间层采用统一循环结构和共享的缓存友好数据格式,消除了层间数据转换带来的时间和内存开销。各层仅需通过指定层的维度与核函数(每层核心计算操作)即可实现。统一的循环结构与核抽象使得我们能够在不同层和计算平台间复用代码。新架构仅需重新设计约百行核函数代码。为展示本方法的优势,我们开发了支持多种层类型和计算平台的软件,且该软件易于扩展以快速实例化高性能DNN库。我们在5个ARM平台和1个x86平台(AMD Zen 2)上通过TinyMLPerf基准套件实例化网络来评估软件性能。实验表明,本框架的端到端性能可与TensorFlow、TVM及LibTorch等ML框架相当或更优。