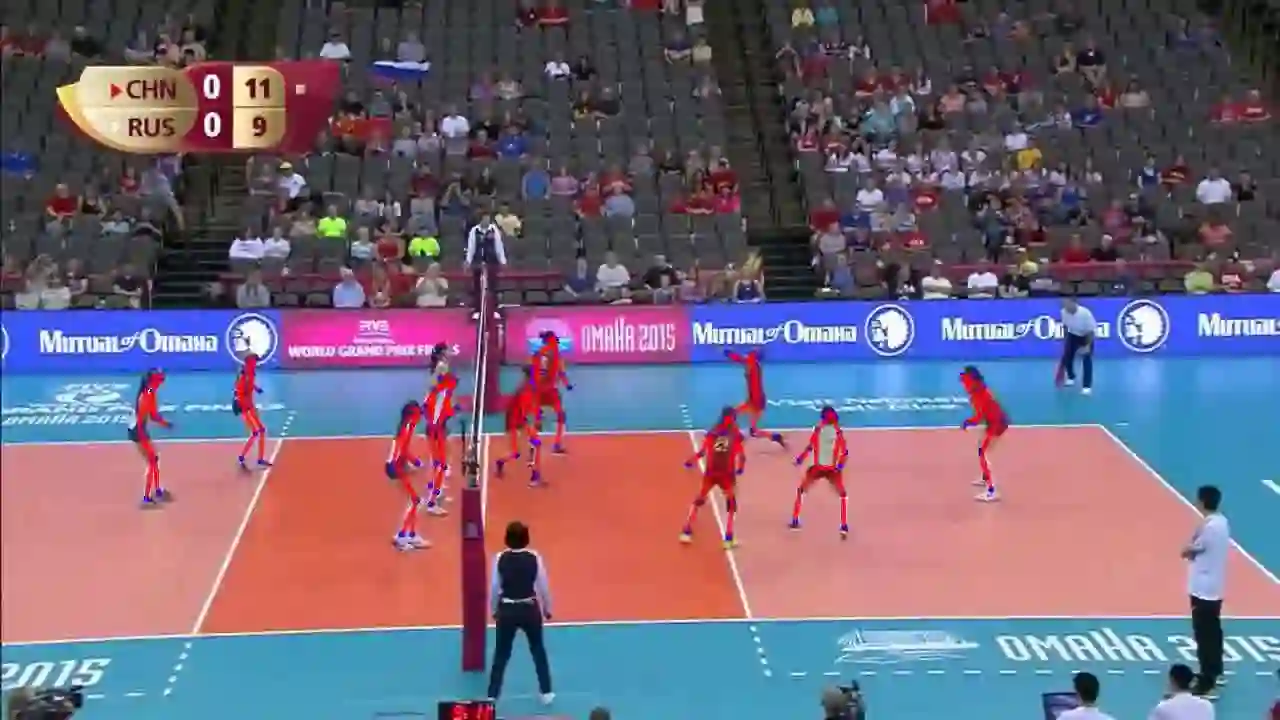
We present SkeleTR, a new framework for skeleton-based action recognition. In contrast to prior work, which focuses mainly on controlled environments, we target more general scenarios that typically involve a variable number of people and various forms of interaction between people. SkeleTR works with a two-stage paradigm. It first models the intra-person skeleton dynamics for each skeleton sequence with graph convolutions, and then uses stacked Transformer encoders to capture person interactions that are important for action recognition in general scenarios. To mitigate the negative impact of inaccurate skeleton associations, SkeleTR takes relative short skeleton sequences as input and increases the number of sequences. As a unified solution, SkeleTR can be directly applied to multiple skeleton-based action tasks, including video-level action classification, instance-level action detection, and group-level activity recognition. It also enables transfer learning and joint training across different action tasks and datasets, which result in performance improvement. When evaluated on various skeleton-based action recognition benchmarks, SkeleTR achieves the state-of-the-art performance.
翻译:我们提出SkeleTR,一种用于基于骨架的动作识别的新框架。与主要关注受控环境的先前工作不同,我们针对更通用的场景,这些场景通常涉及可变人数以及人与人之间的各种交互形式。SkeleTR采用两阶段范式。首先,它利用图卷积为每个骨架序列建模人体内部骨架动态,然后使用堆叠的Transformer编码器捕获对通用场景中动作识别至关重要的人体交互。为了减轻不准确的骨架关联带来的负面影响,SkeleTR以相对较短的骨架序列作为输入并增加序列数量。作为一种统一解决方案,SkeleTR可直接应用于多种基于骨架的动作任务,包括视频级动作分类、实例级动作检测和群体级活动识别。它还支持跨不同动作任务和数据集的迁移学习与联合训练,从而带来性能提升。在多种基于骨架的动作识别基准上进行评估时,SkeleTR实现了最先进的性能。