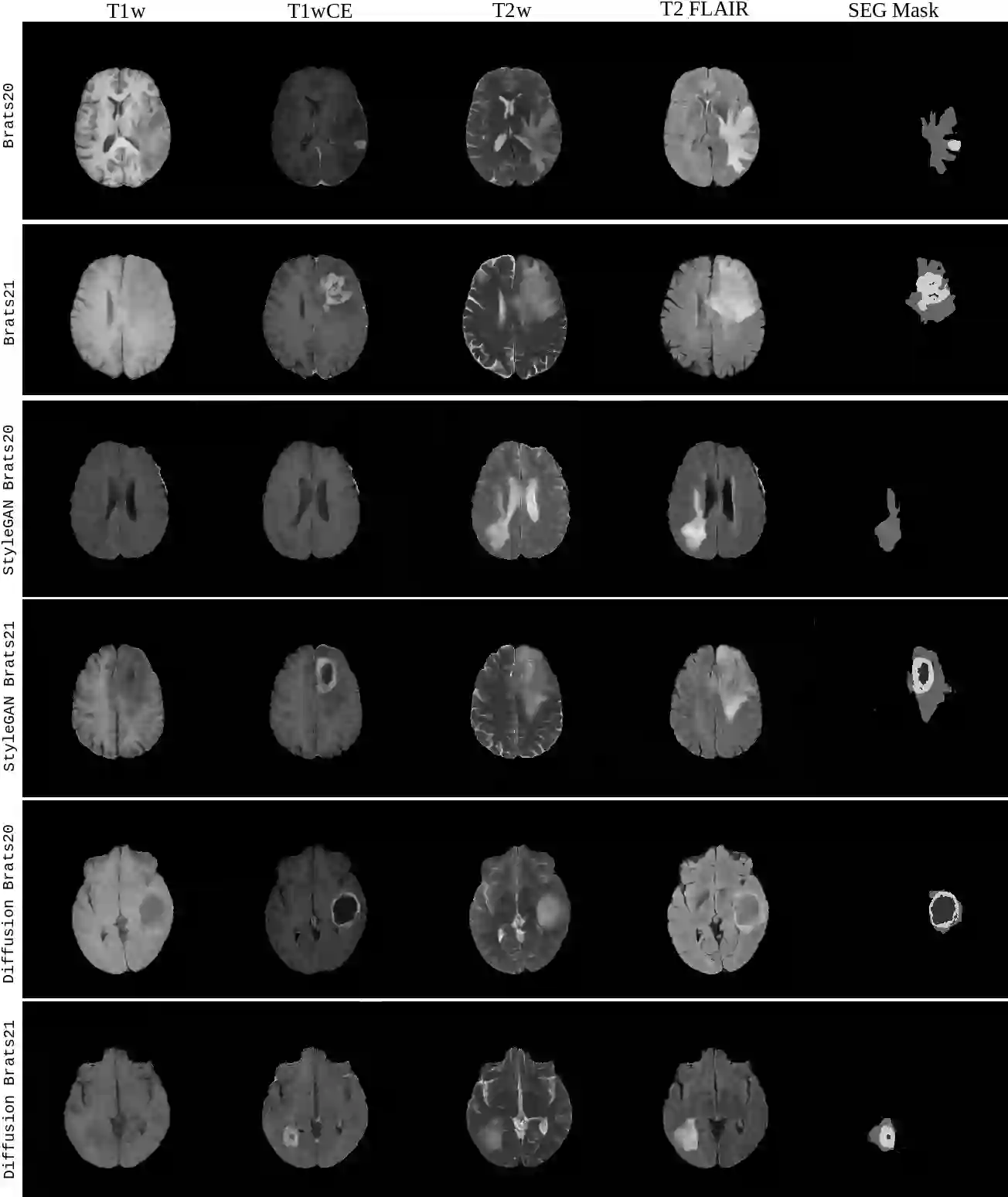
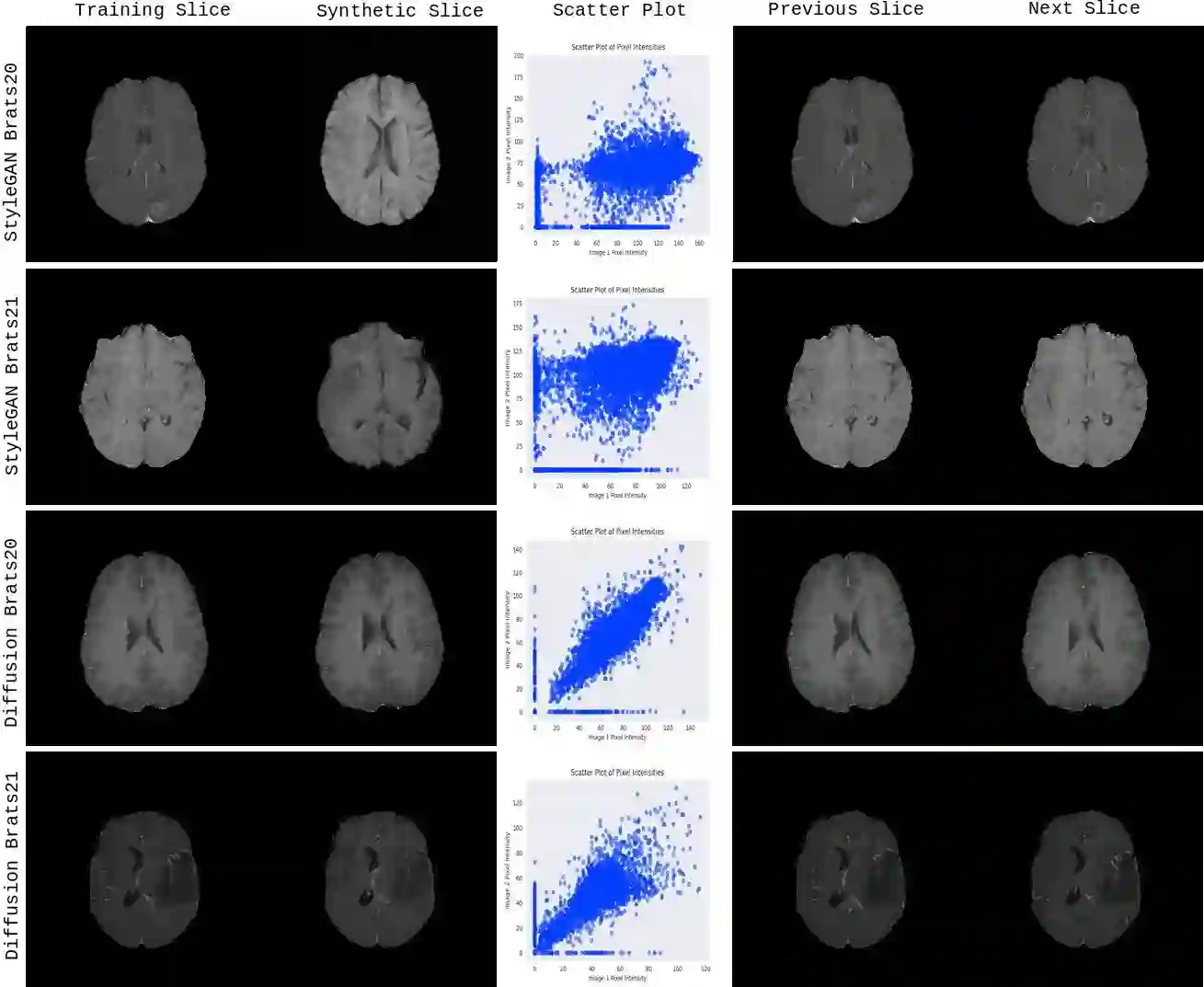
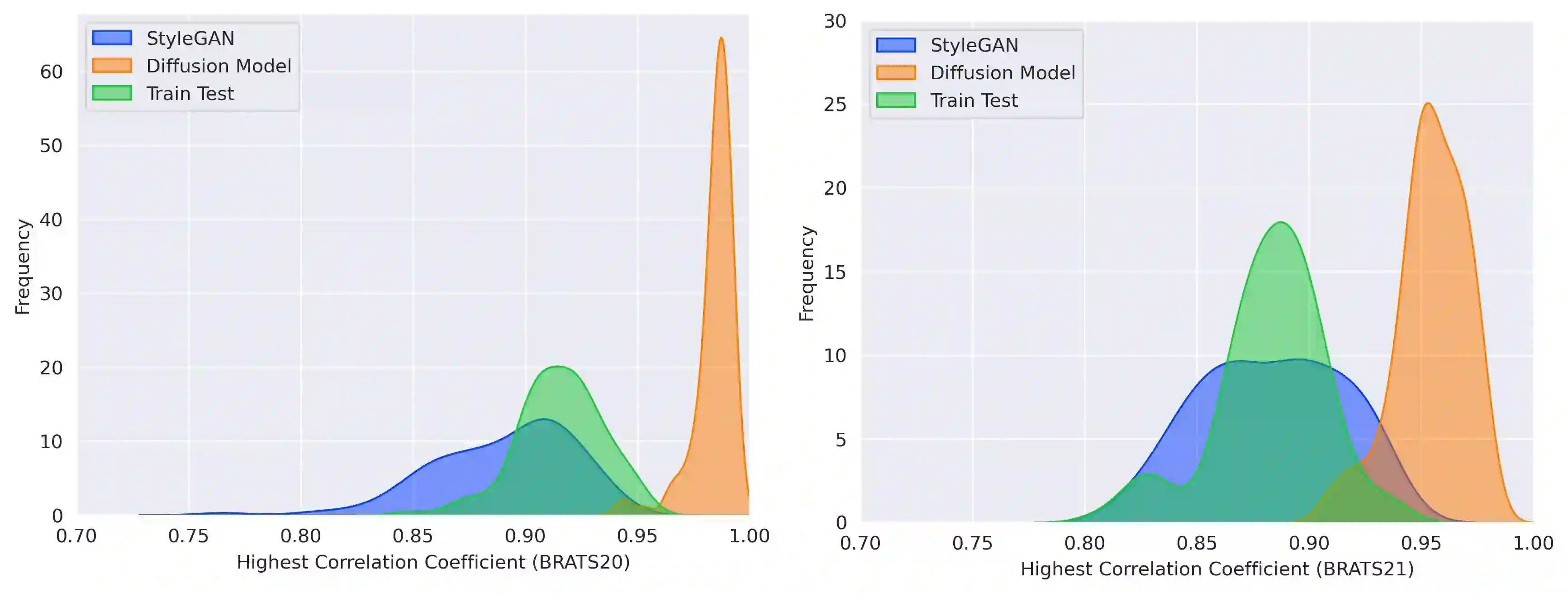
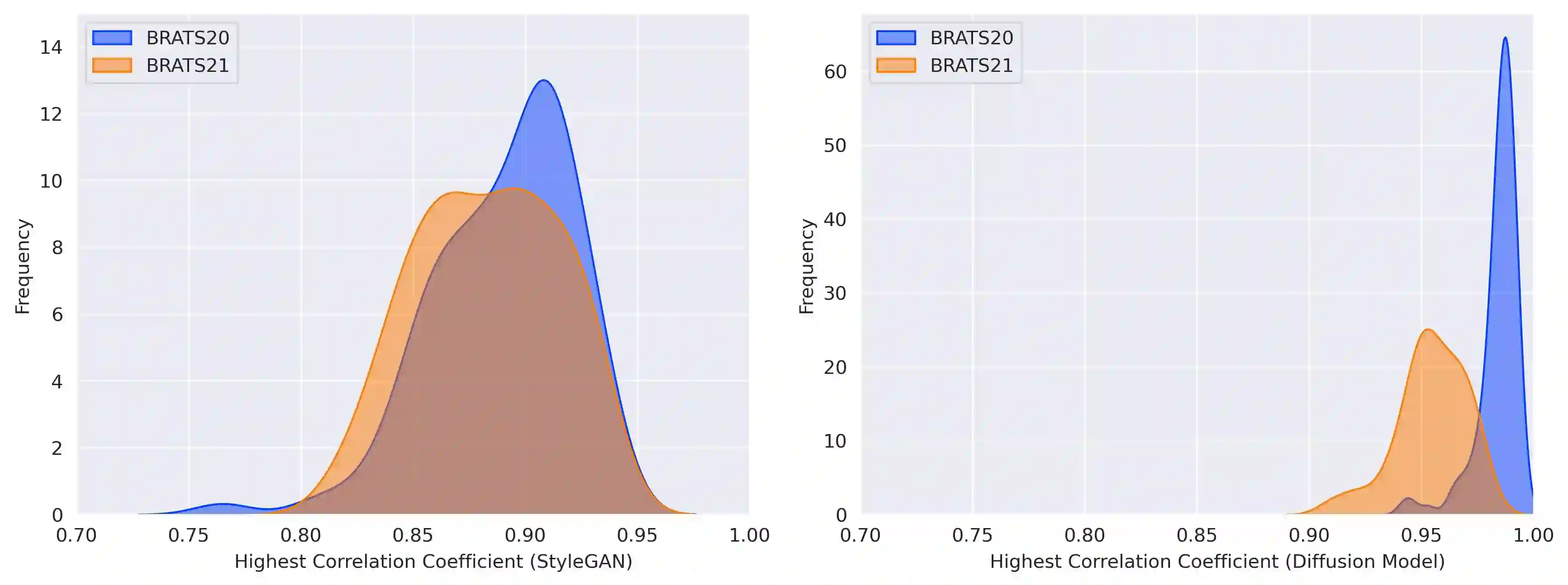
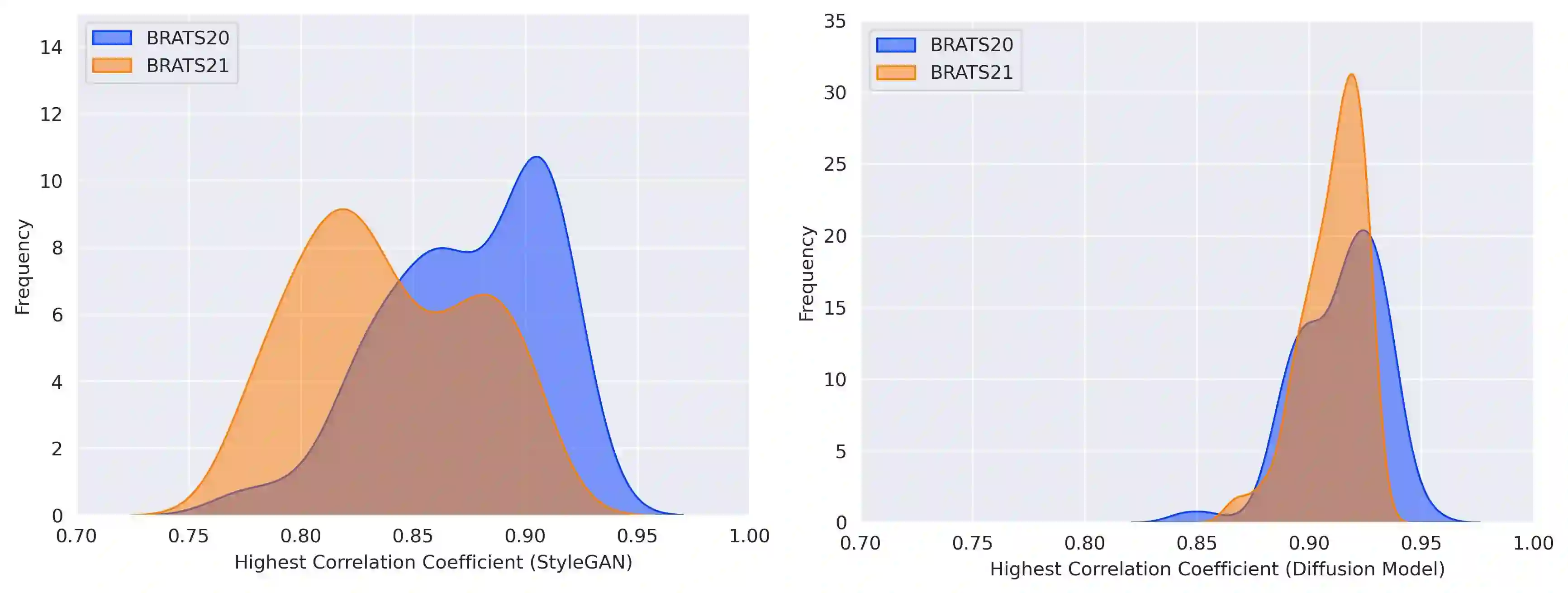
Diffusion models were initially developed for text-to-image generation and are now being utilized to generate high quality synthetic images. Preceded by GANs, diffusion models have shown impressive results using various evaluation metrics. However, commonly used metrics such as FID and IS are not suitable for determining whether diffusion models are simply reproducing the training images. Here we train StyleGAN and diffusion models, using BRATS20 and BRATS21 datasets, to synthesize brain tumor images, and measure the correlation between the synthetic images and all training images. Our results show that diffusion models are much more likely to memorize the training images, especially for small datasets. Researchers should be careful when using diffusion models for medical imaging, if the final goal is to share the synthetic images.
翻译:扩散模型最初是为文本到图像生成而开发的,目前正被用于生成高质量合成图像。在生成对抗网络(GANs)之后,扩散模型通过多种评估指标展现了令人瞩目的成果。然而,常用的FID和IS等评估指标并不适用于判断扩散模型是否仅仅在复现训练图像。本研究使用BRATS20和BRATS21数据集训练StyleGAN和扩散模型以合成脑肿瘤图像,并测量合成图像与全部训练图像之间的相关性。结果表明,扩散模型更倾向于记忆训练图像,尤其是在小数据集场景下。若最终目标是共享合成图像,研究者在使用扩散模型进行医学成像时应保持谨慎。